ノーコードでクラウド上のデータとの連携を実現。
詳細はこちら →Databricks SSIS Component の30日間無償トライアルをダウンロード
30日間の無償トライアルへ製品の詳細
SSIS ソース & デスティネーションコンポーネントは、SQL Server SSIS のワークフロー内で簡単にDatabricks 互換のデータベースエンジンに接続できる強力なツールです。
データフロー内のDatabricks コンポーネントを使ってDatabricks を同期できます。データ同期、ローカルバックアップ、ワークフローの自動化などに最適!
CData


こんにちは!ドライバー周りのヘルプドキュメントを担当している古川です。
SQL Server に基幹業務データのバックアップを保管しておくことは、ビジネス上のセーフティネットとなります。また、ユーザーはSQL Server のバックアップデータからレポーティングや分析を簡単に行うことができます。
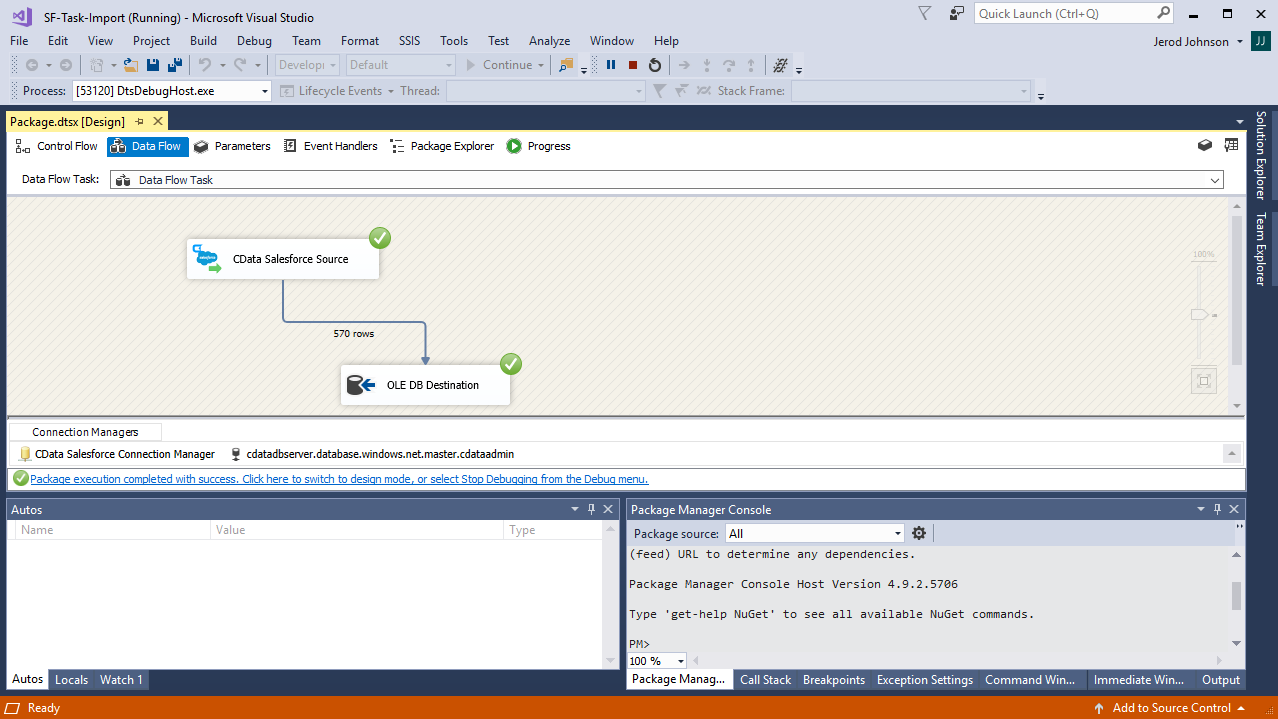
ここでは、SQL サーバー SSIS ワークフロー内でCData SSIS Tasks for Databricks を使用して、Databricks データをMicrosoft SQL Server データベースに転送する方法を説明します。
開始するには、新しいDatabricks ソースとSQL Server ADO.NET 転送先を新しいデータフロータスクに追加します。
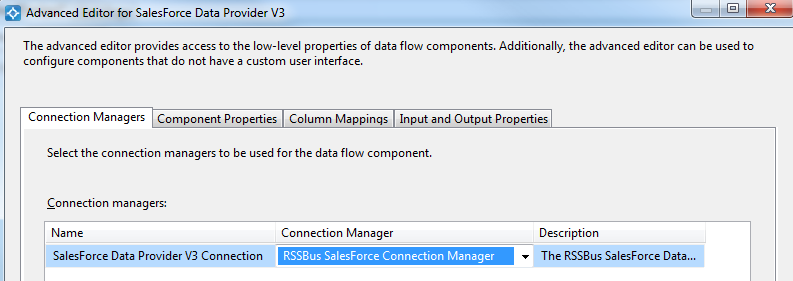
以下のステップに従って、接続マネジャーでDatabricks 接続プロパティを保存します。
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。
Note:Databricks インスタンスで必要な値は、クラスターに移動して目的のクラスターを選択し、Advanced Options の下にあるJDBC/ODBC タブを選択することで見つけることができます。
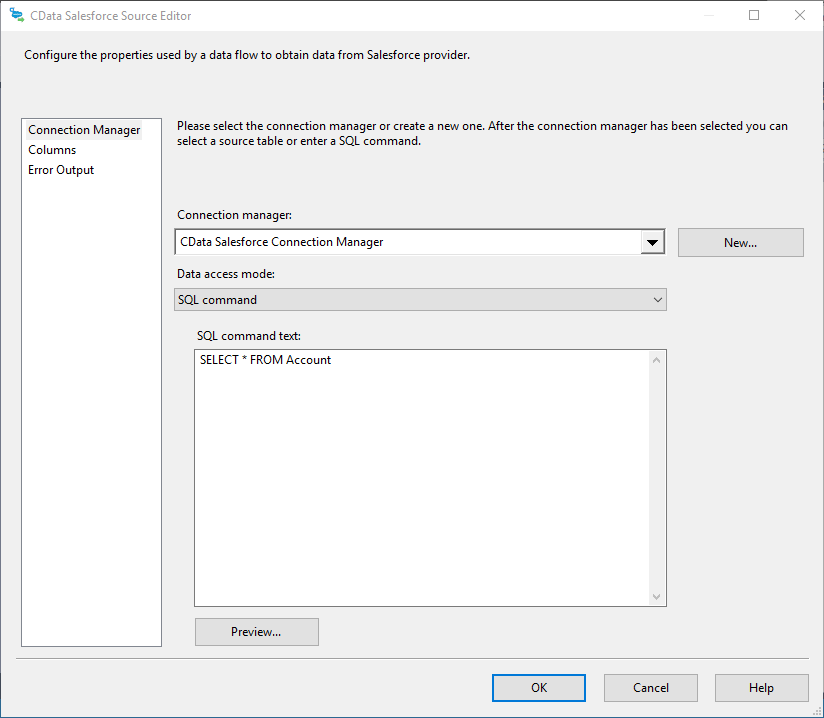
以下のステップに従って、Databricks の抽出に使用するクエリを指定します。
SELECT City, CompanyName FROM Customers WHERE Country = 'US'
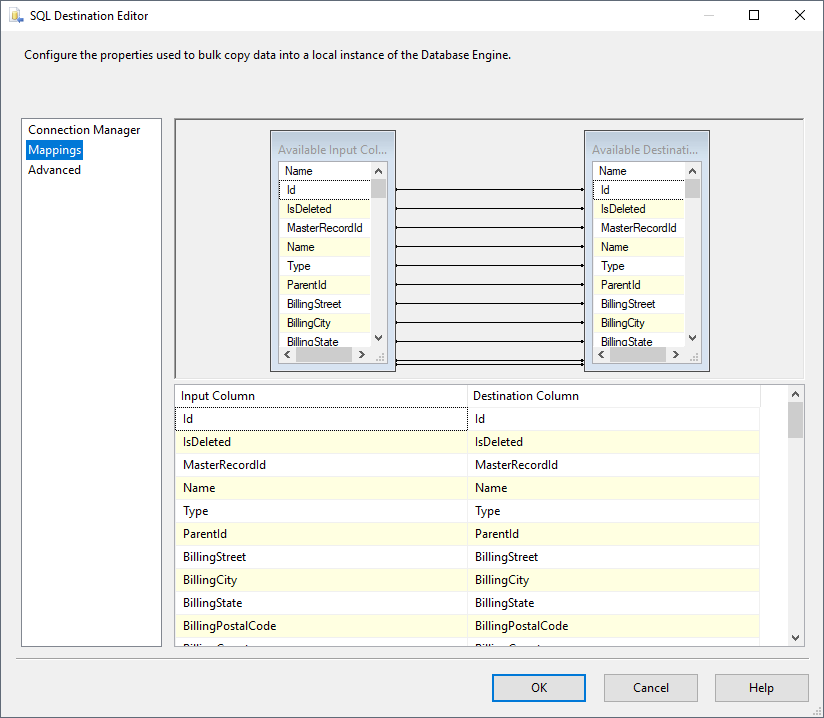
以下のステップに従って、Databricks をロードするSQL サーバーテーブルを指定します。
プロジェクトを実行できるようになりました。SSIS Task の実行が完了すると、データベースにDatabricks データが入力されます。