ノーコードでクラウド上のデータとの連携を実現。
詳細はこちら →Apache Hive ODBC Driver の30日間無償トライアルをダウンロード
30日間の無償トライアルへ製品の詳細
Hive ODBC Driver は、ODBC 接続をサポートする任意のアプリケーションからApache Hive データに直接接続できるパワフルなツールです。
ドライバーはSQL をHiveQL にマッピングして、標準SQL-92 で直接Apache Hive にアクセスできます。
こんにちは!ドライバー周りのヘルプドキュメントを担当している古川です。
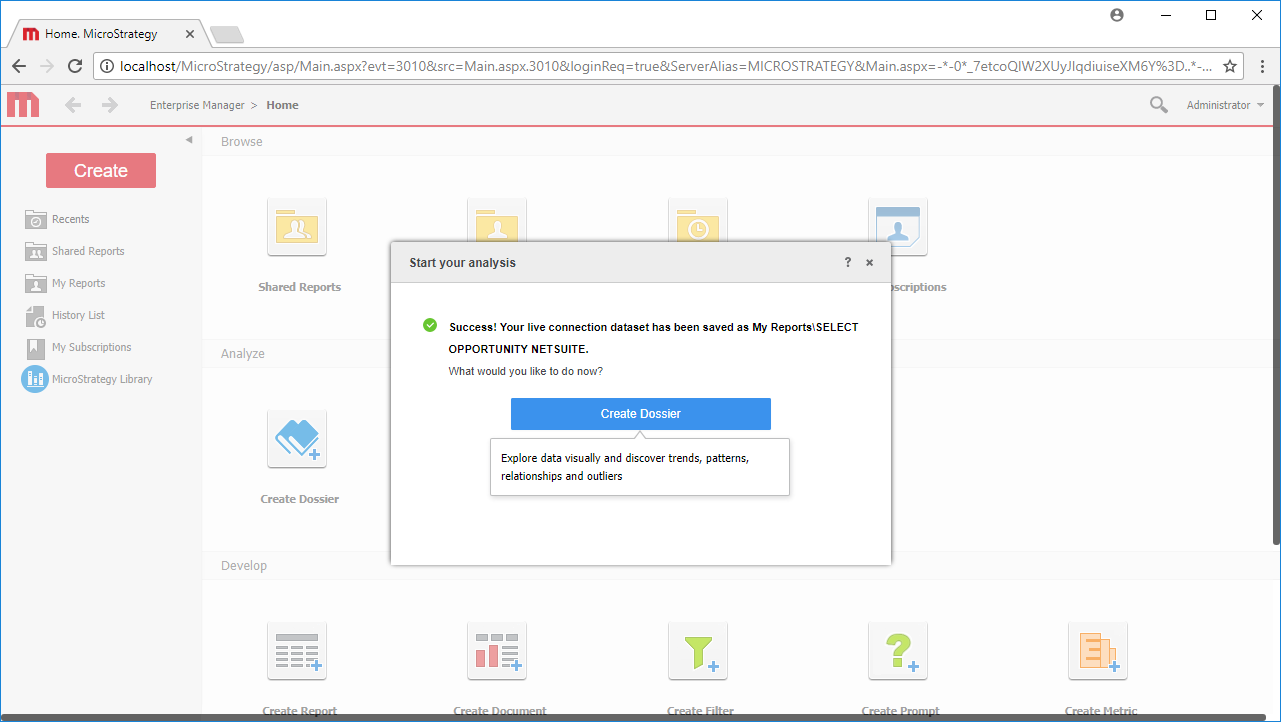
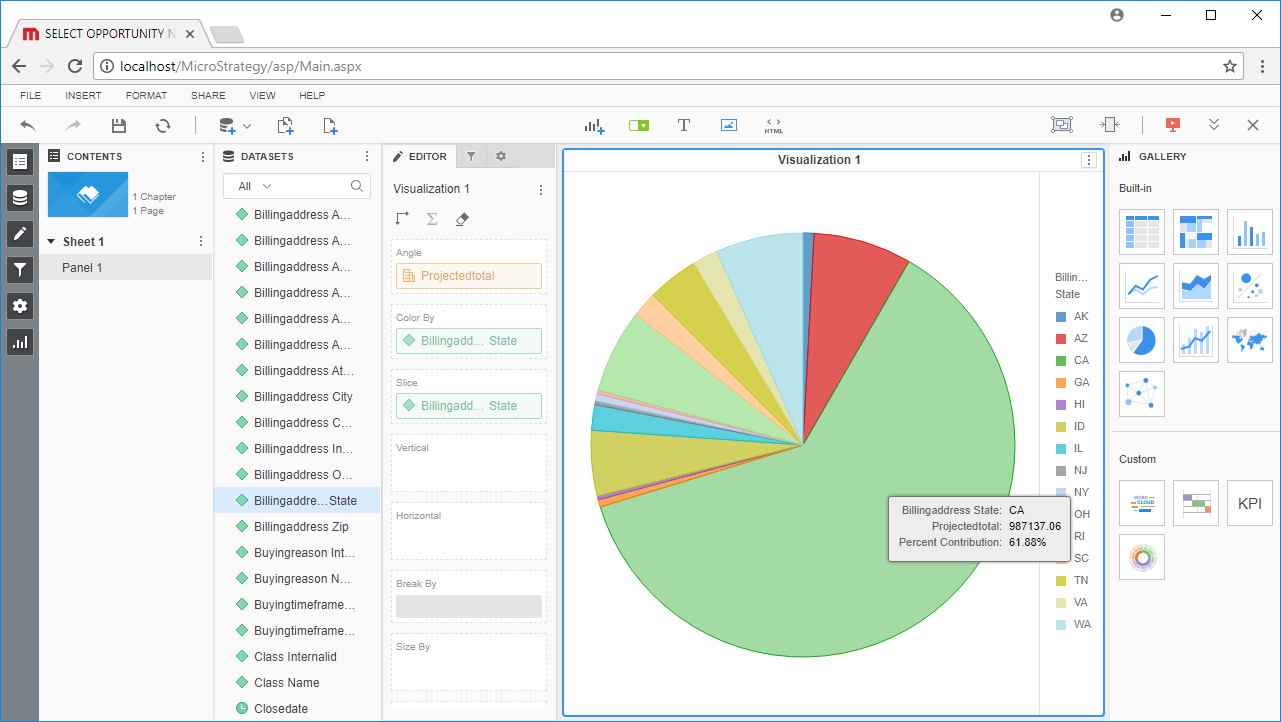
MicroStrategy は、データドリブンイノベーションを可能にする分析およびモバイルプラットフォームです。MicroStrategy とCData ODBC Driver for ApacheHive を組み合わせると、MicroStrategy からデータベースと同じ感覚でリアルタイムHive データにアクセスできるようになり、より高度なレポートと分析が行えます。この記事では、MicroStrategy Web に外部データとしてHive を追加し、Hive データの簡単なビジュアライゼーションを作成する方法について説明します。
CData ODBC ドライバーは、ドライバーに組み込みの最適化されたデータ処理により、MicroStrategy でリアルタイムHive データとやり取りする上で最高のパフォーマンスを提供します。MicroStrategy からHive に複雑なSQL クエリを発行すると、ドライバーはフィルタや集計などのサポートされているSQL 操作をHive に直接プッシュし、サポートされていない操作(主にSQL 関数とJOIN 操作)は、組み込みのSQL エンジンを利用してクライアント側で処理します。ビルトインの動的メタデータクエリを使用すると、ネイティブのMicroStrategy データ型を使用してHive データをビジュアライズおよび分析できます。
CData ODBC ドライバは、以下のような特徴を持ったリアルタイムデータ連携ソリューションです。
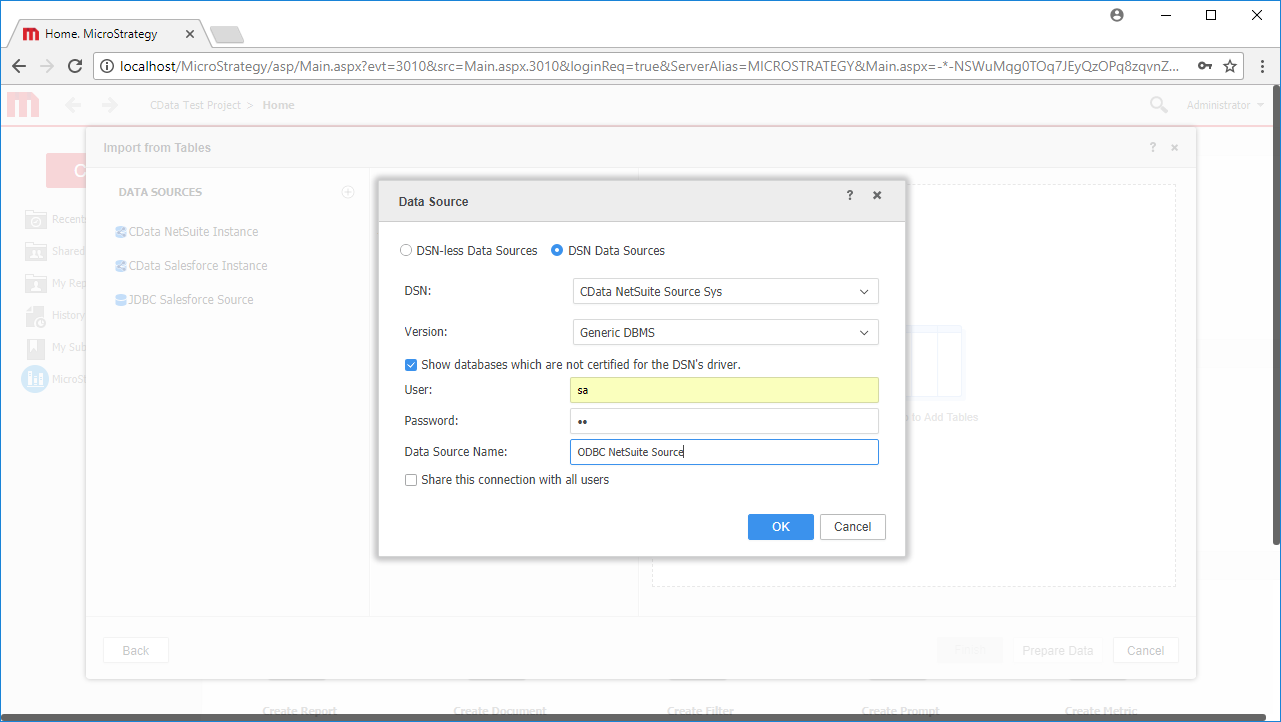
CData ODBC ドライバでは、1.データソースとしてHive の接続を設定、2.MicroStrategy Web 側でODBC Driver との接続を設定、という2つのステップだけでデータソースに接続できます。以下に具体的な設定手順を説明します。
まずは、本記事右側のサイドバーからApacheHive ODBC Driver の無償トライアルをダウンロード・インストールしてください。30日間無償で、製品版の全機能が使用できます。
Hive への接続に関する情報と、Windows およびLinux 環境でのDSN の設定手順を以下で説明します。(ODBC Driver for ApacheHive は、接続されたMicroStrategy Intelligence Server をホストしているマシンにインストールする必要があります。)
Apache Hive への接続を確立するには以下を指定します。
DSN を構成する際にはMax Rows 接続プロパティも設定できます。これにより返される行数が制限されるため、レポートやビジュアライゼーションを作成するときのパフォーマンスを向上させることができます。
接続プロパティが未設定の場合は、まずODBC DSN(データソース名)で設定します。これはドライバーインストール時の最後の手順にあたります。Microsoft ODBC データソースアドミニストレーターを使ってODBC DSN を作成および設定できます。
CData ODBC Driver for ApacheHive をLinux 環境にインストールする場合、ドライバーのインストールによってDSN が事前に定義されます。DSN を変更するには、システムデータソースファイル(/etc/odbc.ini)を編集し、必要な接続プロパティを定義します。
[CData ApacheHive Sys]
Driver = CData ODBC Driver for ApacheHive
Description = My Description
Server = 127.0.0.1
Port = 10000
TransportMode = BINARY
これらの設定ファイルの使用方法については、オンラインのヘルプドキュメントを参照してください。
MicroStrategy Developer でデータベースインスタンスを作成してプロジェクトに接続すると、MicroStrategy Web からHive データのデータインポートを実行できます。もしくは、ODBC Driver を使用して新しいデータソースを作成することもできます。*
SELECT
CatalogName NAME_SPACE,
TableName TAB_NAME
FROM
SYS_TABLES
SELECT DISTINCT
CatalogName NAME_SPACE,
TableName TAB_NAME,
ColumnName COL_NAME,
DataTypeName DATA_TYPE,
Length DATA_LEN,
NumericPrecision DATA_PREC,
NumericScale DATA_SCALE
FROM
SYS_TABLECOLUMNS
WHERE
TableName IN (#TABLE_LIST#)
ORDER BY
1,2,3
このようにCData ODBC ドライバと併用することで、270を超えるSaaS、NoSQL データをコーディングなしで扱うことができます。30日の無償評価版が利用できますので、ぜひ自社で使っているクラウドサービスやNoSQL と合わせて活用してみてください。
CData ODBC ドライバは日本のユーザー向けに、UI の日本語化、ドキュメントの日本語化、日本語でのテクニカルサポートを提供しています。
Note:ODBC Driver を使用して接続するには、3- または 4-Tier Architecture が必要です。





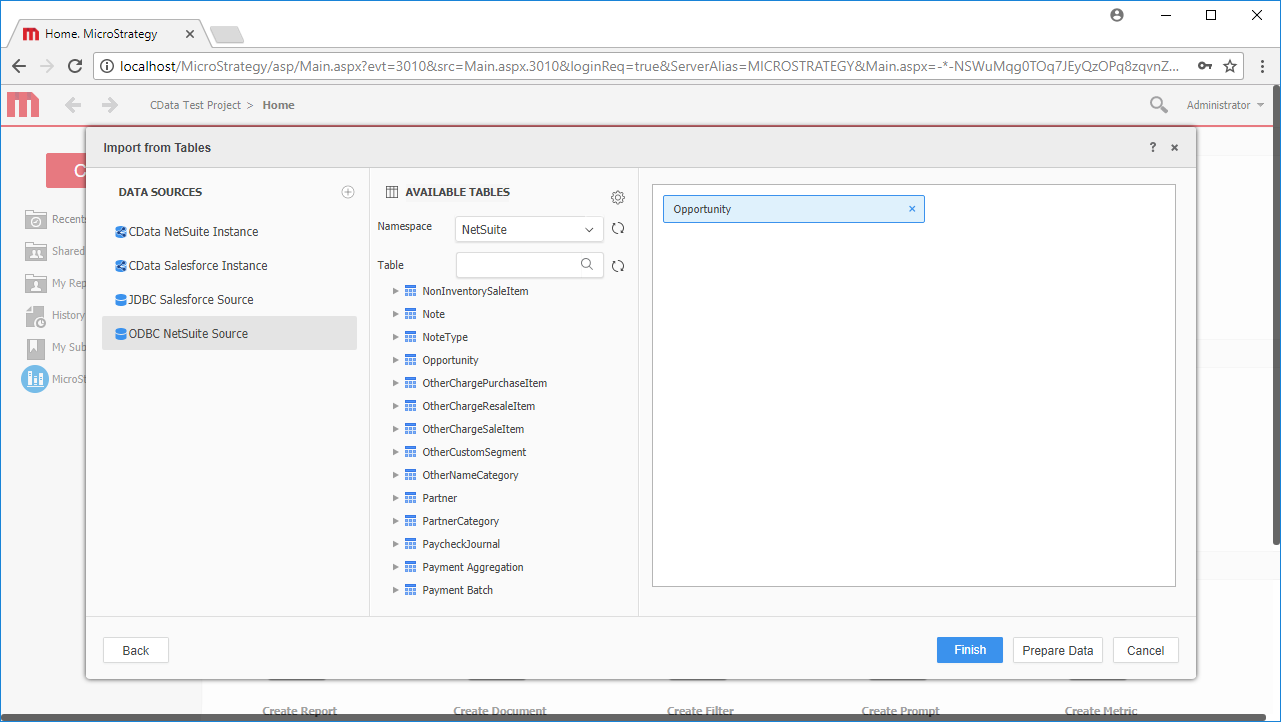 Note:ライブ接続を作成するので、テーブル全体をインポートして、MicroStrategy 製品に固有のフィルタリングおよび集計機能を利用できます。
Note:ライブ接続を作成するので、テーブル全体をインポートして、MicroStrategy 製品に固有のフィルタリングおよび集計機能を利用できます。