ノーコードでクラウド上のデータとの連携を実現。
詳細はこちら →Apache Spark Driver の30日間無償トライアルをダウンロード
30日間の無償トライアルへCData


こんにちは!ウェブ担当の加藤です。マーケ関連のデータ分析や整備もやっています。
Birst は、組織が複雑なプロセスを迅速に理解し、最適化することを支援するクラウドビジネスインテリジェンス(BI)ツールおよび分析プラットフォームです。CData JDBC Driver for SparkSQL と組み合わせると、Birst Cloud Agent を経由してリアルタイムSpark データ に接続し、ビジュアライズを構築できます。ここでは、Cloud Agent を使用してSpark に連携し、Birst で動的レポートを作成する方法を段階的に説明します。
強力なデータ処理機能により、CData JDBC Driver はBirst のSpark データ 操作に高いパフォーマンスを提供します。Birst からSpark への複雑なSQL クエリを発行すると、ドライバーはフィルタや集計などのサポートされているSQL 操作を直接Spark にプッシュし、組込みSQL エンジンを利用してクライアント側でサポートしない操作を処理します。組み込みの動的メタデータクエリにより、JDBC ドライバーはネイティブのBirst データ型を使用してSpark データ を視覚化および分析することを可能にします。
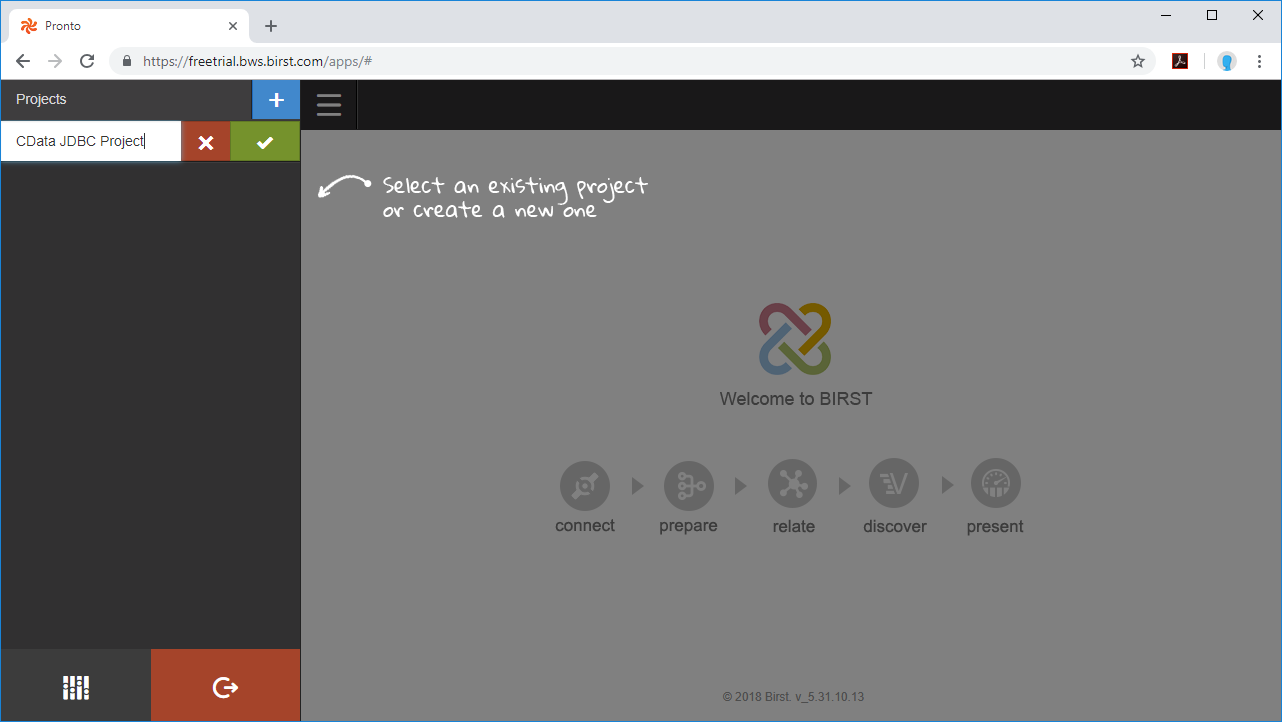
Birst プロジェクトを作成する前に、JDBC Driver を操作するためのBirst Cloud Agent をインストールする必要があります。また、JDBC ドライバーのJAR ファイル(および存在する場合はLIC ファイル)をCloud Agent のインストール場所の/drivers/ ディレクトリにコピーします。
ドライバーとCloud Agent のインストールが完了したら、開始できます。
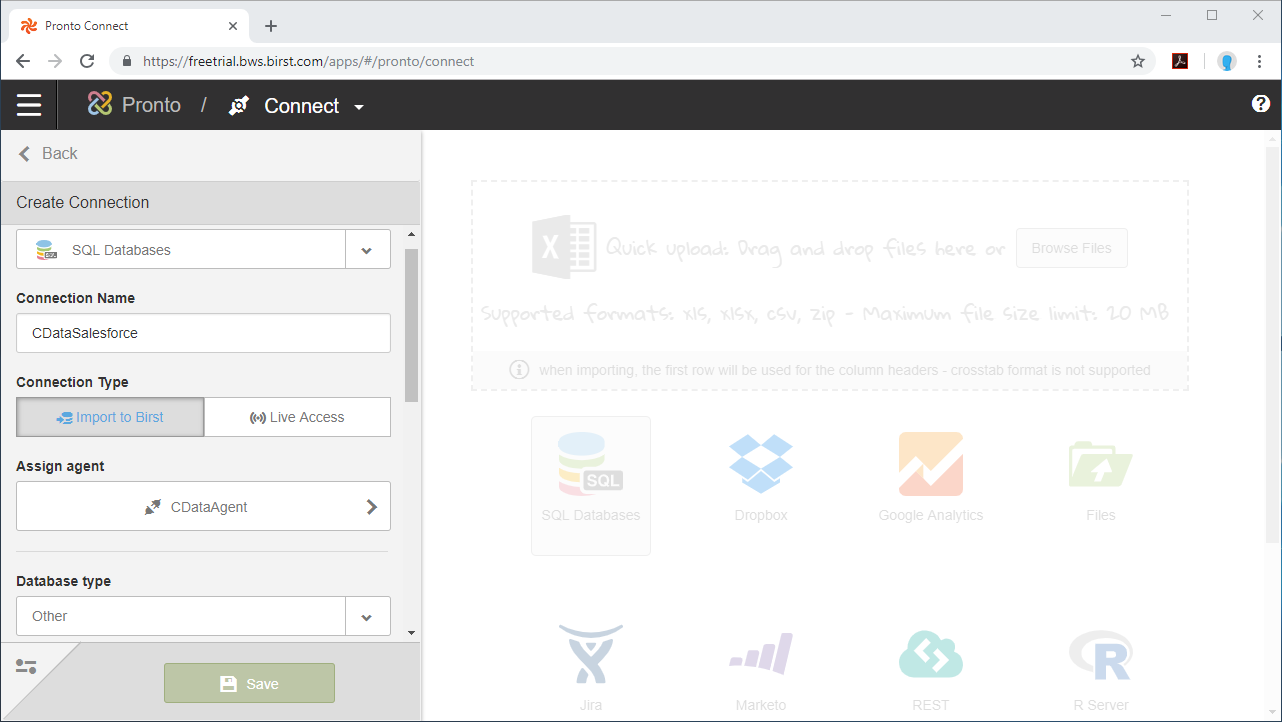
SparkSQL への接続を確立するには以下を指定します。
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。Note:必要な値は、「クラスター」に移動して目的のクラスターを選択し、 「Advanced Options」の下にある「JDBC/ODBC」タブを選択することで、Databricks インスタンスで見つけることができます。
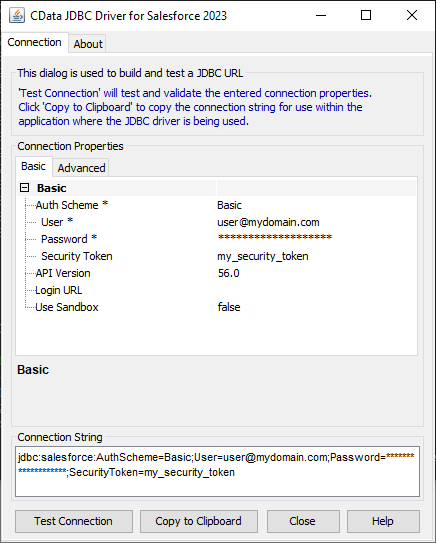
JDBC URL の構成については、Spark JDBC Driver に組み込まれている接続文字列デザイナーを使用してください。JAR ファイルのダブルクリック、またはコマンドラインからJAR ファイルを実行します。
java -jar cdata.jdbc.sparksql.jar
接続プロパティを入力し、接続文字列をクリップボードにコピーします。
JDBC URL を構成する際、Max Rows 接続プロパティを設定することもできます。これによって戻される行数を制限するため、可視化・レポートのデザイン設計時のパフォーマンスを向上させるのに役立ちます。
以下はSpark の一般的なJDBC 接続文字列です。
jdbc:sparksql:Server=127.0.0.1;
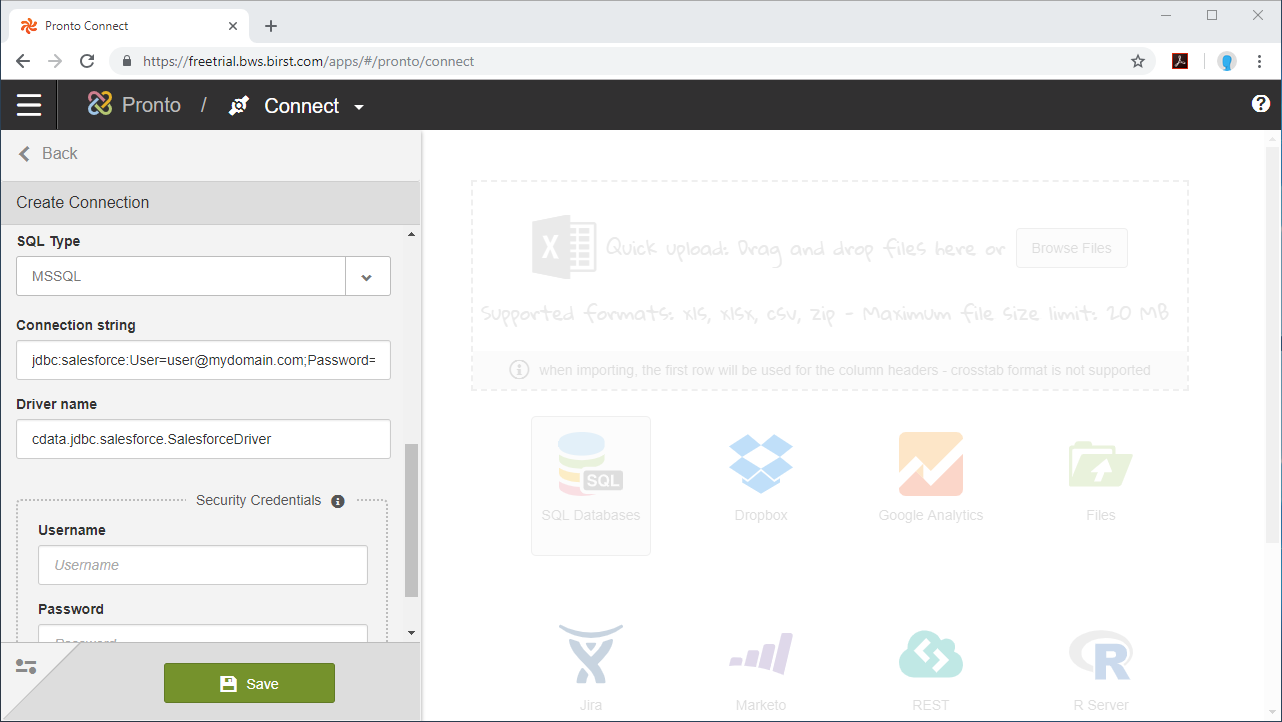
NOTE Spark への認証は接続文字列に管理されるため、[Security Credentials]は空白でも問題ありません。
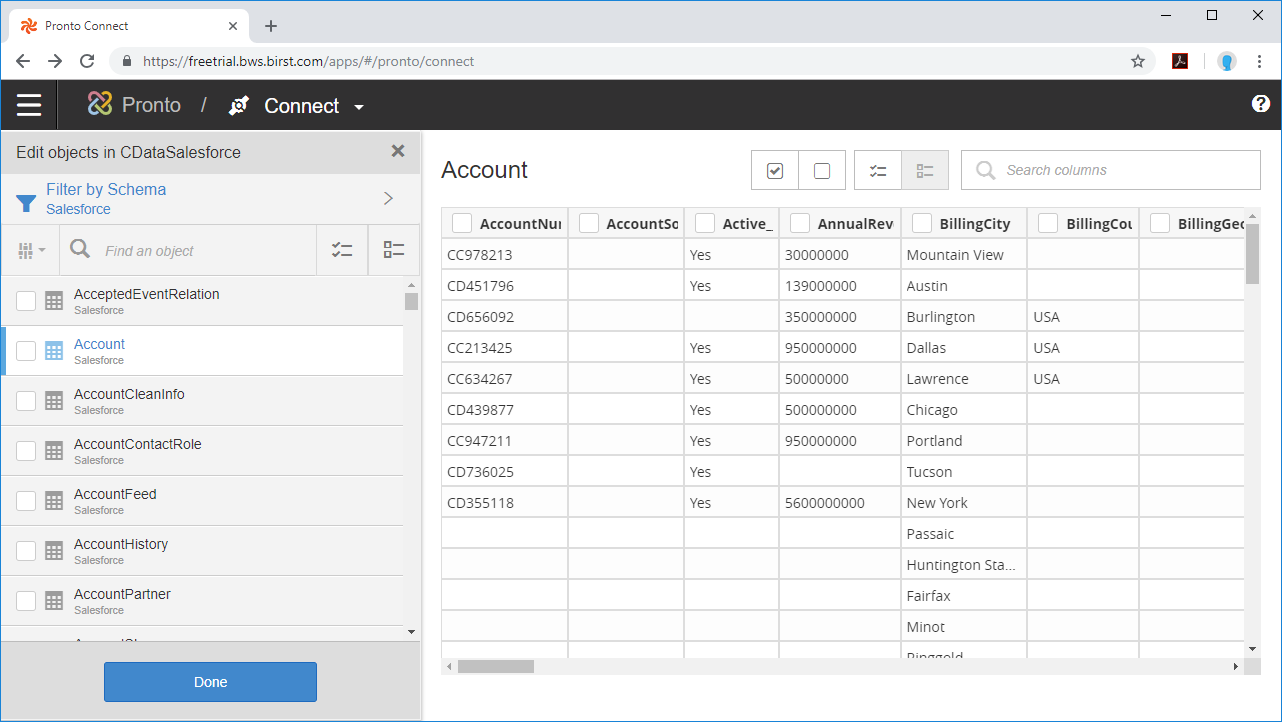
接続が構成されたら、データセットのスキーマを構成し、ビジュアライズするテーブル、ビュー、そしてカラムを選択することができるようになります。
オブジェクトが構成されたら、Pronto Prepare and Relate ツールを用いて、データ準備の実行やデータのリレーションを検出できるようになります。
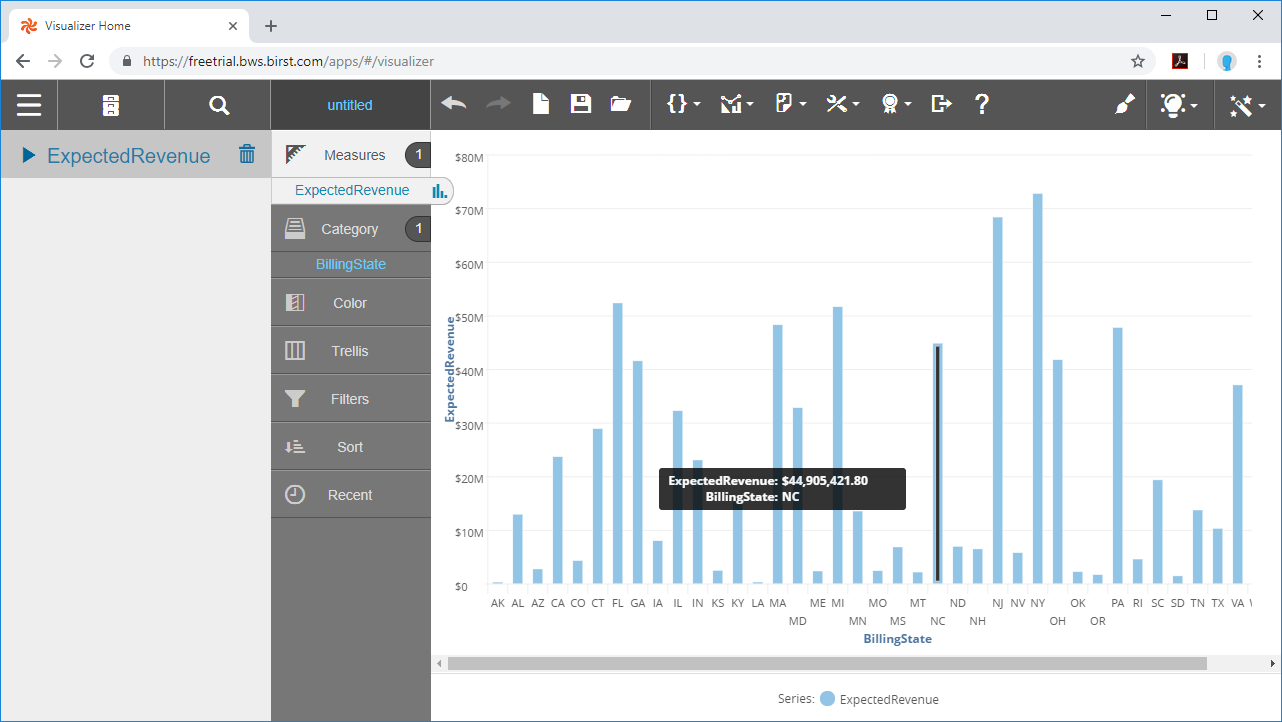
データを準備し、接続されたオブジェクト間のリレーションを定義することで、ビジュアライゼーションを構築することができるようになります。
CData JDBC Driver for SparkSQL をCloud Agent やBirst とともに用いることにより、Spark で簡単に堅牢なビジュアライゼーションとレポートを作成できます。30日の無償評価版をダウンロードし、Birst ビジュアライゼーションの構築を開始してください。