ノーコードでクラウド上のデータとの連携を実現。
詳細はこちら →Apache Spark ODBC Driver の30日間無償トライアルをダウンロード
30日間の無償トライアルへ製品の詳細
Apache Spark ODBC Driver は、ODBC 接続をサポートするさまざまなアプリケーションからApache Spark データへの接続を実現するパワフルなツールです。
標準SQL とSpark SQL をマッピングして、SQL-92 で直接Apache Spark にアクセス。
CData


こんにちは!ドライバー周りのヘルプドキュメントを担当している古川です。
SQL Gateway を使って、MySQL リモーティングサービスを作成し、Spark のMySQL Federated Table を構築できます。CData ODBC Driver for SparkSQL のMySQL インターフェースのdeamon になります。サービス起動後、MySQL のFEDERATED ストレージエンジンを使ってサーバーおよびテーブルを作成します。Spark データ をMySQL テーブルのように使いましょう。
If you have not already done so, provide values for the required connection properties in the data source name (DSN). You can use the built-in Microsoft ODBC Data Source Administrator to configure the DSN. This is also the last step of the driver installation. See the "Getting Started" chapter in the help documentation for a guide to using the Microsoft ODBC Data Source Administrator to create and configure a DSN.
SparkSQL への接続を確立するには以下を指定します。
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。Note:必要な値は、「クラスター」に移動して目的のクラスターを選択し、 「Advanced Options」の下にある「JDBC/ODBC」タブを選択することで、Databricks インスタンスで見つけることができます。
See the SQL Gateway Overview to set up connectivity to Spark データ as a virtual MySQL database. You will configure a MySQL remoting service that listens for MySQL requests from clients. The service can be configured in the SQL Gateway UI.
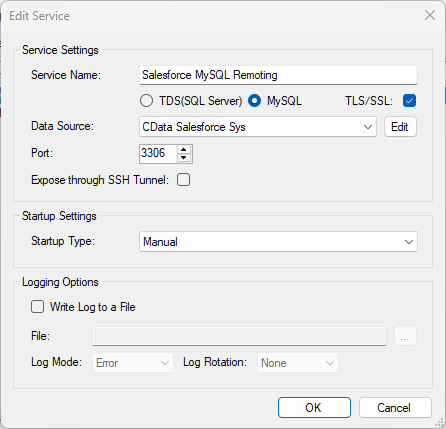
After you have configured and started the service, create a FEDERATED server to simplify the process of creating FEDERATED tables:
The following statement will create a FEDERATED server based on the ODBC Driver for SparkSQL. Note that the username and password of the FEDERATED server must match a user account you defined on the Users tab of the SQL Gateway.
CREATE SERVER fedSparkSQL FOREIGN DATA WRAPPER mysql OPTIONS (USER 'sql_gateway_user', PASSWORD 'sql_gateway_passwd', HOST 'sql_gateway_host', PORT ####, DATABASE 'CData SparkSQL Sys');
To create a FEDERATED table using our newly created server, use the CONNECTION keyword and pass the name of the FEDERATED server and the remote table (Customers). Refer to the following template for the statement to create a FEDERATED table:
CREATE TABLE fed_customers ( ..., city TYPE(LEN), balance TYPE(LEN), ..., ) ENGINE=FEDERATED DEFAULT CHARSET=latin1 CONNECTION='fedSparkSQL/customers';
NOTE: The table schema for the FEDERATED table must match the remote table schema exactly. You can always connect directly to the MySQL remoting service using any MySQL client and run a SHOW CREATE TABLE query to get the table schema.
You can now execute queries to the Spark FEDERATED tables from any tool that can connect to MySQL, which is particularly useful if you need to JOIN data from a local table with data from Spark. Refer to the following example:
SELECT fed_customers.city, local_table.custom_field FROM local_table JOIN fed_customers ON local_table.foreign_city = fed_customers.city;




