ノーコードでクラウド上のデータとの連携を実現。
詳細はこちら →Apache Spark ODBC Driver の30日間無償トライアルをダウンロード
30日間の無償トライアルへ製品の詳細
Apache Spark ODBC Driver は、ODBC 接続をサポートするさまざまなアプリケーションからApache Spark データへの接続を実現するパワフルなツールです。
標準SQL とSpark SQL をマッピングして、SQL-92 で直接Apache Spark にアクセス。
こんにちは!ドライバー周りのヘルプドキュメントを担当している古川です。
R スクリプトおよび 標準SQL を使ってSpark にアクセス。CData ODBC Driver for SparkSQL とRODBC package を使って、R でリモートSpark を利用できます。CData Driver を使うことで、オープンソースでポピュラーなR 言語のデータにアクセスできます。この記事では、ドライバーを使ってSpark にSQL クエリを実行する方法、およびR でSpark をビジュアライズする方法について説明します。
CData ODBC ドライバは、以下のような特徴を持ったリアルタイムデータ連携ソリューションです。
CData ODBC ドライバでは、1.データソースとしてSpark の接続を設定、2.R 側でODBC Driver との接続を設定、という2つのステップだけでデータソースに接続できます。以下に具体的な設定手順を説明します。
まずは、本記事右側のサイドバーからSparkSQL ODBC Driver の無償トライアルをダウンロード・インストールしてください。30日間無償で、製品版の全機能が使用できます。
接続プロパティの指定がまだの場合は、まずODBC DSN (データソース名)で接続設定を行います。これはドライバーのインストール時に自動的に立ち上がります。Microsoft ODBC データソースアドミニストレーターを使ってODBC DSN を作成および設定できます。
SparkSQL への接続を確立するには以下を指定します。
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。Note:必要な値は、「クラスター」に移動して目的のクラスターを選択し、 「Advanced Options」の下にある「JDBC/ODBC」タブを選択することで、Databricks インスタンスで見つけることができます。
ドライバーを使うにはRODBC パッケージをダウンロードします。RStudio で[Tools]>[Install Packages]をクリックし、RODBC を[Packages]ボックスに入力します。
RODBC パッケージをインストールしたら、次のコードを入力してパッケージをロードします。
library(RODBC)
次のコードを使ってR のDSN に接続できます:
conn <- odbcConnect("CData Spark Source")
ドライバーはSpark API をリレーショナルデータベース、ビュー、ストアドプロシージャとしてモデル化します。次のコードを使ってテーブルリストを検出します。
sqlTables(conn)
sqlQuery 関数を使ってSpark API がサポートするすべてのSQL クエリを実行します。
customers <- sqlQuery(conn, "SELECT City, Balance FROM Customers", believeNRows=FALSE, rows_at_time=1)
次のコマンドを使って、結果を[data viewer]ウィンドウで見ることができます。
View(customers)
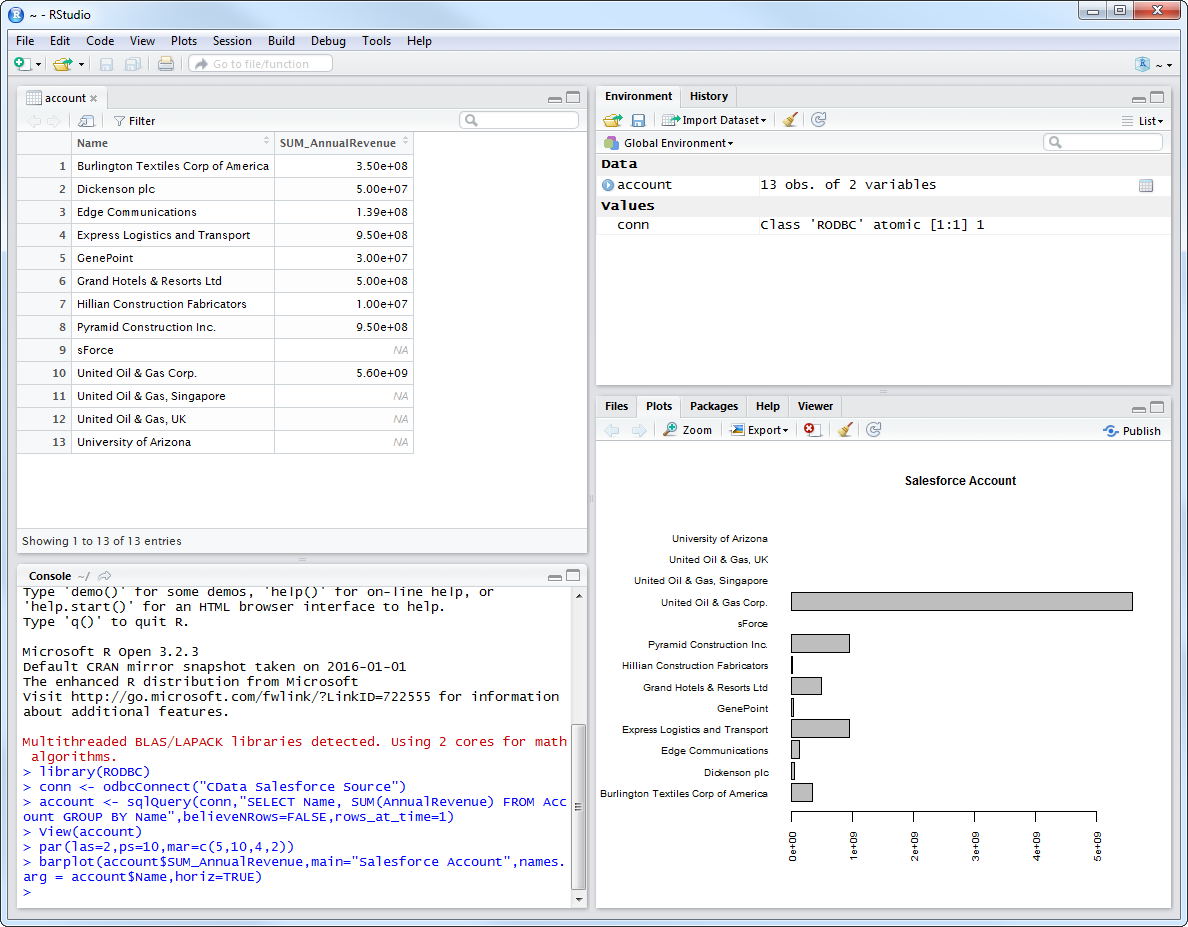
これで、CRAN レポジトリで利用可能なあらゆるデータビジュアライゼーションパッケージを使ってSpark を分析できます。ビルトインのbar plot 関数を使って簡単なバーを作成できます:
par(las=2,ps=10,mar=c(5,15,4,2))
barplot(customers$Balance, main="Spark Customers", names.arg = customers$City, horiz=TRUE)
このようにCData ODBC ドライバと併用することで、270を超えるSaaS、NoSQL データをコーディングなしで扱うことができます。30日の無償評価版が利用できますので、ぜひ自社で使っているクラウドサービスやNoSQL と合わせて活用してみてください。
CData ODBC ドライバは日本のユーザー向けに、UI の日本語化、ドキュメントの日本語化、日本語でのテクニカルサポートを提供しています。