ノーコードでクラウド上のデータとの連携を実現。
詳細はこちら →Apache Spark Driver の30日間無償トライアルをダウンロード
30日間の無償トライアルへCData


こんにちは!ウェブ担当の加藤です。マーケ関連のデータ分析や整備もやっています。
CData JDBC Driver for SparkSQL はダッシュボードや帳票ツールからリアルタイムSpark データへの連携を可能にします。この記事では、Spark をJDBC データソースとして接続する方法と、Pentaho でSpark を元に帳票を作成する方法を説明します。
以下の手順でドライバーを新しいデータソースに設定します。[Data]>[Add Data Source]>[Advanced]>[JDBC (Custom)]とクリックし、新しいSpark 接続を作成します。ダイアログが表示されたら、次のように接続プロパティを設定します。
Custom Connection URL property:JDBC URL を入力。初めに以下を入力し jdbc:sparksql: 次にセミコロン区切りで接続プロパティを入力します。
SparkSQL への接続を確立するには以下を指定します。
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。Note:必要な値は、「クラスター」に移動して目的のクラスターを選択し、 「Advanced Options」の下にある「JDBC/ODBC」タブを選択することで、Databricks インスタンスで見つけることができます。
以下は一般的なJDBC URL です:
jdbc:sparksql:Server=127.0.0.1;
これで、Spark の帳票を作成する準備が整いました。
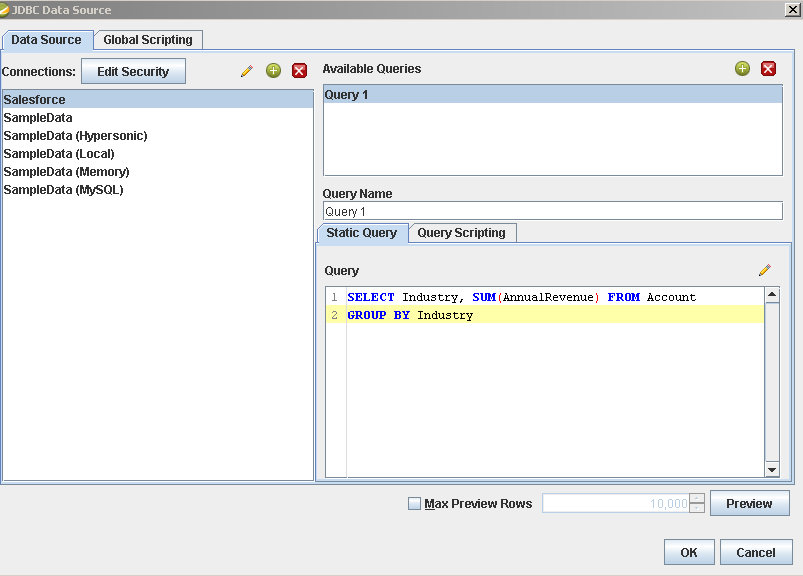
帳票にSpark データソースを追加します:[Data]>[Add Data Source]>[JDBC]をクリックし、データソースを選択します。
クエリを設定します。この記事では次を使います:
SELECT City, Balance FROM Customers