ノーコードでクラウド上のデータとの連携を実現。
詳細はこちら →CData


こんにちは!リードエンジニアの杉本です。
コラボフロー(www.collabo-style.co.jp/ )は誰でも簡単に作れるクラウドベースのワークフローサービスです。さらにCData Connect Cloud と連携することで、Spark データへのクラウドベースのアクセスをノーコードで追加できます。本記事では、CData Connect Cloud 経由でコラボフローからSpark 連携を実現する方法を紹介します。
CData Connect Cloud はSpark データへのクラウドベースのOData インターフェースを提供し、コラボフローからSpark データへのリアルタイム連携を実現します。
以下のステップを実行するには、CData Connect Cloud のアカウントが必要になります。こちらから製品の詳しい情報とアカウント作成、30日間無償トライアルのご利用を開始できますので、ぜひご利用ください。
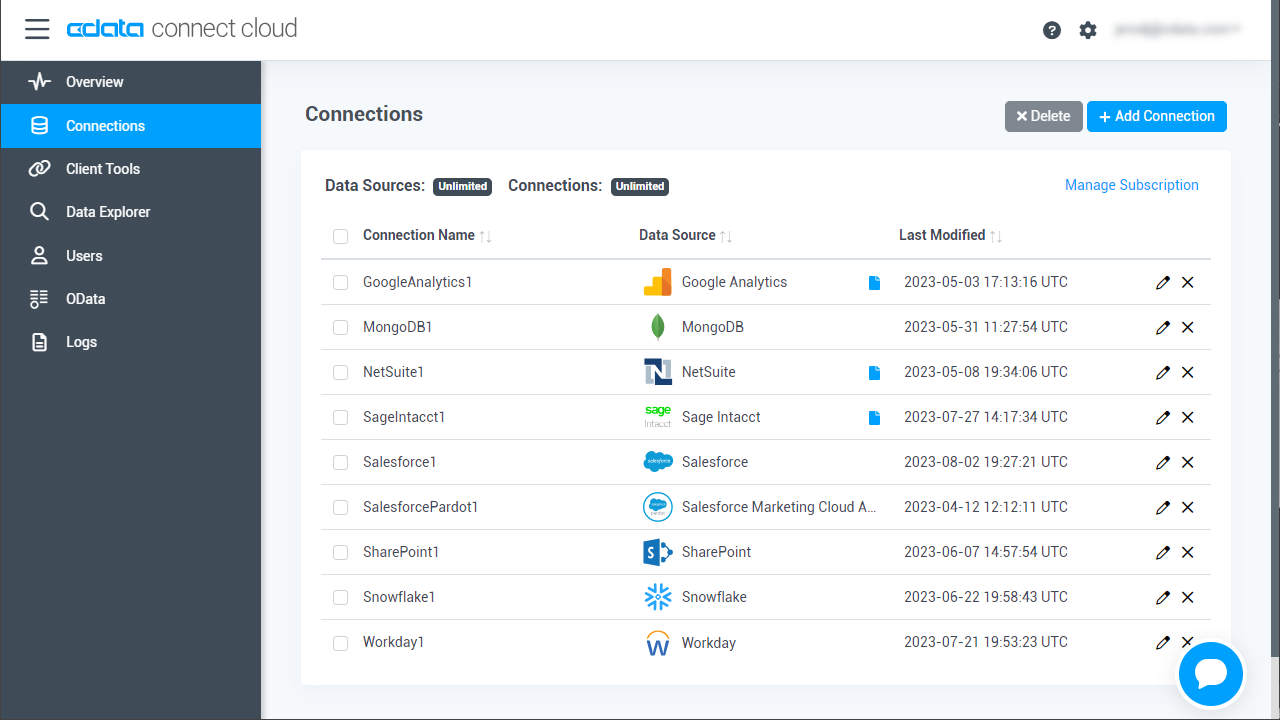
コラボフローでSpark データを操作するには、Connect Cloud からSpark に接続し、コネクションにユーザーアクセスを提供してSpark データのOData エンドポイントを作成する必要があります。
Spark に接続したら、目的のテーブルのOData エンドポイントを作成します。
必要であれば、Connect Cloud 経由でSpark に接続するユーザーを作成します。
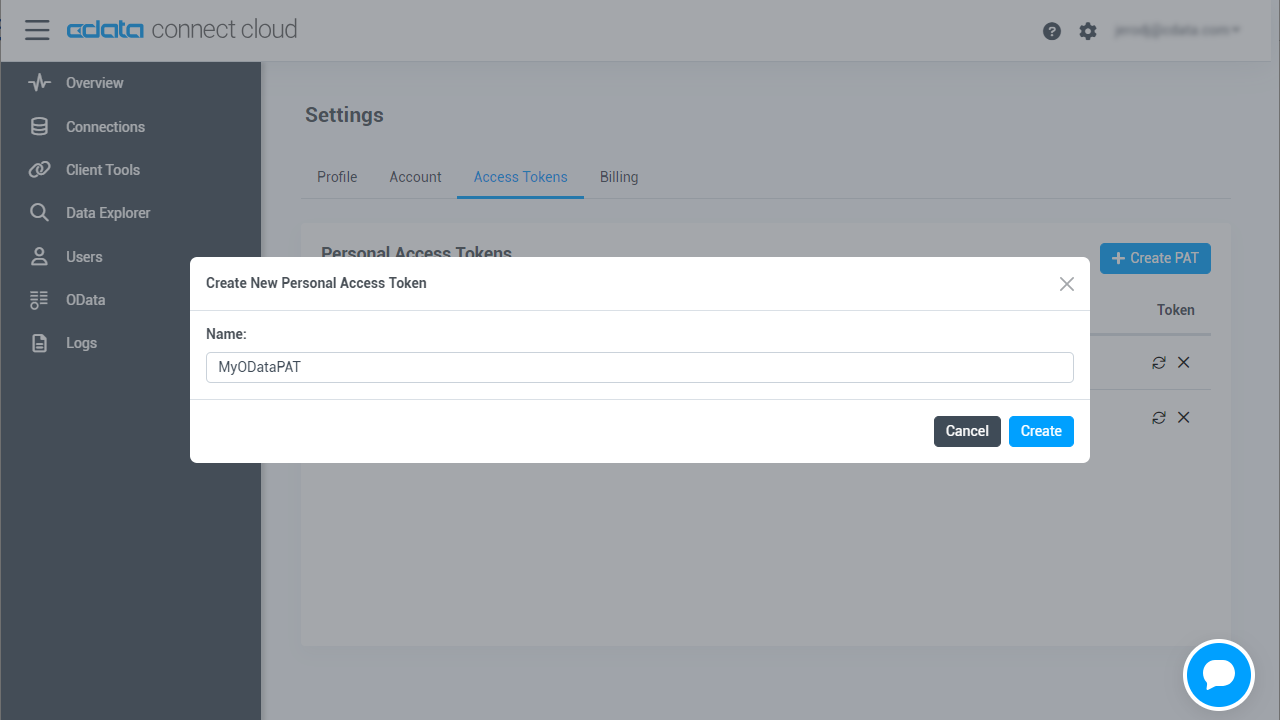
OAuth 認証をサポートしていないサービス、アプリケーション、プラットフォーム、またはフレームワークから接続する場合は、認証に使用するパーソナルアクセストークン(PAT)を作成できます。きめ細かなアクセス管理を行うために、サービスごとに個別のPAT を作成するのがベストプラクティスです。
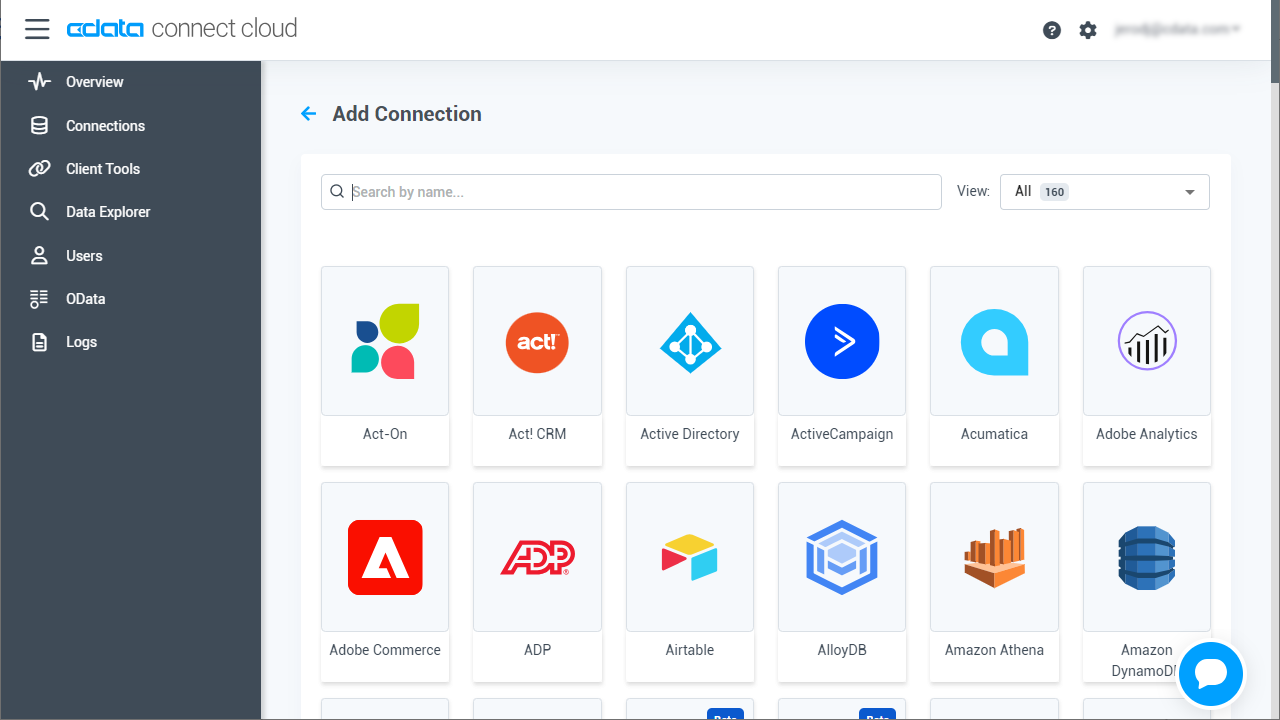
CData Connect Cloud では、簡単なクリック操作ベースのインターフェースでデータソースに接続できます。
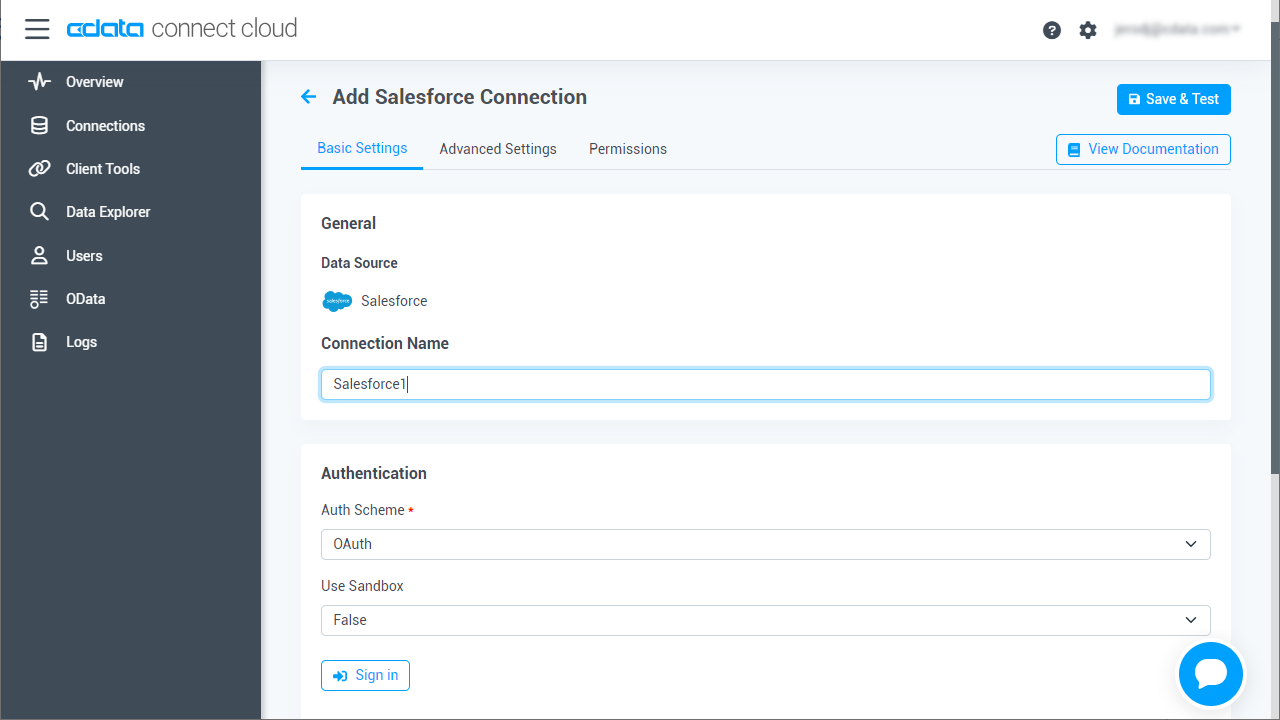
SparkSQL への接続を確立するには以下を指定します。
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。Note:必要な値は、「クラスター」に移動して目的のクラスターを選択し、 「Advanced Options」の下にある「JDBC/ODBC」タブを選択することで、Databricks インスタンスで見つけることができます。
Spark に接続したら、目的のテーブルのOData エンドポイントを作成します。
コネクションとOData エンドポイントを設定したら、コラボフローからSpark データに接続できます。
コラボフロー上で使用するConnect Cloud との接続用JavaScriptを準備します。
(function () {
'use strict';
// Setting Propeties
const AutocompleteSetting =
{
// Autocomplete target field for Collaboflow
InputName: 'fid0',
// Collaboflow item detils line number
ListRowNumber : 15,
// Autocomplete tartget field for Connect Cloud
ApiListupFiledColumn : 'sparksql_column',
// Key Column Name for Connect Cloud resource
ApiListupKeyColumn : 'sparksql_keycolumn',
// Mapping between Collaboflow field and Connect Cloud column
Mappings: [
{
PartsName: 'fid1', // Collabo flow field name
APIName: 'sparksql_column1' // Connect Cloud column name
},
{
PartsName: 'fid2',
APIName: 'sparksql_column2'
},
{
PartsName: 'fid3',
APIName: 'sparksql_column3'
},
{
PartsName: 'fid4',
APIName: 'sparksql_column4'
}
]
};
const CDataConnectCloudSetting = {
// Connect Cloud URL
ConnectCloudUrl : 'http://XXXXXX',
// Connect Cloud Resource Name
ConnectCloudResourceName : 'sparksql_table',
// Connect Cloud Key
Headers : { Authorization: 'Basic YOUR_BASIC_AUTHENTICATION' },
// General Properties
ParseType : 'json',
get BaseUrl() {
return CDataCloudServerSetting.ApiServerUrl + '/api.rsc/' + CDataCloudServerSetting.ApiServerResourceName
}
}
let results = [];
let records = [];
// Set autocomplete processing for target input field
collaboflow.events.on('request.input.show', function (data) {
for (let index = 1; index < AutocompleteSetting.ListRowNumber; index++) {
$('#' + AutocompleteSetting.InputName + '_' + index).autocomplete({
source: AutocompleteDelegete,
autoFocus: true,
delay: 500,
minLength: 2
});
}
});
// This function get details from Connect Cloud, Then set values at each input fields based on mappings object.
collaboflow.events.on('request.input.' + AutocompleteSetting.InputName + '.change', function (eventData) {
debugger;
let tartgetParts = eventData.parts.tbl_1.value[eventData.row_index - 1];
let keyId = tartgetParts[AutocompleteSetting.InputName].value.split(':')[1\;
let record = records.find(x => x[AutocompleteSetting.ApiListupKeyColumn] == keyId);
if (!record)
return;
AutocompleteSetting.Mappings.forEach(x => tartgetParts[x.PartsName].value = '');
AutocompleteSetting.Mappings.forEach(x => tartgetParts[x.PartsName].value = record[x.APIName]);
});
function AutocompleteDelegete(req, res) {
let topParam = '&$top=10'
let queryParam = '$filter=contains(' + AutocompleteSetting.ApiListupFiledColumn + ',\'' + encodeURIComponent(req.term) + '\')';
collaboflow.proxy.get(
CDataCloudServerSetting.BaseUrl + '?' +
queryParam +
topParam,
CDataCloudServerSetting.Headers,
CDataCloudServerSetting.ParseType).then(function (response) {
results = [];
records = [];
if (response.body.value.length == 0) {
results.push('No Results')
res(results);
return;
}
records = response.body.value;
records.forEach(x => results.push(x[AutocompleteSetting.ApiListupFiledColumn] + ':' + x[AutocompleteSetting.ApiListupKeyColumn]));
res(results);
}).catch(function (error) {
alert(error);
});
}
})();
JavaScript を作成したら、後はコラボフローにアップするだけです。
コラボフローからSpark リアルタイムデータに直接接続できるようになりました。これで、Spark データを複製せずにより多くの接続とアプリを作成できます。
クラウドアプリケーションから直接100を超えるSaaS 、ビッグデータ、NoSQL ソースへのリアルタイムデータアクセスを取得するには、CData Connect Cloud を参照してください。