ノーコードでクラウド上のデータとの連携を実現。
詳細はこちら →Apache Spark Driver の30日間無償トライアルをダウンロード
30日間の無償トライアルへCData


こんにちは!ウェブ担当の加藤です。マーケ関連のデータ分析や整備もやっています。
PostgreSQL には多くの対応クライアントがあります。標準のドライバーからBI、アナリティクスツールまで、PostgreSQL はデータ接続の人気のインターフェースです。JDBC ドライバーを使用することで、簡単に任意の標準クライアントから接続できるPostgreSQL エントリポイントを作成できます。
Spark にPostgreSQL データベースとしてアクセスするには、CData JDBC Driver for SparkSQL とJDBC foreign data wrapper (FDW) を使用します。この記事ではFDW をコンパイルしてインストールし、PostgreSQL サーバーからSpark にクエリを実行します。
JDBC データソースとしてSpark に接続するには、以下が必要です。
Driver クラス
cdata.jdbc.sparksql.SparkSQLDriver
SparkSQL への接続を確立するには以下を指定します。
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。Note:必要な値は、「クラスター」に移動して目的のクラスターを選択し、 「Advanced Options」の下にある「JDBC/ODBC」タブを選択することで、Databricks インスタンスで見つけることができます。
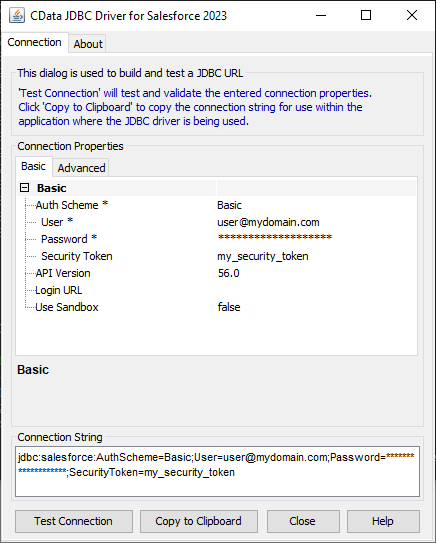
JDBC URL の構成については、Spark JDBC Driver に組み込まれている接続文字列デザイナを使用できます。JAR ファイルのダブルクリック、またはコマンドラインからJAR ファイルを実行します。
java -jar cdata.jdbc.sparksql.jar
接続プロパティを入力し、接続文字列をクリップボードにコピーします。
以下は一般的なJDBC URL です。
jdbc:sparksql:Server=127.0.0.1;
FDW は、PostgreSQL を再コンパイルせずに、PostgreSQL の拡張機能としてインストールできます。例としてjdbc2_fdw 拡張子を使用します。
ln -s /usr/lib/jvm/java-6-openjdk/jre/lib/amd64/server/libjvm.so /usr/lib/libjvm.so
make install USE_PGXS=1
拡張機能をインストールした後、以下のステップに従ってSpark へのクエリの実行を開始します。
CREATE EXTENSION jdbc2_fdw;
CREATE SERVER SparkSQL
FOREIGN DATA WRAPPER jdbc2_fdw OPTIONS (
drivername 'cdata.jdbc.sparksql.SparkSQLDriver',
url 'jdbc:sparksql:Server=127.0.0.1;',
querytimeout '15',
jarfile '/home/MyUser/CData/CData\ JDBC\ Driver\ for\ Salesforce MyDriverEdition/lib/cdata.jdbc.sparksql.jar');
CREATE USER MAPPING for postgres SERVER SparkSQL OPTIONS (
username 'admin',
password 'test');
postgres=# CREATE FOREIGN TABLE customers (
customers_id text,
customers_City text,
customers_Balance numeric)
SERVER SparkSQL OPTIONS (
table_name 'customers');
postgres=# SELECT * FROM customers;
このようにCData JDBC Driver for SparkSQL を使って簡単にSpark データを取得して検索対象にすることができました。ぜひ、30日の無償評価版 をお試しください。