Discover how a bimodal integration strategy can address the major data management challenges facing your organization today.
Get the Report →




Extending the AWS Ecosystem with Universal Data Access
Amazon Web Services (AWS) helps organizations host and manage their data processes, like building data visualizations and performing ETL tasks. At CData, we make it easy to connect AWS Services with heterogeneous business applications and distributed data stores to ultimately help businesses develop a more holistic analysis of their data.
With CData's comprehensive connectivity between AWS and 150+ SaaS, Big Data, and NoSQL enterprise data sources, you can:
- Connect pure cloud analytics like Amazon QuickSight with real-time data from any application through CData Cloud Cloud, a cloud-to-cloud data access tool.
- Design automated data pipelines that sync data across applications and AWS services using CData Sync.
- Create serverless on-demand processes to move data between the cloud and any of the 150+ data sources we support using AWS Glue and our JDBC Drivers.
This post briefly walks through the three processes above. For a deeper dive, follow the links to our related Knowledge Base articles.
NetSuite Data in Amazon QuickSight through Cloud Hub
Connecting to and visualizing SaaS, big data, or NoSQL data in Cloud Hub can be done in 4 steps.
1. Create a Virtual Database for NetSuite
In the MySQL client of your choice, connect to your Cloud Hub instance and create a new virtual database:
CREATE DATABASE netsuite_db
DRIVER = "NetSuite",
DBURL = "User=email@domain.com;Password=*******;AccountId=XABC123456;";
2. Connect to the CData Cloud Hub
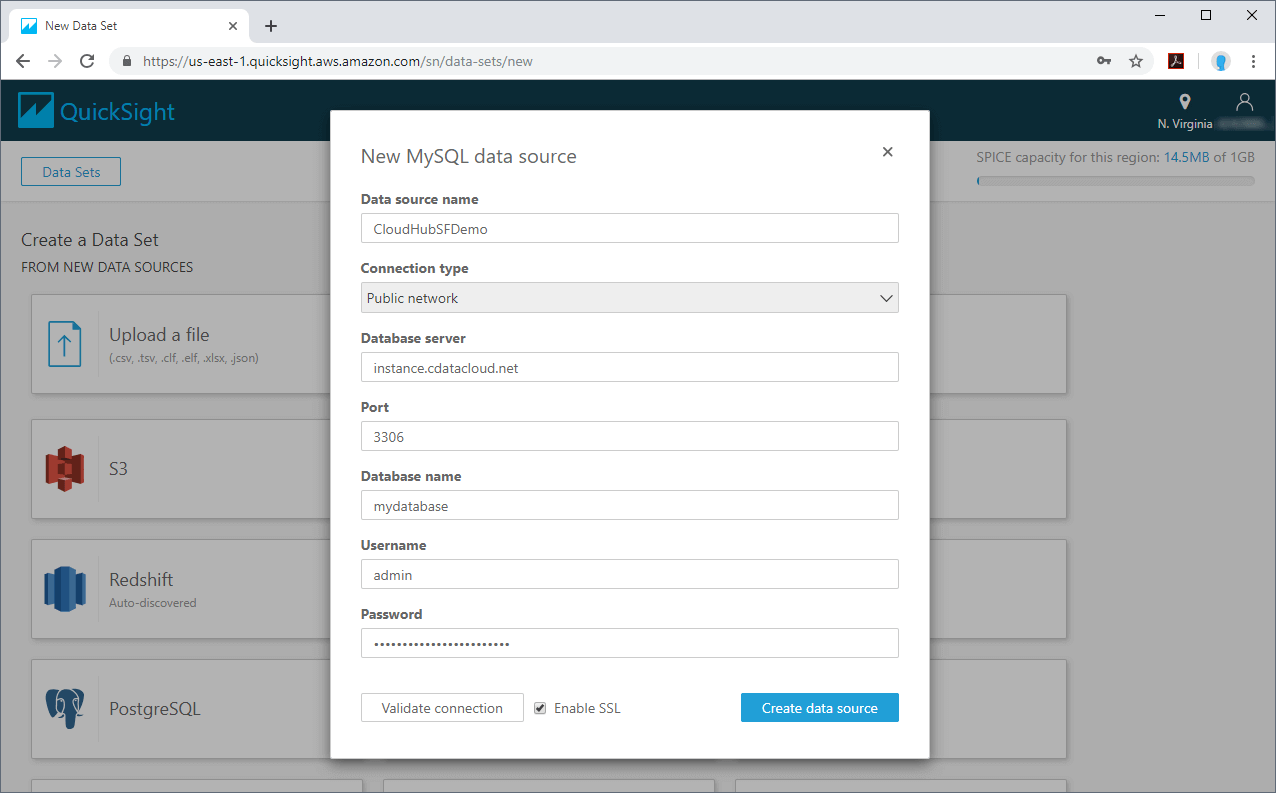
3. Select Data to Import into SPICE
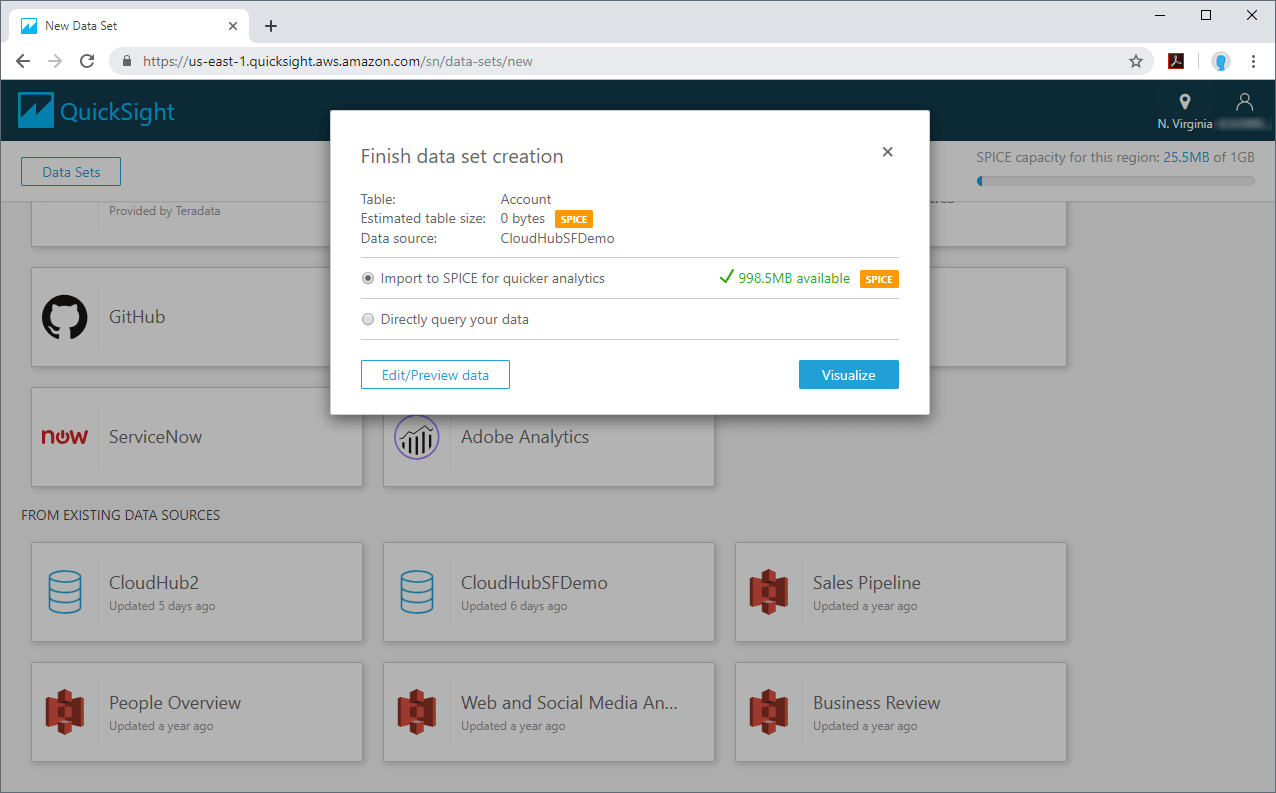
4. Build Visualizations and Dashboards
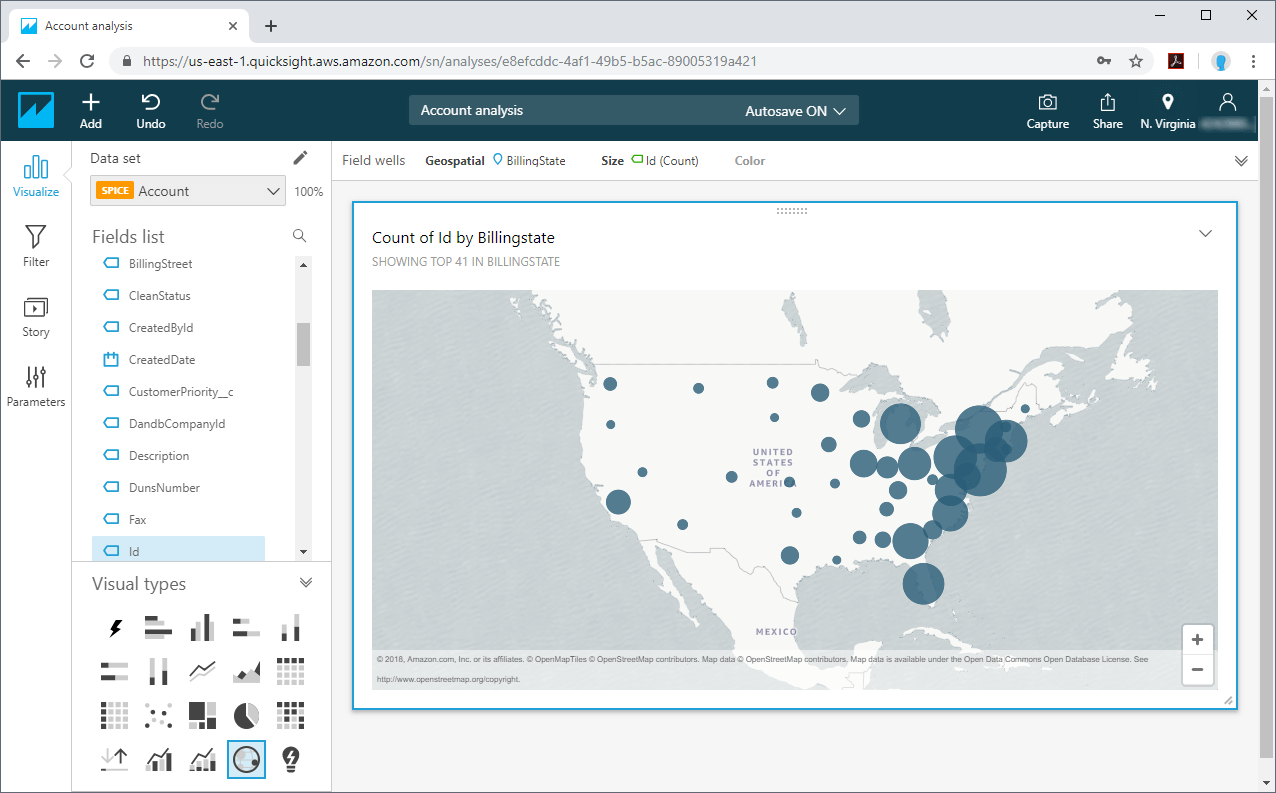
Read the Full Article
For a detailed walk-through of using the CData Cloud Hub to connect to live NetSuite data from Amazon QuickSight, read our Knowledge Base article.
Replicate Dynamics CRM Data to Amazon Redshift
Easily replicate your Dynamics CRM Data to an Amazon Redshift instance with the CData Sync point-and-click interface.
1. Connect to Dynamics CRM
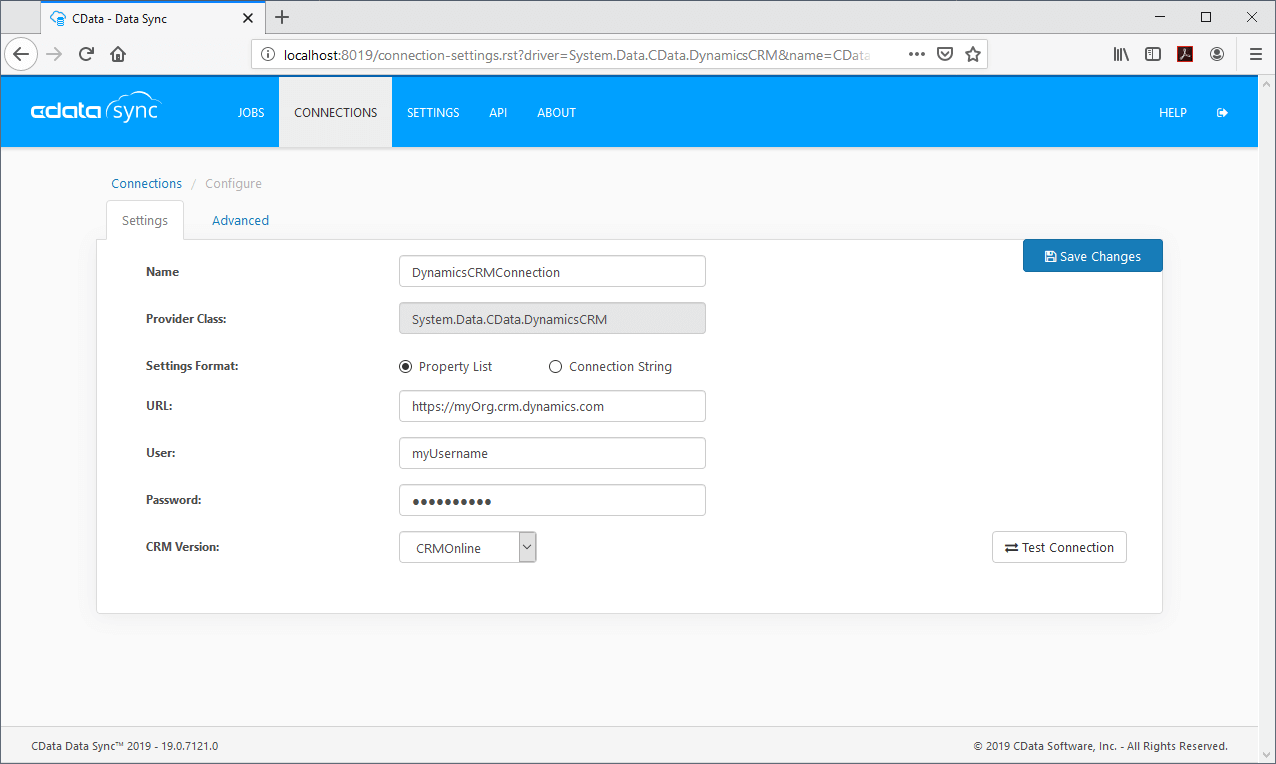
2. Connect to the Redshift Database
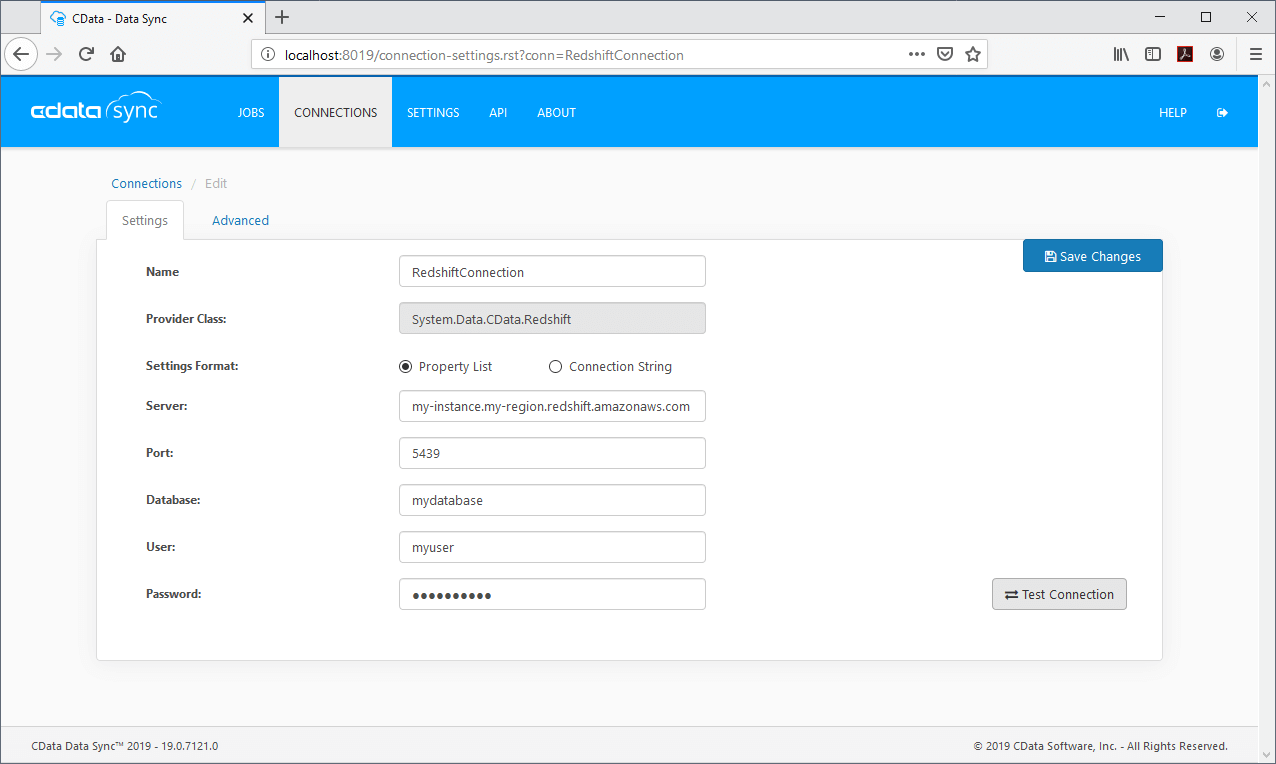
3. Configure the Replication Job
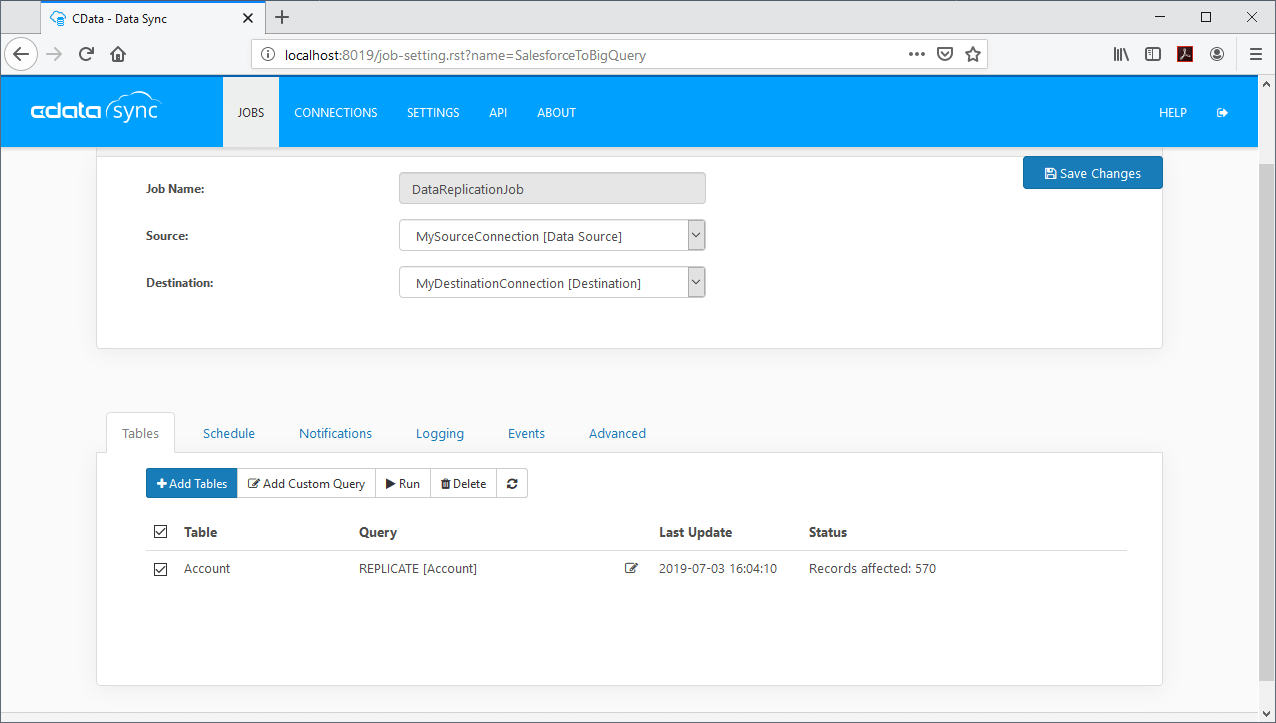
Check out our Knowledge Base article for a detailed look of using CData Sync to replicate Dynamics CRM data to an Amazon Redshift instance.
Salesforce Data in AWS Glue
Follow the steps below to connect to your Salesforce data in AWS Glue jobs using CData JDBC Drivers.
1. Upload the JDBC Driver to S3
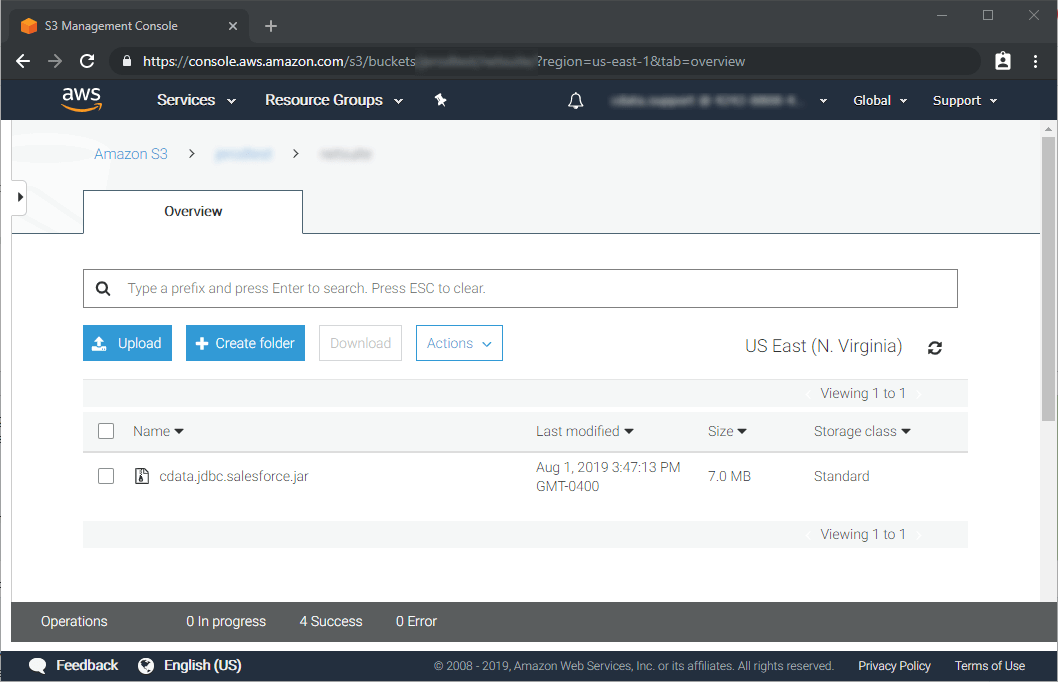
2. Configure the Glue Job
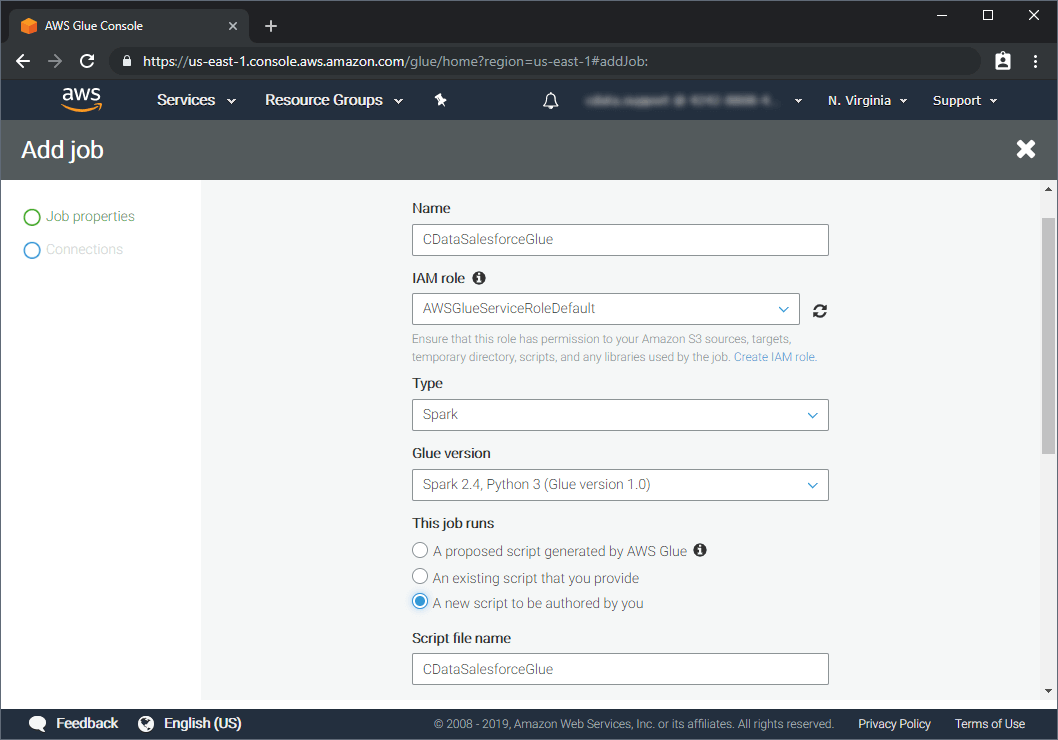
3. Write the Glue Script
...
## Use the CData JDBC driver to read Salesforce data
## from the Account table into a DataFrame
## Note the populated JDBC URL and driver class name
jdbc_url = "jdbc:salesforce:" +
"RTK=5246...;" +
"User=username@domain.com;" +
"Password=******;" +
"SecurityToken=Your_Security_Token";
class_name = "cdata.jdbc.salesforce.SalesforceDriver";
source_df = sparkSession.read.format("jdbc")
.option("url",jdbc_url)
.option("dbtable","Account")
.option("driver",class_name)
.load()
...
4. Run the Glue Job
With the script written, we are ready to run the Glue job. Click Run Job and wait for the extract/load to complete. You can view the status of the job from the Jobs page in the AWS Glue Console.
For a step-by-step explanation of connecting to Salesforce in AWS Glue jobs through JDBC Drivers hosted in Amazon S3, read our Knowledge Base article.
Make the Most of Amazon Web Services
With CData connectivity solutions you are getting high-performance client libraries and applications that help you maximize your investment in Amazon Web Services. Whether you use CData COnnect Cloud to see your data in Amazon QuickSight, upload CData JDBC Drivers to S3 to access live data from AWS Glue, or automate and customize your data replication with CData Sync, you will capitalize on the speed and utility of Amazon Web services. Download a free trial of any of our products to get started and reach out to our world-class Support Team if you have any questions.
Data Connectors
ETL/ ELT Solutions
Cloud & API Connectivity
OEM & Custom Drivers