ノーコードでクラウド上のデータとの連携を実現。
詳細はこちら →Apache Spark Driver の30日間無償トライアルをダウンロード
30日間の無償トライアルへCData


こんにちは!ドライバー周りのヘルプドキュメントを担当している古川です。
CData JDBC Driver for SparkSQL を使用して、Squirrel SQL Client などのツールでSpark へのクエリを実行できます。この記事では、JDBC data source for SparkSQL を作成し、クエリを実行します。
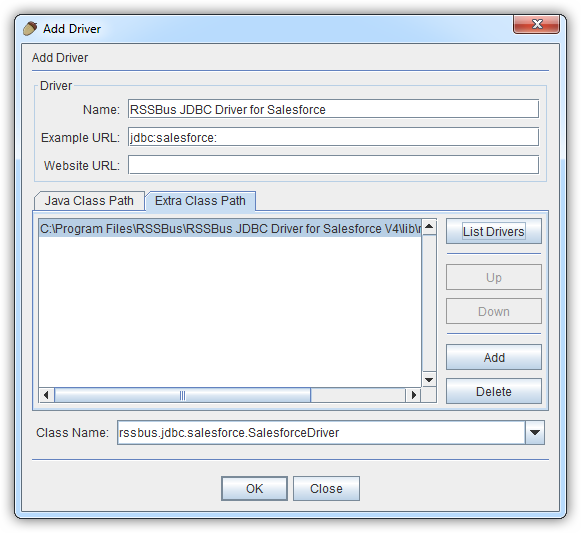
以下のステップに従ってドライバーJAR を追加します。
以下のステップに従って、接続プロパティをドライバーエイリアスに保存します。
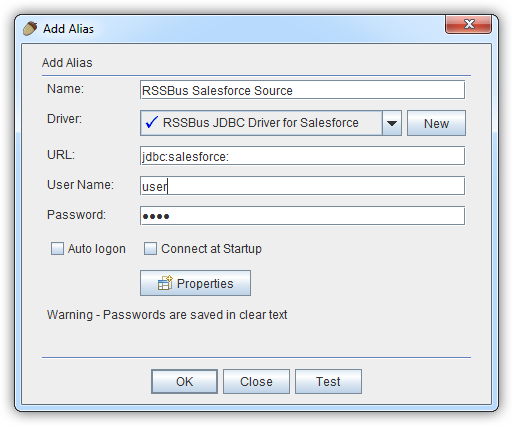
表示される[Add Alias]ウィザードで、JDBC ドライバーには以下のフィールドが要求されます。
SparkSQL への接続を確立するには以下を指定します。
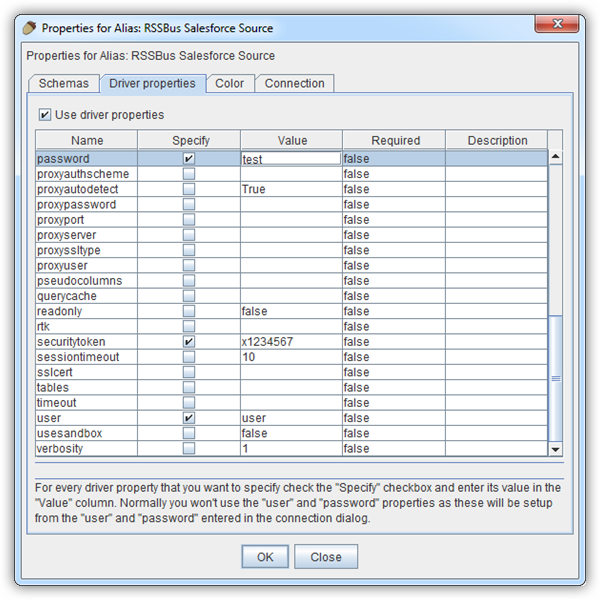
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。Note:必要な値は、「クラスター」に移動して目的のクラスターを選択し、 「Advanced Options」の下にある「JDBC/ODBC」タブを選択することで、Databricks インスタンスで見つけることができます。
以下は一般的な接続文字列です。
jdbc:sparksql:Server=127.0.0.1;
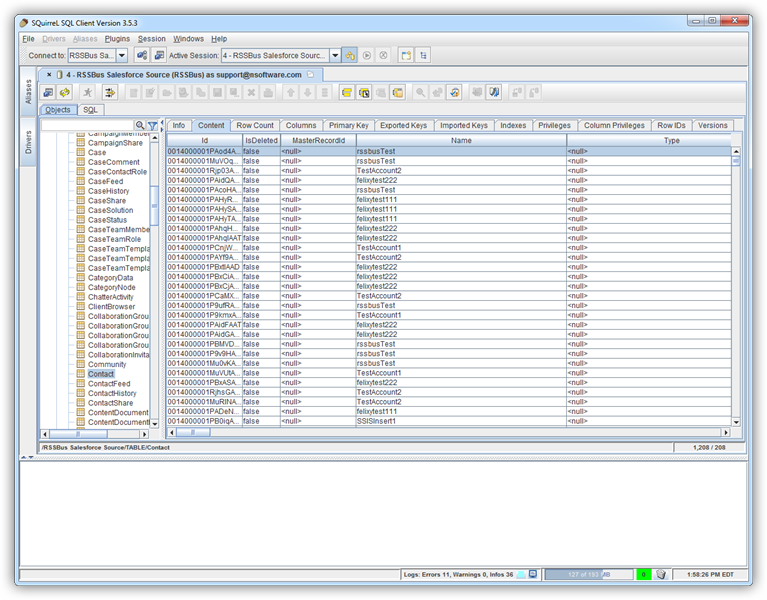
メタデータが読み込まれると、Spark データソースの新しいタブが表示されます。[Objects]サブタブでは、使用可能なテーブルやビューなどのスキーマ情報を見つけることができます。
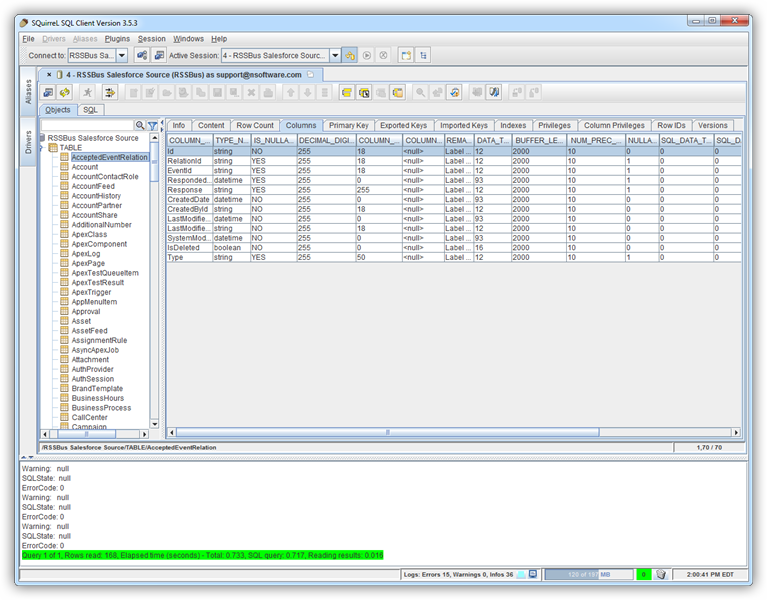
テーブルデータを表示するには[Objects]タブでテーブルを選択します。その後、テーブルデータが[Content]タブのグリッドに読み込まれます。
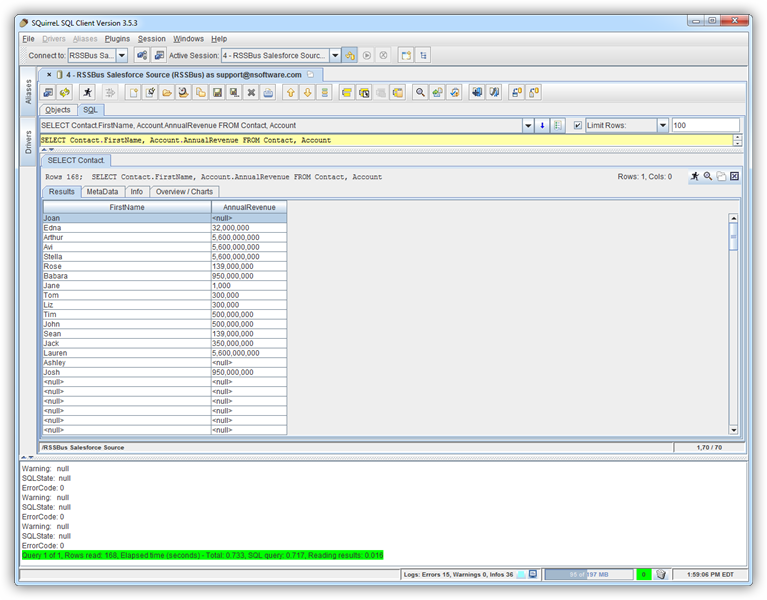
SQL クエリを実行するには、[SQL]タブにクエリを入力し、[Run SQL](ランナーアイコン)をクリックします。例:
SELECT City, Balance FROM Customers