ノーコードでクラウド上のデータとの連携を実現。
詳細はこちら →Apache Spark Driver の30日間無償トライアルをダウンロード
30日間の無償トライアルへCData


こんにちは!ウェブ担当の加藤です。マーケ関連のデータ分析や整備もやっています。
Informatica は、データを転送・変換するための強力で立派な手段を提供します。CData JDBC Driver for SparkSQL を利用することで、Informatica の強力なデータ転送および操作機能とシームレスに統合される、業界で実証済みの標準に基づくドライバーにアクセスできます。このチュートリアルでは、Informatica PowerCenter でSpark を転送および参照する方法を示します。

ドライバーをInformatica PowerCenter サーバーに展開するために、インストールディレクトリのlib サブフォルダにあるCData JAR および.lic ファイルを次のフォルダにコピーします。Informatica-installation-directory\services\shared\jars\thirdparty.
Developer ツールでSpark を使用するには、インストールディレクトリのlib サブフォルダにあるCData JAR および.lic ファイルを次のフォルダにコピーする必要があります。
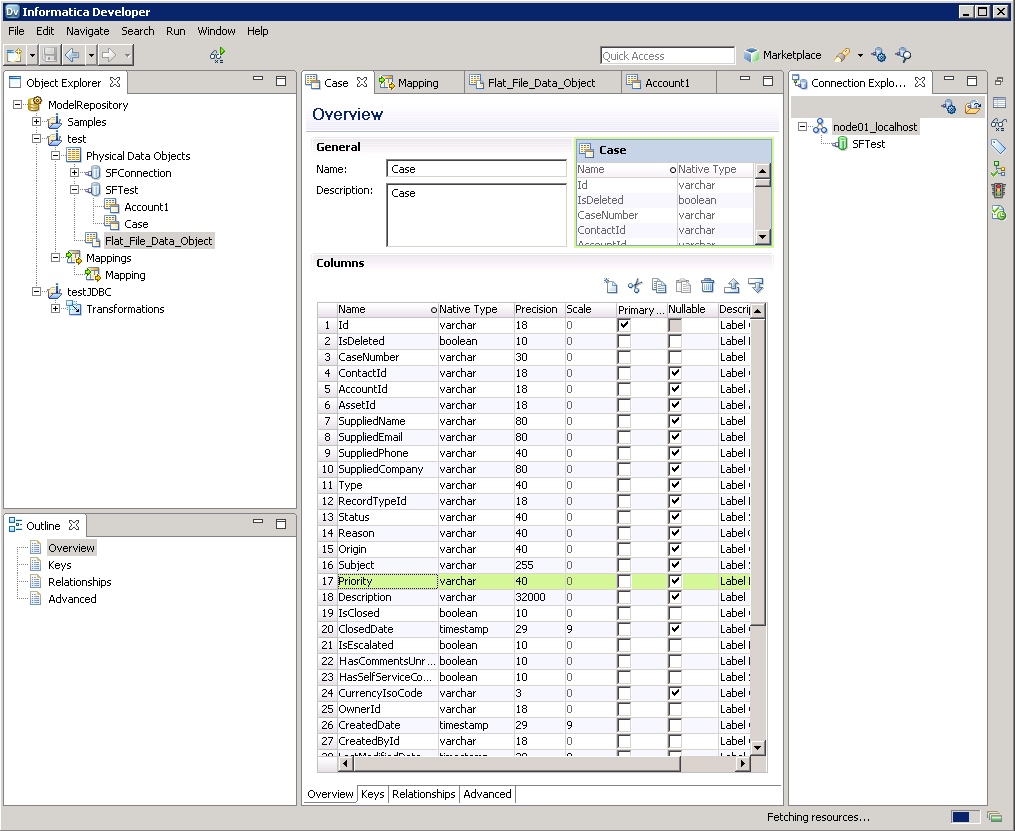
以下のステップに従って、Informatica Developer に接続します。
cdata.jdbc.sparksql.SparkSQLDriver
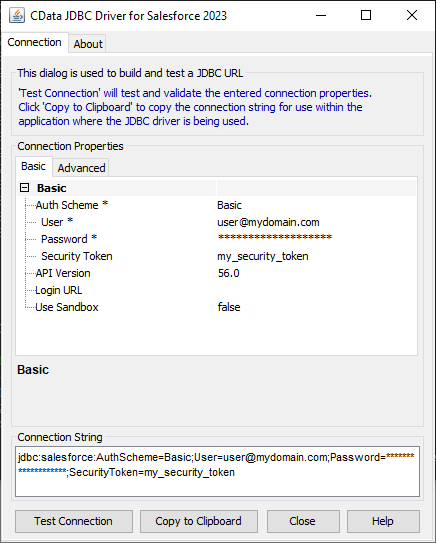
SparkSQL への接続を確立するには以下を指定します。
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。Note:必要な値は、「クラスター」に移動して目的のクラスターを選択し、 「Advanced Options」の下にある「JDBC/ODBC」タブを選択することで、Databricks インスタンスで見つけることができます。
JDBC URL の構成については、Spark JDBC Driver に組み込まれている接続文字列デザイナを使用してください。JAR ファイルのダブルクリック、またはコマンドラインからJAR ファイルを実行します。
java -jar cdata.jdbc.sparksql.jar
接続プロパティを入力し、接続文字列をクリップボードにコピーします。
以下は一般的な接続文字列です。
jdbc:sparksql:Server=127.0.0.1;
ドライバーJAR をクラスパスに追加してJDBC 接続を作成すると、Informatica のSpark エンティティにアクセスできるようになります。以下のステップに従ってSpark に接続し、Spark テーブルを参照します。
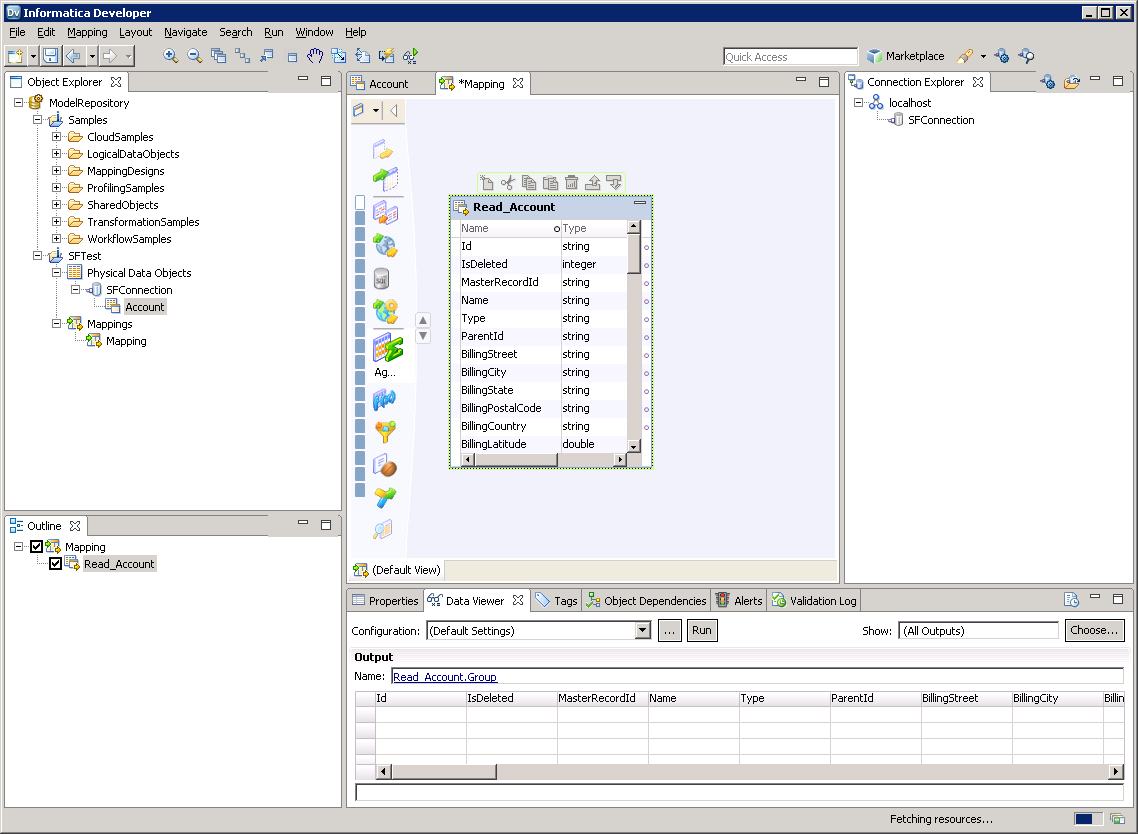
以下より、[Data Viewer]でSpark テーブルを参照できるようになります。テーブルの[node]を右クリックし、[Open]をクリックします。[Data Viewer]で[Run]をクリックします。
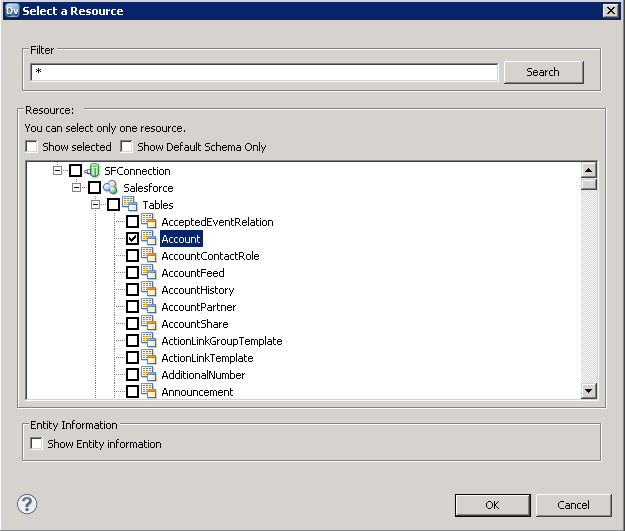
以下のステップに従って、プロジェクトにSpark テーブルを追加します。
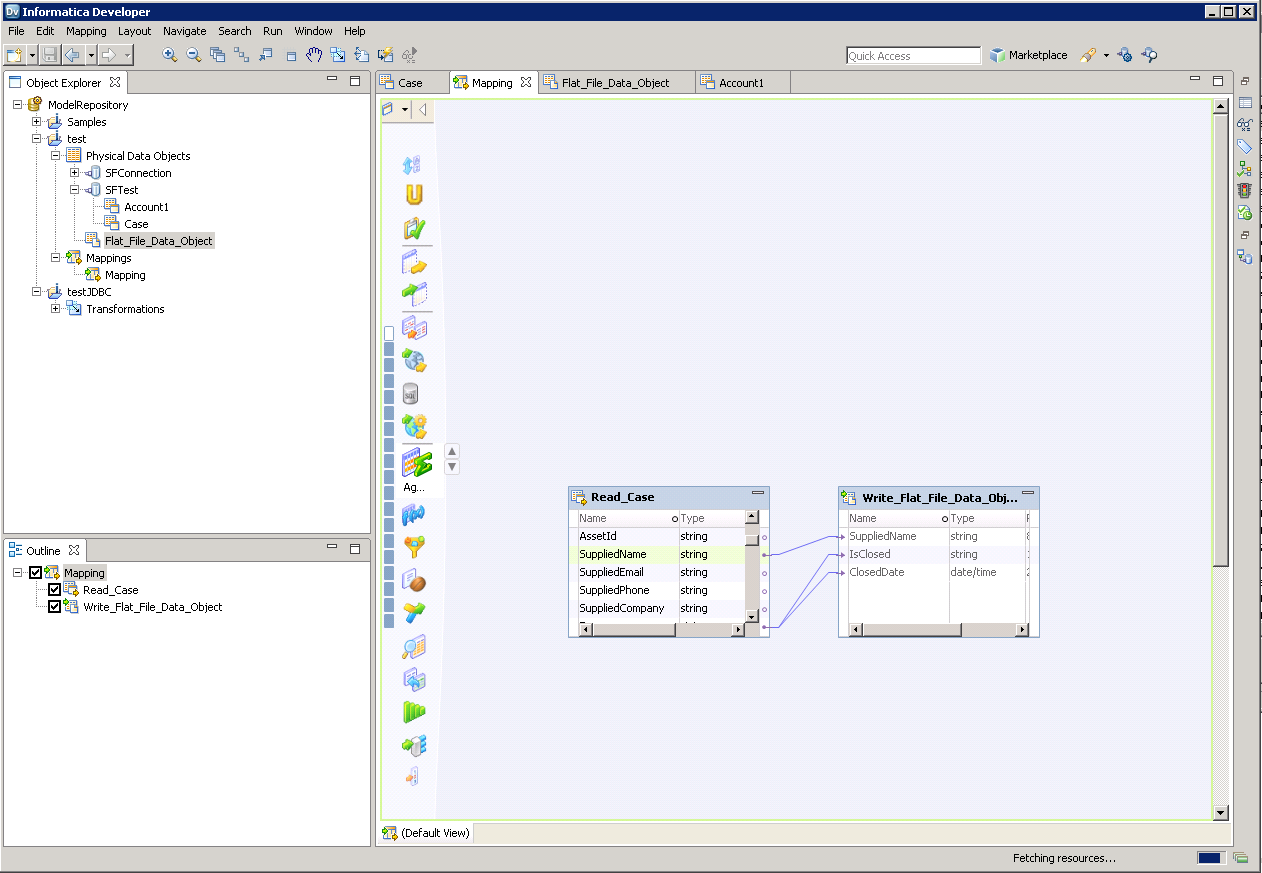
以下のステップに従って、マッピングにSpark ソースを追加します。
以下のステップに従って、Spark カラムをフラットファイルにマッピングします。
Spark を転送するために、ワークスペースで右クリックし、[Run Mapping]をクリックします。