ノーコードでクラウド上のデータとの連携を実現。
詳細はこちら →Apache Spark ODBC Driver の30日間無償トライアルをダウンロード
30日間の無償トライアルへ製品の詳細
Apache Spark ODBC Driver は、ODBC 接続をサポートするさまざまなアプリケーションからApache Spark データへの接続を実現するパワフルなツールです。
標準SQL とSpark SQL をマッピングして、SQL-92 で直接Apache Spark にアクセス。
CData


こんにちは!ドライバー周りのヘルプドキュメントを担当している古川です。
Tableau Bridge は、データソースとのライブ接続を維持したままTableau Cloud にダッシュバードをパブリッシュ可能にします。本記事では、Tableau Bridge を使って、Spark データに連携するワークブックをデータ更新可能な状態でパブリッシュする方法を説明します。
CData ODBC drivers は、Tableau Cloud からSpark データにノーコードでのアクセスを実現します。ドライバーにはパフォーマンスを向上させるための効率的なデータ処理が組み込まれています。Spark からTableau Cloud に複雑なSQlクエリを発行すると、ドライバーはファイルタリング、集計などのクエリオペレーションでデータソース側でサポートされているものはSpark 側に、JOIN などのサポートされていないクエリはドライバーの内部SQL エンジンにて処理を行います。また、動的なメタデータクエリ機能が実装されており、Tableau からノーコードでSpark データのネイティブなデータ型を使ってデータを効率的に分析できます。
CData ODBC ドライバは、以下のような特徴を持ったリアルタイムデータ連携ソリューションです。
CData ODBC ドライバでは、1.データソースとしてSpark の接続を設定、2.Tableau Bridge 側でODBC Driver との接続を設定、という2つのステップだけでデータソースに接続できます。以下に具体的な設定手順を説明します。
まずは、本記事右側のサイドバーからSparkSQL ODBC Driver の無償トライアルをダウンロード・インストールしてください。30日間無償で、製品版の全機能が使用できます。
接続プロパティの指定がまだの場合は、DSN (データソース名)で行います。Microsoft ODBC データソースアドミニストレーターを使ってODBC DSN を作成および設定できます。一般的な接続プロパティは以下のとおりです:
SparkSQL への接続を確立するには以下を指定します。
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。Note:必要な値は、「クラスター」に移動して目的のクラスターを選択し、 「Advanced Options」の下にある「JDBC/ODBC」タブを選択することで、Databricks インスタンスで見つけることができます。
DSN を設定する際には、Max Rows プロパティを設定することをお勧めします。これにより取得される行数が制限され、パフォーマンスを向上させます。
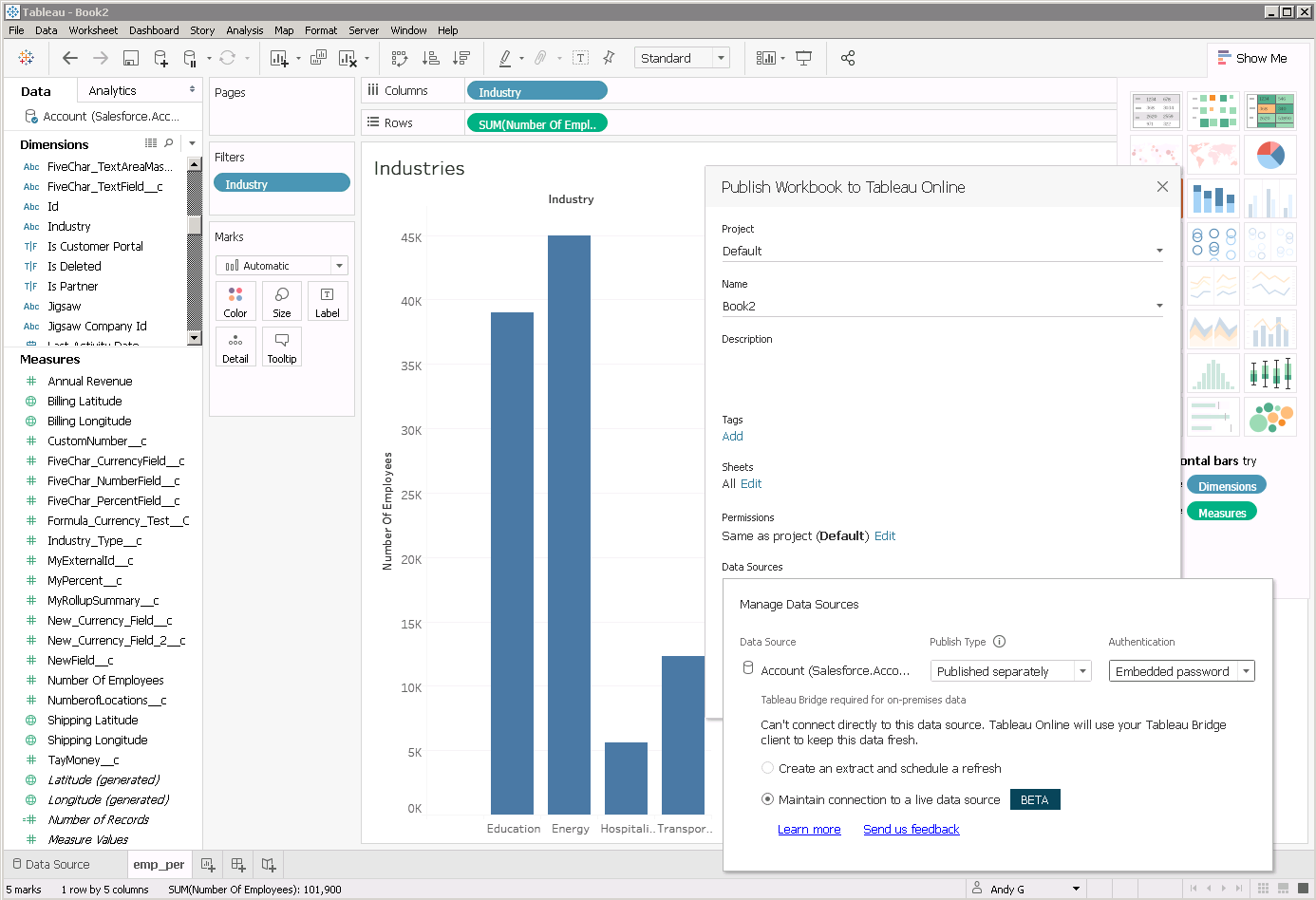
Tableau Bridge とTabelau Online 両方のデータ接続設定が完了したら、Tableau Cloud にワークブックをパブリッシュしましょう。 [サーバー]メニューから[ワークブックのパブリッシュ]をクリックし、ワークブックを指定します。
公開するワークブックを選択したら、公開設定でCData ODBC Driver for Spark がワークブックに個別のリアルタイムデータソースとして含まれるようにします。
パブリッシュされたワークブックは、[更新]ボタンを押すことでSpark データを更新することができます。
このようにCData ODBC ドライバと併用することで、270を超えるSaaS、NoSQL データをコーディングなしで扱うことができます。30日の無償評価版が利用できますので、ぜひ自社で使っているクラウドサービスやNoSQL と合わせて活用してみてください。
CData ODBC ドライバは日本のユーザー向けに、UI の日本語化、ドキュメントの日本語化、日本語でのテクニカルサポートを提供しています。