ノーコードでクラウド上のデータとの連携を実現。
詳細はこちら →Apache Spark Driver の30日間無償トライアルをダウンロード
30日間の無償トライアルへCData


こんにちは!ドライバー周りのヘルプドキュメントを担当している古川です。
CData JDBC Driver for SparkSQL はJDBC 標準をサポートするビジネスインテリジェンスおよびデータマイニングツールからリアルタイムSpark に接続することを可能にします。この記事では、Spark をSpagoBI Studio のレポートに統合し、SpagoBI サーバーでホストする方法を説明します。
以下のステップに従ってSpagoBI サーバーでJDBC data source for SparkSQL を作成します。
Spark ドライバーリソースをコンテクストに追加します。以下のリソース定義をserver.xml の[GlobalNamingResources]要素に追加できます。
<Resource name="jdbc/sparksql" auth="Container" type="javax.sql.DataSource" driverclassname="cdata.jdbc.sparksql.SparkSQLDriver" factory="org.apache.tomcat.jdbc.pool.DataSourceFactory" maxactive="20" maxidle="10" maxwait="-1"/>
<ResourceLink global="jdbc/sparksql" name="jdbc/sparksql" type="javax.sql.DataSource"/>
SpagoBI サーバーのリソースにドライバーを追加した後、データソースを追加します。SpagoBIで[Resources]->[Data Source]->[Add]と進み、以下の情報を入力します。
SparkSQL への接続を確立するには以下を指定します。
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。Note:必要な値は、「クラスター」に移動して目的のクラスターを選択し、 「Advanced Options」の下にある「JDBC/ODBC」タブを選択することで、Databricks インスタンスで見つけることができます。
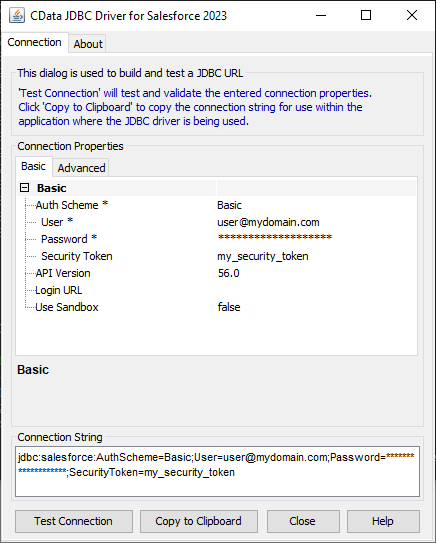
JDBC URL の構成については、Spark JDBC Driver に組み込まれている接続文字列デザイナを使用してください。JAR ファイルのダブルクリック、またはコマンドラインからJAR ファイルを実行します。
java -jar cdata.jdbc.sparksql.jar
接続プロパティを入力し、接続文字列をクリップボードにコピーします。
以下は一般的なJDBC URL です。
jdbc:sparksql:Server=127.0.0.1;
以下のステップに従い、SpagoBI StudioでSpark に基づいたレポートを作成します。SQL クエリの結果をチャートに挿入するデータセットを作成します。次のセクションでは、このレポートをSpagoBI サーバーでホストします。
初めに、SpagoBI Studio のレポートからSpark に接続してください。
jdbc:sparksql:Server=127.0.0.1;
必要な接続プロパティを取得するためのガイドについては、ドライバーヘルプの[Getting Started]チャプターを見てください。
Spark に接続した後、SQL クエリの結果を含むデータセットを作成します。
SELECT City, Balance FROM Customers
データセットを使用して、レポートオブジェクトにデータを入力できます。以下のステップに従って、チャートを作成します。
以下のステップに従って、SpagoBI サーバーでリアルタイムSpark に基づいてドキュメントをホストできます。前のセクションで作成したレポートをテンプレートとして使用します。レポートユーザーがリアルタイムデータにアクセスできるようにするには、サーバー上のSpark JDBC データソースに置き換えられるプレースホルダパラメータを作成します。
[Property Binding]ノードで、JDBC Driver のURL バインディングプロパティurl パラメータに設定します。プロパティのボックスをクリックします。[Category]セクションで[Report Parameters]を選択します。[Subcategory]セクションで[All]を選択し、パラメータをダブルクリックします。
JavaScript構文に以下のように入力することもできます。
params["url"].value
続いて、SpagoBI サーバーでレポート用の新しいドキュメントを作成します。
[Template]セクションで、[Choose File]をクリックします。レポートプロジェクトを含むフォルダに移動します。.rptdesign ファイルを選択します。
Noteプロジェクトへのパスは、プロジェクトプロパティで確認できます。
サーバーでレポートを実行すると、プレースホルダurl パラメータがサーバーで定義されたJDBC URL に置き換えられます。