Discover how a bimodal integration strategy can address the major data management challenges facing your organization today.
Get the Report →




Extend Databricks Connectivity with the CData JDBC Drivers

Databricks is a cloud-based service that provides data processing capabilities through Apache Spark. When paired with the CData JDBC Drivers, customers can use Databricks to perform data engineering and data science on live data from more than 180 SaaS, Big Data, and NoSQL data sources.
This post provides a brief overview of connecting to and processing Salesforce data in Databricks, with links to more information and a full walk-through.
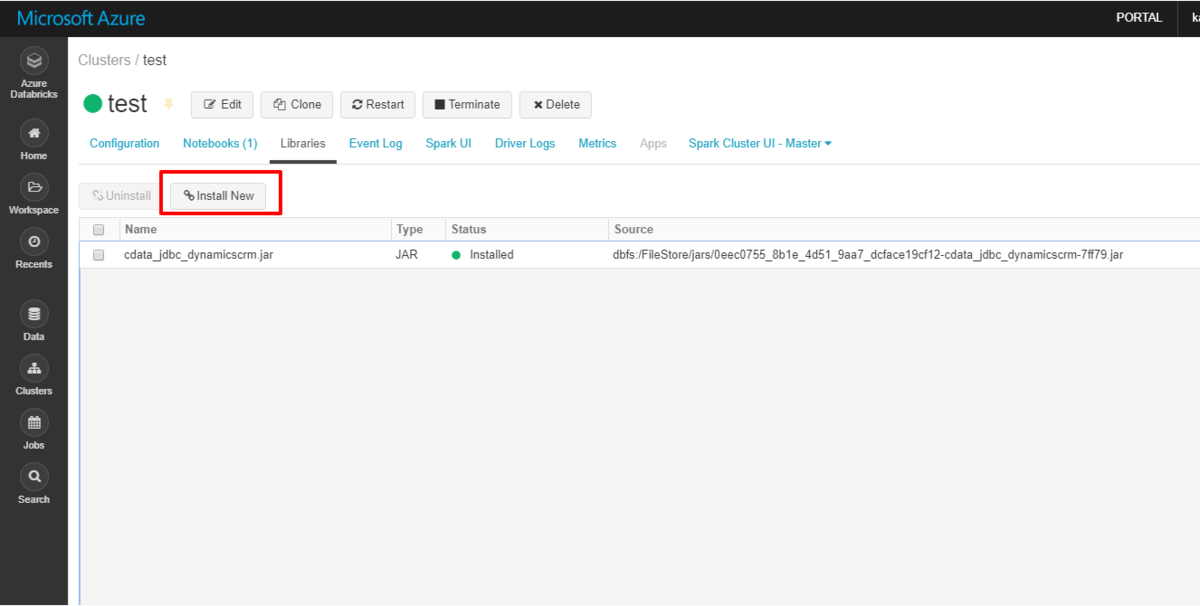
Install the CData JDBC Driver on Databricks
Start by installing the CData JDBC Driver on your Azure cluster.
Connect to Salesforce
Connect to Salesforce by referencing the class for the JDBC Driver and constructing a connection string for the JDBC URL.
driver = "cdata.jdbc.salesforce.SalesforceDriver" url = "jdbc:salesforce:User=XXXX;Password=XXXX;SecurityToken=XXXX;RTK=XXXX;"
Read Salesforce Data
Once the connection is configured, load the Salesforce data as a dataframe using the CData JDBC Driver and the connection information.
remote_table = spark.read.format ( "jdbc" ) \ .option ( "driver" , driver) \ .option ( "url" , url) \ .option ( "dbtable" , table) \ .load ()
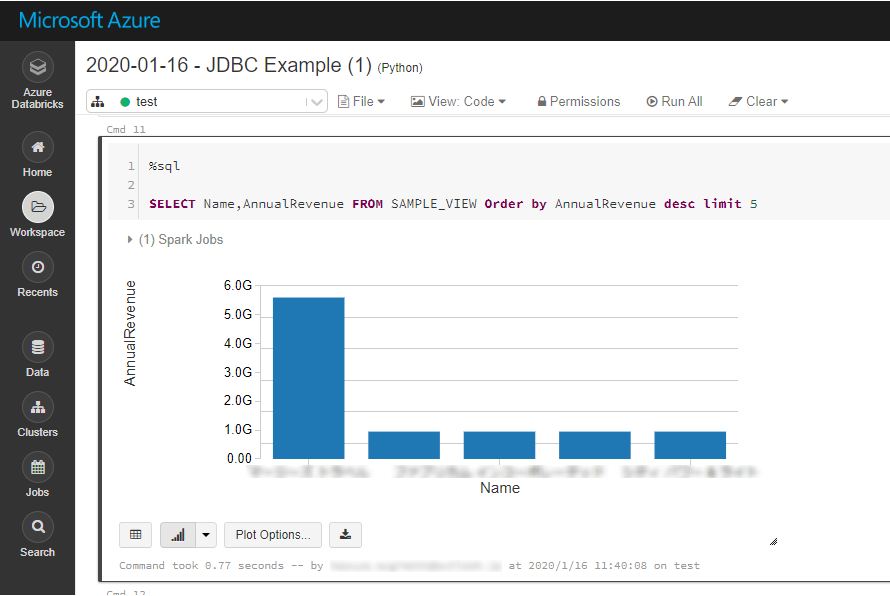
Analyze Salesforce Data with SparkSQL
Register the loaded data as a Temp View for use in visualizations and reports.
Process & Analyze Live Data in Databricks
CData JDBC Drivers give you database interfaces for all of your enterprise data, no matter where it is. For more information about our JDBC Drivers and to download a free trial, refer to our JDBC Driver page. As always, our world-class Support Team is here to answer any questions you have.
Data Connectors
ETL/ ELT Solutions
Cloud & API Connectivity
OEM & Custom Drivers