ノーコードでクラウド上のデータとの連携を実現。
詳細はこちら →Apache Spark Driver の30日間無償トライアルをダウンロード
30日間の無償トライアルへCData


こんにちは!ウェブ担当の加藤です。マーケ関連のデータ分析や整備もやっています。
この記事では、CData JDBC Driver for SparkSQL を使ってSpark の連携機能を持つJaspersoft Studio の基本的な帳票をテーブルやチャートで作成する方法を説明します。レポートを実行するたびに、チャートおよびテーブルはリアルタイムデータを表示します。JasperSoft のウィザードを使って、レポートエレメントを埋めるSQL クエリをいくつかビルドします。ドライバーは、リレーショナルデータベースへのデータのコピー処理をスキップする間、標準SQL を利用可能にします。代わりに、クエリは基になるSpark API に直接実行されます。
Jaspersoft Studio で、[Data Adapter]ウィザードを使ってJDBC データソースに接続できます。下記の手順に従って、プロジェクトからSpark に接続します。Spark データアダプターをワークスペースに追加します。
JDBC URL:JDBC URL に必要な接続プロパティを入力。接続プロパティは、セミコロン区切りでname-value ペアを入力する必要があります。Spark の一般的なJDBC URL は次のとおりです:
jdbc:sparksql:Server=127.0.0.1;
SparkSQL への接続を確立するには以下を指定します。
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。Note:必要な値は、「クラスター」に移動して目的のクラスターを選択し、 「Advanced Options」の下にある「JDBC/ODBC」タブを選択することで、Databricks インスタンスで見つけることができます。
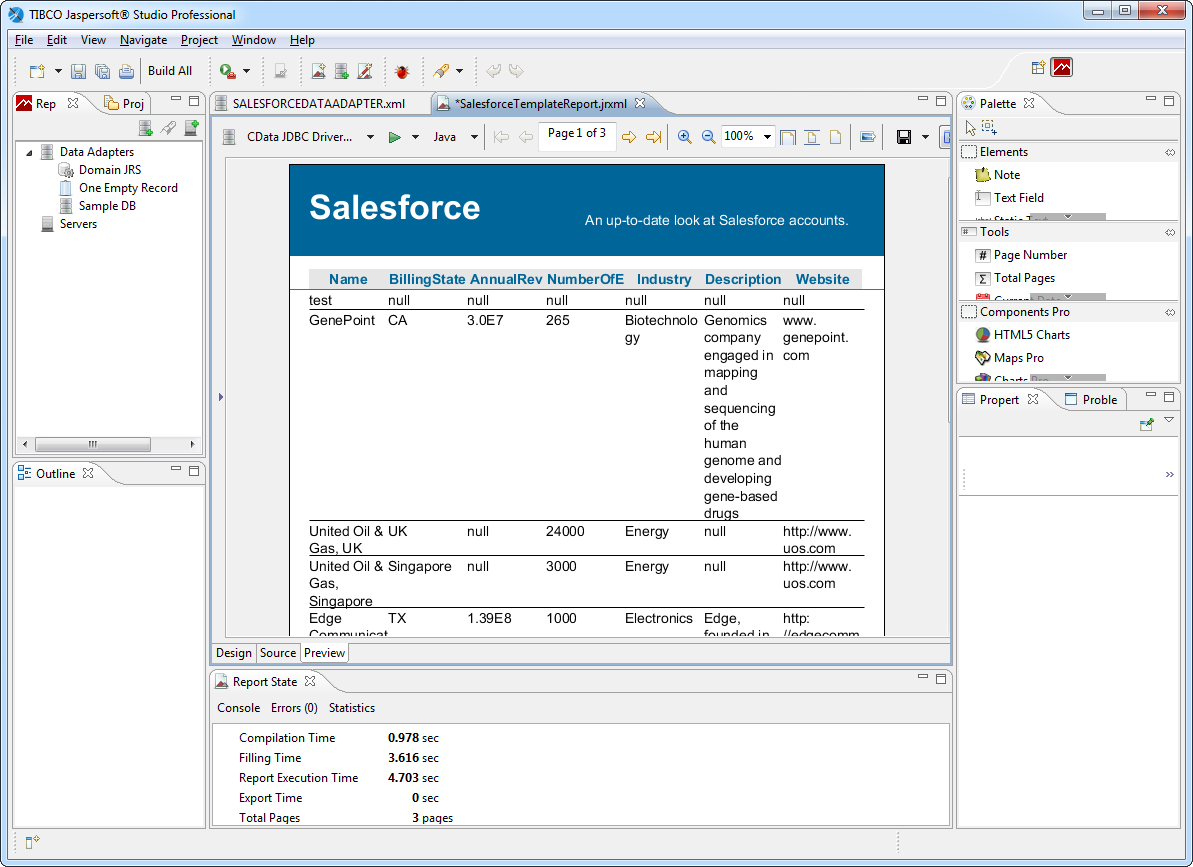
Spark のデータアダプターを作成したら、Spark データをJasperReports に追加できます。このセクションでは同梱されているテンプレートの一つをSpark データに連携させる方法について説明します。
SELECT * FROM Customers
[Preview]タブでは、最新のSpark を使ったものと同じ帳票を見ることができます。
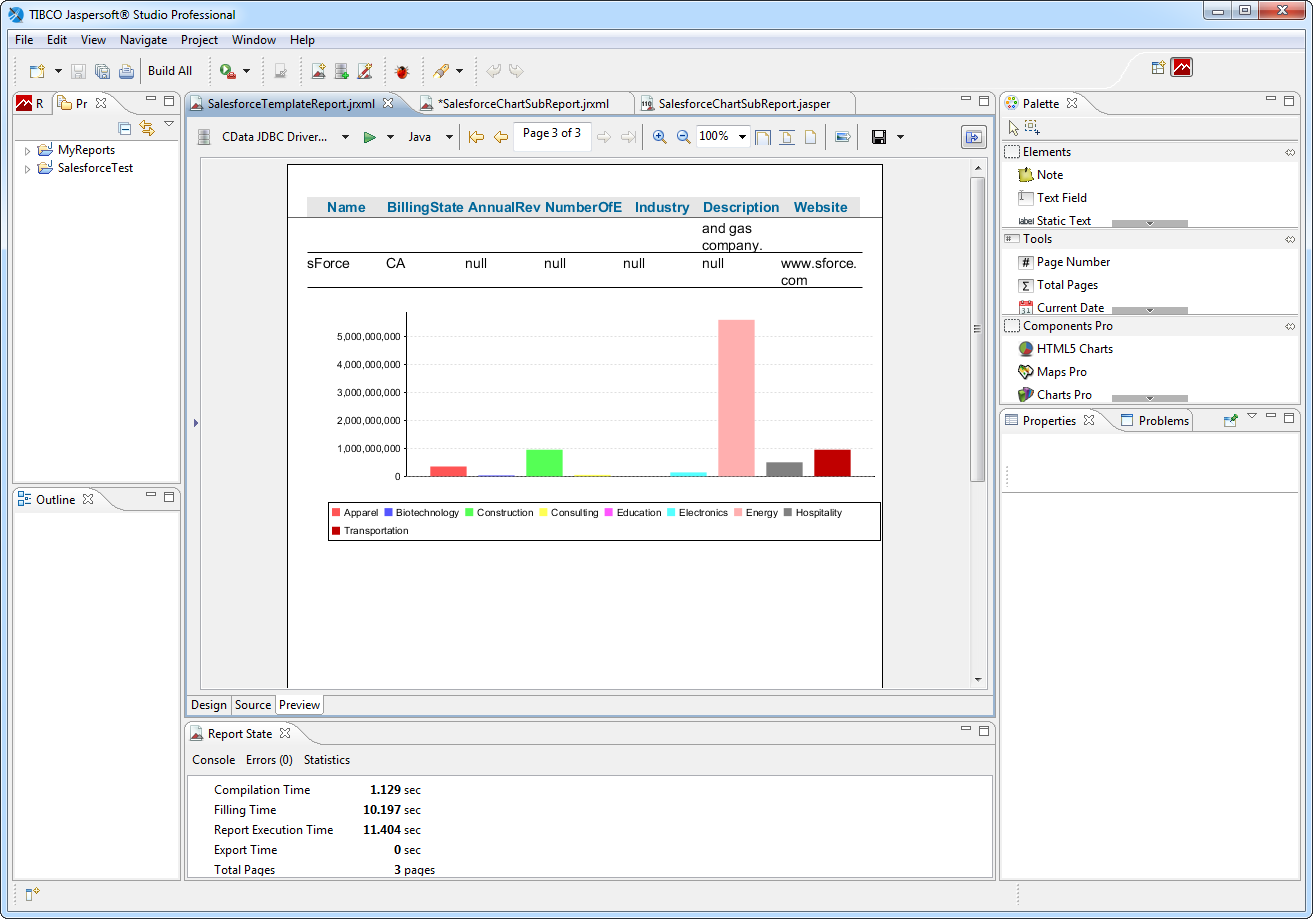
下記の手順に従って、Spark のチャートを既存の帳票に追加します。棒グラフを、先のセクションで作成した帳票テンプレートの最後に追加します。
SELECT City, Balance FROM Customers
データセットを追加したら、下記の手順に従ってチャートを作成します。
チャートを作成したら基本的なフォーマットを行い、サブレポートをレポートに未使用スペースなくシームレスに追加できるようにします。
プレビューする前に帳票への変更を保存します。チャートが帳票の最後のページに表示されます。