ノーコードでクラウド上のデータとの連携を実現。
詳細はこちら →こんにちは!ウェブ担当の加藤です。マーケ関連のデータ分析や整備もやっています。
CData Connect Cloud を使って、SAP Lumira でSpark に基づくビジュアライゼーションを作成できます。CData Connect Cloud により、リアルタイムデータへの接続が可能になります。ダッシュボードとレポートはオンデマンドで更新できます。この記事では、常に最新であるグラフを作成する方法を説明します。
CData Connect Cloud はSpark データへのクラウドベースのOData インターフェースを提供し、SAP Lumira からSpark データへのリアルタイム連携を実現します。
以下のステップを実行するには、CData Connect Cloud のアカウントが必要になります。こちらから製品の詳しい情報とアカウント作成、30日間無償トライアルのご利用を開始できますので、ぜひご利用ください。
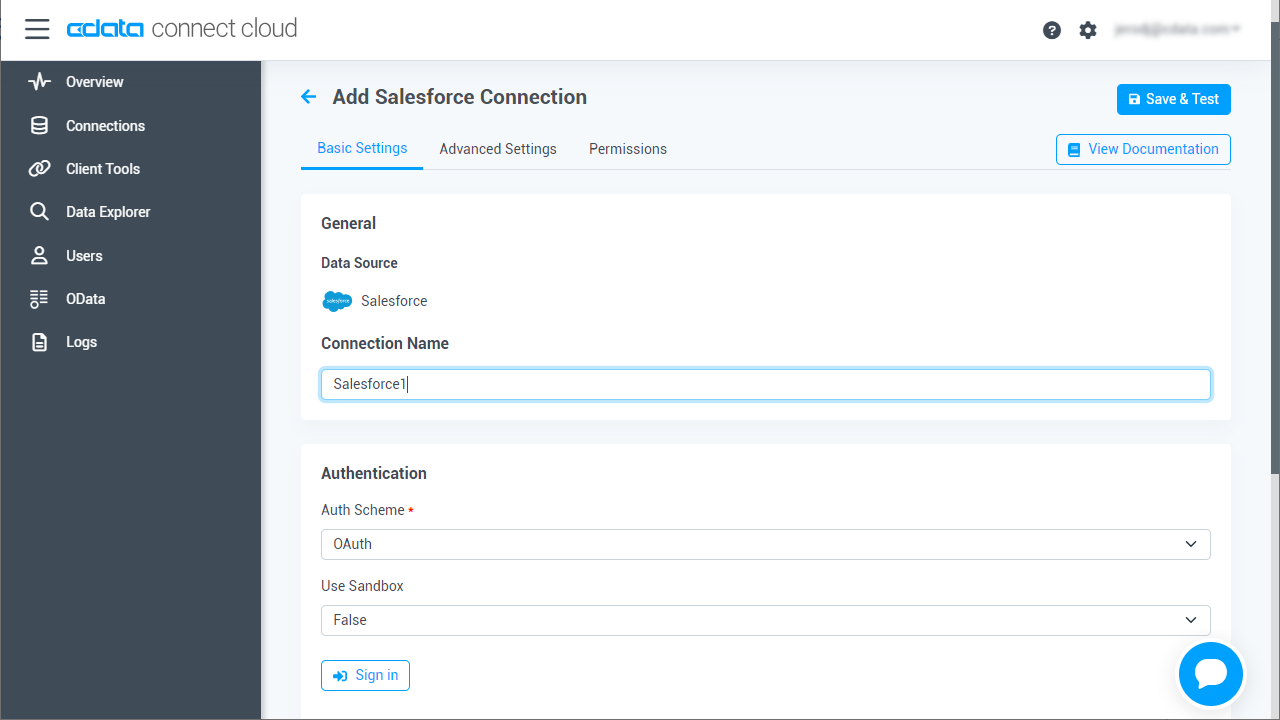
SAP Lumira でSpark データを操作するには、Connect Cloud からSpark に接続し、コネクションにユーザーアクセスを提供してSpark データのOData エンドポイントを作成する必要があります。
Spark に接続したら、目的のテーブルのOData エンドポイントを作成します。
必要であれば、Connect Cloud 経由でSpark に接続するユーザーを作成します。
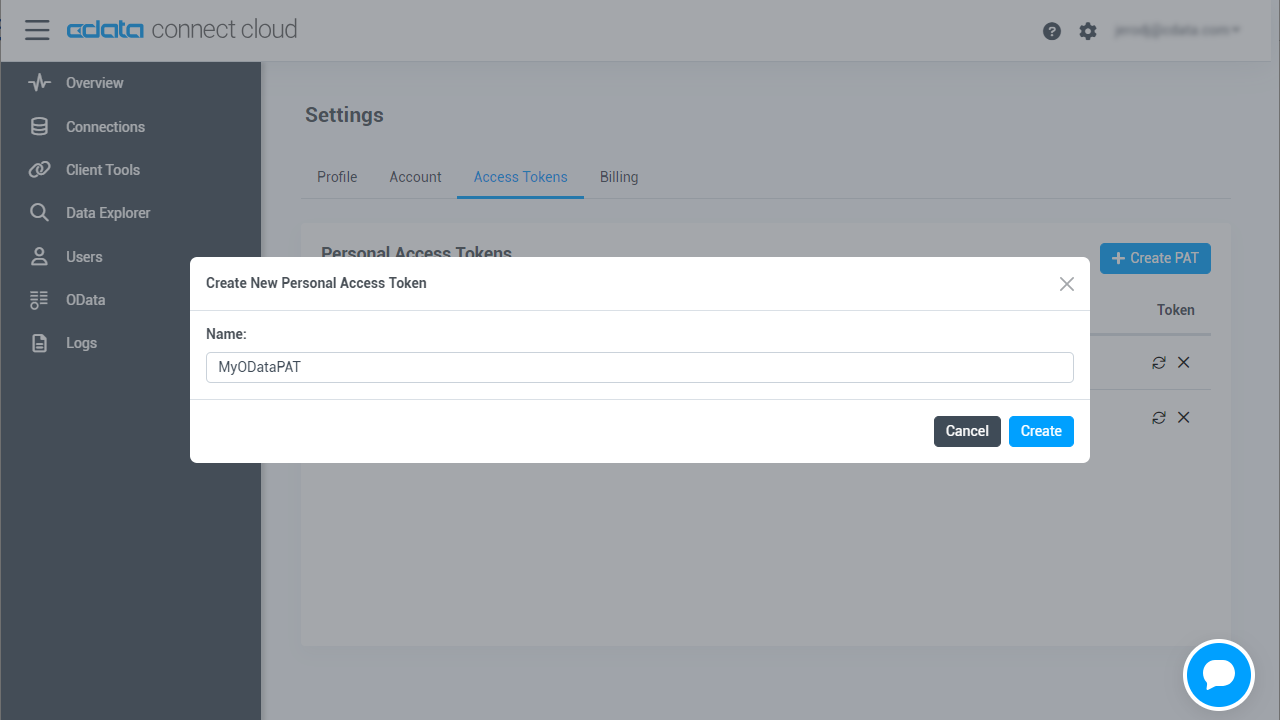
OAuth 認証をサポートしていないサービス、アプリケーション、プラットフォーム、またはフレームワークから接続する場合は、認証に使用するパーソナルアクセストークン(PAT)を作成できます。きめ細かなアクセス管理を行うために、サービスごとに個別のPAT を作成するのがベストプラクティスです。
CData Connect Cloud では、簡単なクリック操作ベースのインターフェースでデータソースに接続できます。
SparkSQL への接続を確立するには以下を指定します。
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。Note:必要な値は、「クラスター」に移動して目的のクラスターを選択し、 「Advanced Options」の下にある「JDBC/ODBC」タブを選択することで、Databricks インスタンスで見つけることができます。
Spark に接続したら、目的のテーブルのOData エンドポイントを作成します。
コネクションとOData エンドポイントを設定したら、SAP Lumira からSpark データに接続できます。
以下のステップに従って、Spark をSAP Lumira に取得します。SQL クエリを実行するか、UI を使用できます。
https://your-server:8032/api.rsc
ツリーでエンティティを選択するか、SQL クエリを入力します。この記事では、Spark Customers エンティティをインポートします。
[Connect]をクリックすると、SAP Lumira は対応するOData 要求を生成し、結果をメモリにロードします。その後、フィルタ、集計、要約関数など、SAP Lumira で使用可能な任意のデータ処理ツールを使用できます。
データをインポートした後、[Visualize]ルームでデータのビジュアライゼーションを作成できます。以下のステップに従って、基本グラフを作成します。
[Measures and Dimensions]ペインで、メジャーとディメンションを[Visualization Tools]ペインの[x-axis]フィールドと[y-axis]フィールドにドラッグします。SAP Lumira は、CData Connect Cloud のメタデータサービスからディメンションとメジャーを自動的に検出します。
デフォルトでは、SUM 関数はすべてのメジャーに適用されます。メジャーの横にある歯車のアイコンをクリックしてデフォルトの要約を変更します。