ノーコードでクラウド上のデータとの連携を実現。
詳細はこちら →





ABBYY FlexiCapture でOCR した結果をSalesforce に書き込む方法:CData Salesforce ODBC Driver
こんにちは。CData Software Japan リードエンジニアの杉本です。
今回はOCR に関するソフトウェアで世界的に有名なABBYY のFlexiCapture とCData ODBC Driver を組み合わせて、OCRした結果をSalesforce に書き込む方法を紹介したいと思います。
ABBYY FlexiCapture とは?
ABBYY 社が提供するAI OCRを用いた帳票処理プラットフォームです。
https://www.abbyy.com/ja/flexicapture/
ABBYY FlexiCapture にはPDFや画像データを読み込んでOCR 処理を行う機能が充実しているのはもちろんのこと、そのOCR した結果を様々なサービス・ワークフローに繋げて統合する機能も多数備えています。
https://www.abbyy.com/ja/flexicapture/how-it-works/

デフォルトではODBC 対応のデータベースとして、Oracle やMicrosoft SQL Server、Access などが挙げられていますが、この機能とCData ODBC Driver を組み合わせることにより、RDBだけでなくSalesforce やKintone など様々なクラウドサービスへの連携も可能になります。
今回はこの機能とCData Salesforce ODBC Driver を組み合わせてOCR した結果をSalesforce に取り込んでみたいと思います。
対象とする文書定義
ABBYY FlexiCapture では予めOCR を行うための設定、文書定義と呼ばれるものを構成しておく必要があります。
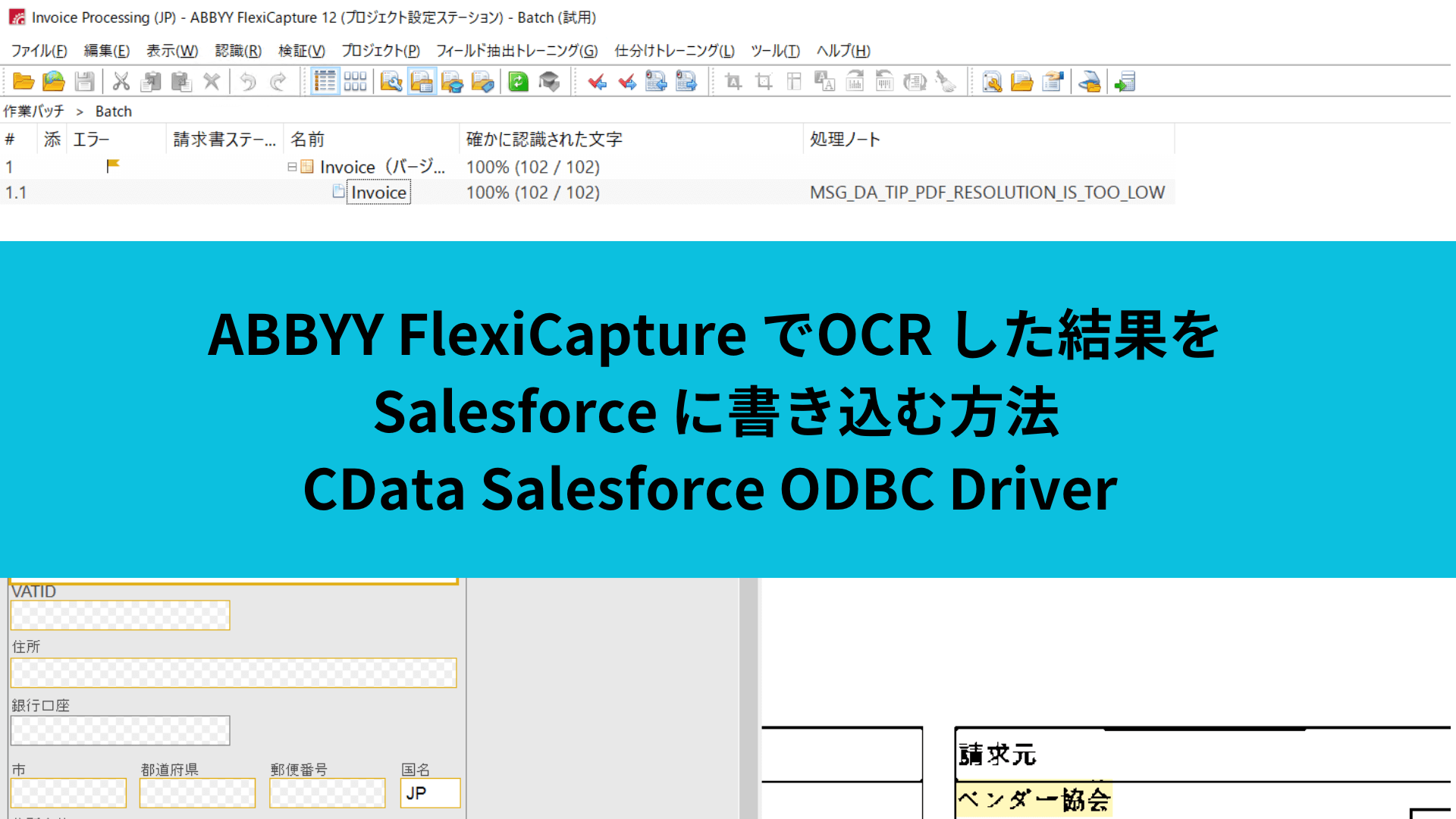
今回は予めABBYY FlexiCapture 日本語版に含まれているTemplateProjectsの請求書(Invoice)のサンプルを利用してみました。
以下のような請求書の画像からOCR した結果の「請求元」情報をSalesforce に取り込んでみたいと思います。
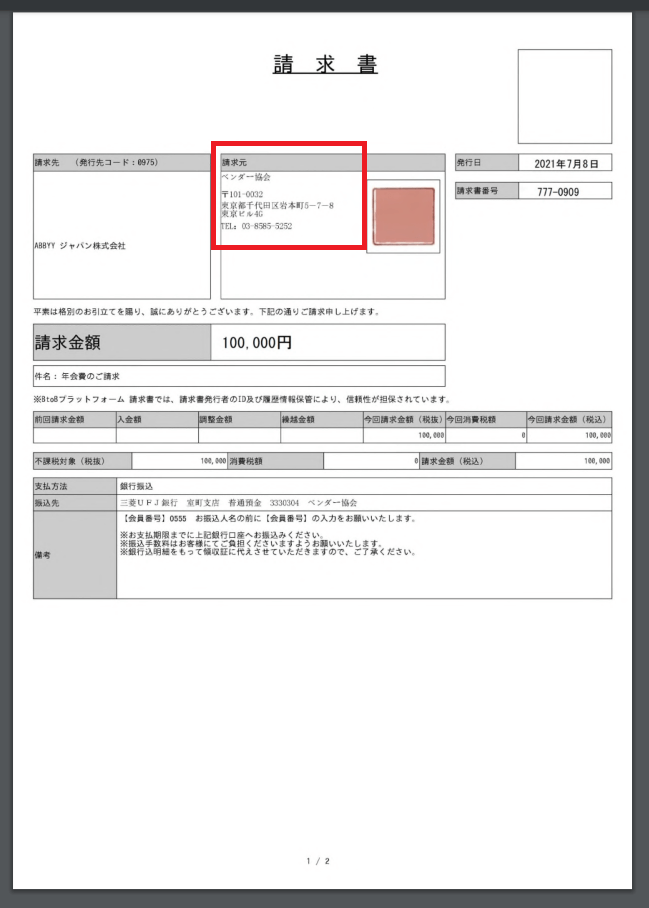
CData Salesforce ODBC Driverのインストール・セットアップ
最初に CData Salesforce ODBC Driverを対象のマシンにインストール・セットアップします。 CData Salesforce ODBC Driver は以下のURLから30日間のトライアル版が入手できます。
https://www.cdata.com/jp/drivers/salesforce/odbc/
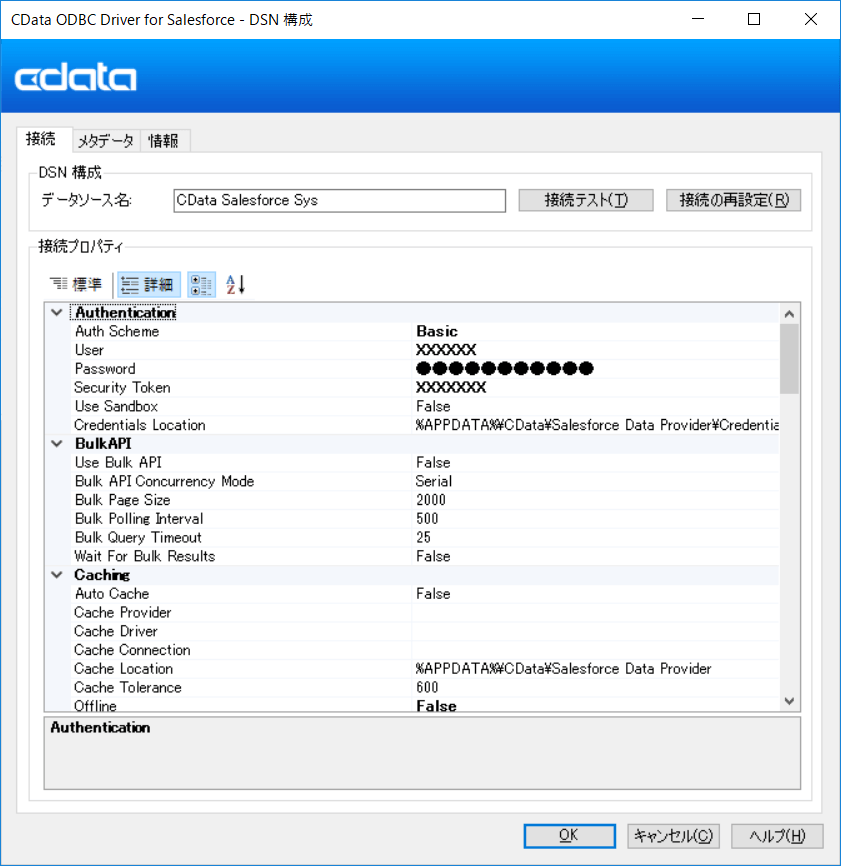
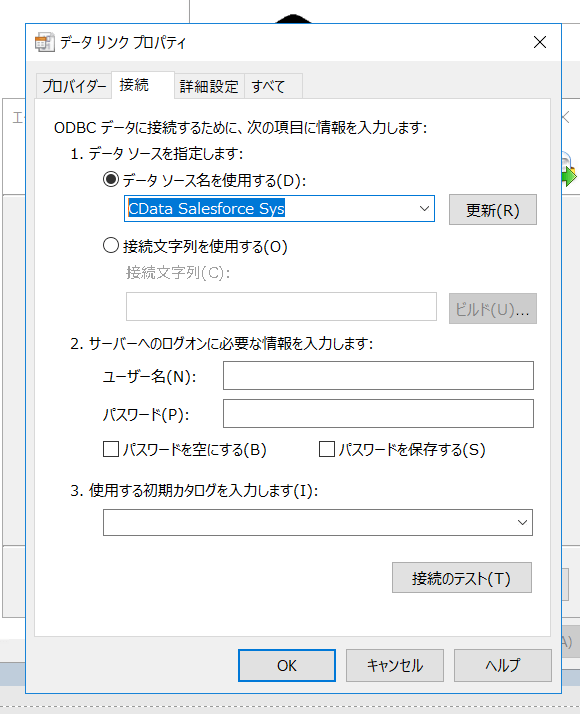
セットアップ完了後、接続設定画面が立ち上がります。下記の項目に Salesforce への接続情報を設定します。
|
Salesforceの接続情報 |
設定項目 |
備考 |
|
ユーザID |
User |
|
|
パスワード |
Password |
|
|
セキュリティートークン |
Security Token |
取得方法はこちら |
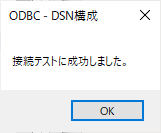
「接続のテスト」ボタンをクリックします。下記のようなダイアログが表示されれば成功です。「接続ウィザード」の「OK」ボタンをクリックして保存します。
文書定義エディタを立ち上げる
それではABBYY FlexiCapture に移動し、ODBC との連携設定を追加していきましょう。
今回は前述の通りABBYY FlexiCapture のTemplateProjects に含まれる「Invoice Processing(JP)」を使います。
以下のABBYY FlexiCapture のプロジェクトを立ち上げましょう。
プロジェクト設定ステーションが機動したら「プロジェクト」→「文章定義」に移動し
「Invoice」のプロジェクトを編集します。
文書定義にエクスポート設定を追加
文書定義エディタを立ち上げたら「文書定義」→「エクスポート設定」に移動します。
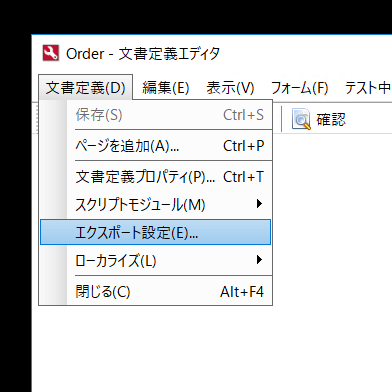
この画面からOCR した結果のデータをどのように出力するのか? を設定できます。デフォルトではCSV 出力のみが定義されているので、ここのODBC 経由でデータをエクスポートする設定を追加しましょう。
まず「追加」ボタンをクリックします。
エクスポート元ウィザードが立ち上がるのでタイプで「ODBC 互換データベースにエクスポート」を選択し次へ移動します。
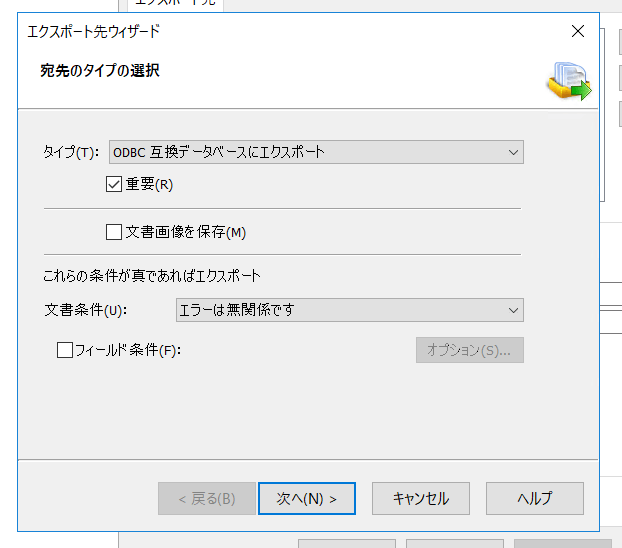
画像ファイルのエクスポート設定は、SalesforceなどのクラウドサービスではRDBのように画像を直接フィールドに書き込むことはできないため、「画像をフォルダに保存」を選択します。
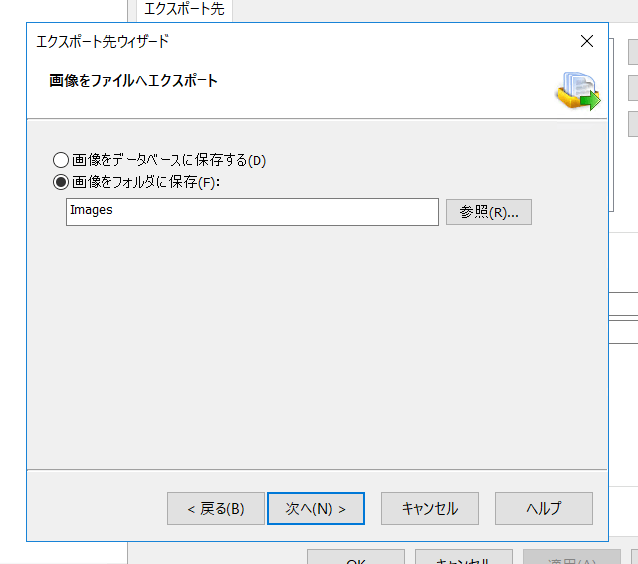
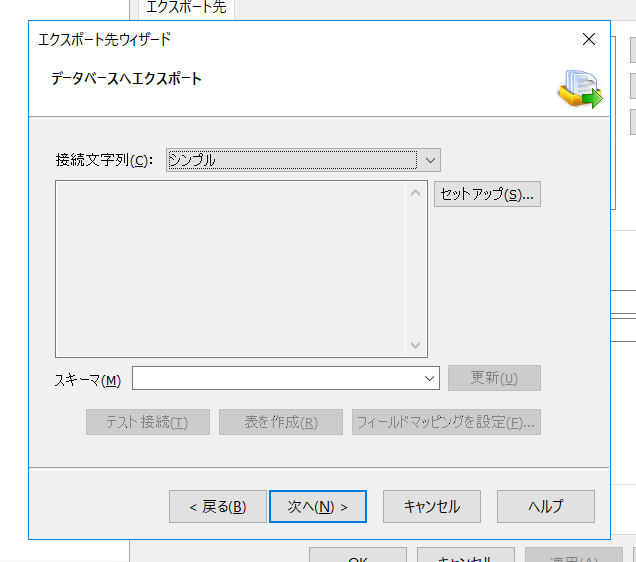
続いて「セットアップ」をクリックしODBC の接続設定を行います。
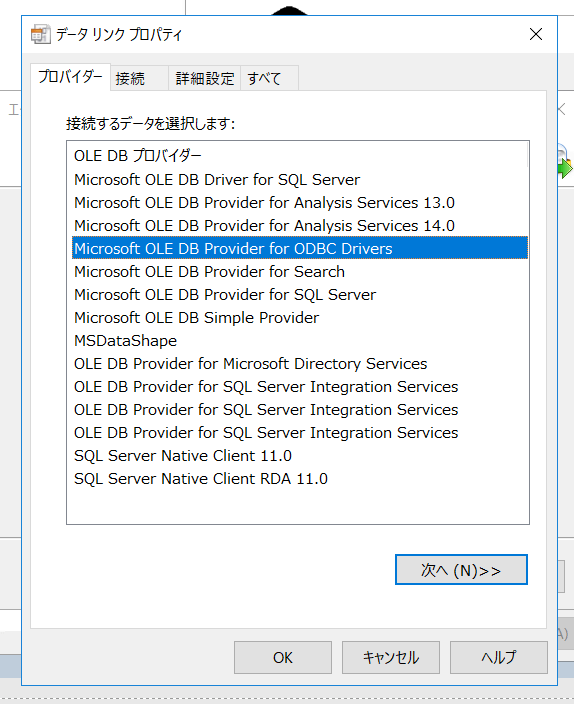
プロバイダーの一覧から「Microsoft OLE DB Provider for ODBC Drivers」を選択し、「次へ」移動します。
「データソース名を使用する」から先程構成したODBC DSNを選択します。なお、FlexiCapture はバックグラウンドのジョブとして動作するため、実行ユーザーが異なる場合があります。そのためシステムDSN を選択しておくと良いでしょう。
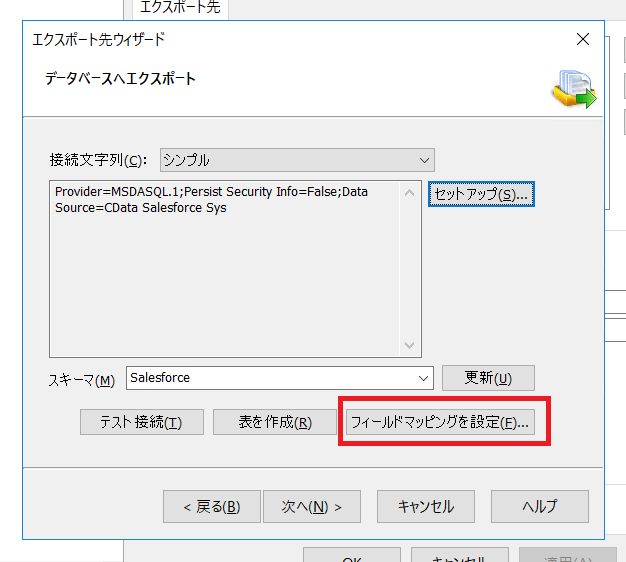
続いてフィードマッピングを構成していきます。なお、CData Driver は「表の作成」をサポートしていないため、基本的に既存のオブジェクトに対してマッピングして使うイメージになります。
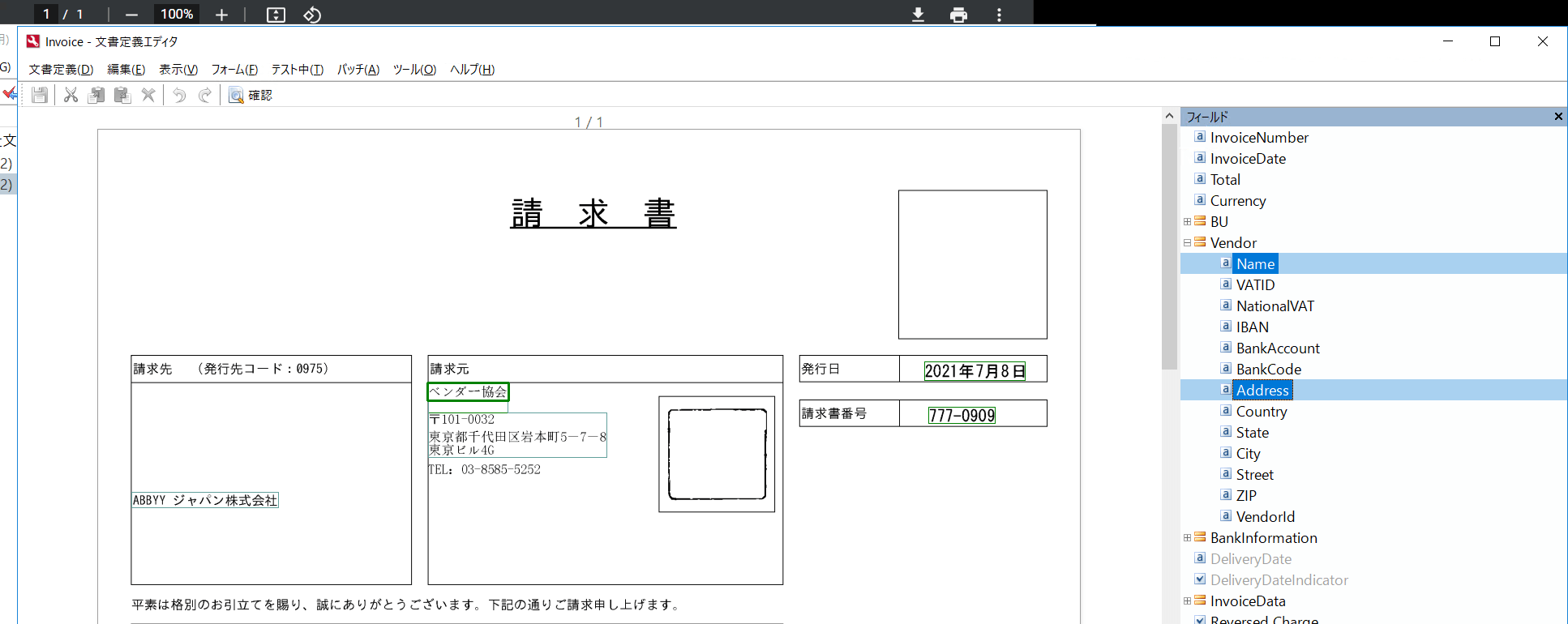
今回はテストとしてシンプルにデータを書き込んでみます。以下のVendor 情報に含まれるName、Addressを
以下のようにSalesforce のAccount に含まれるNameなどのフィールドにマッピングします。
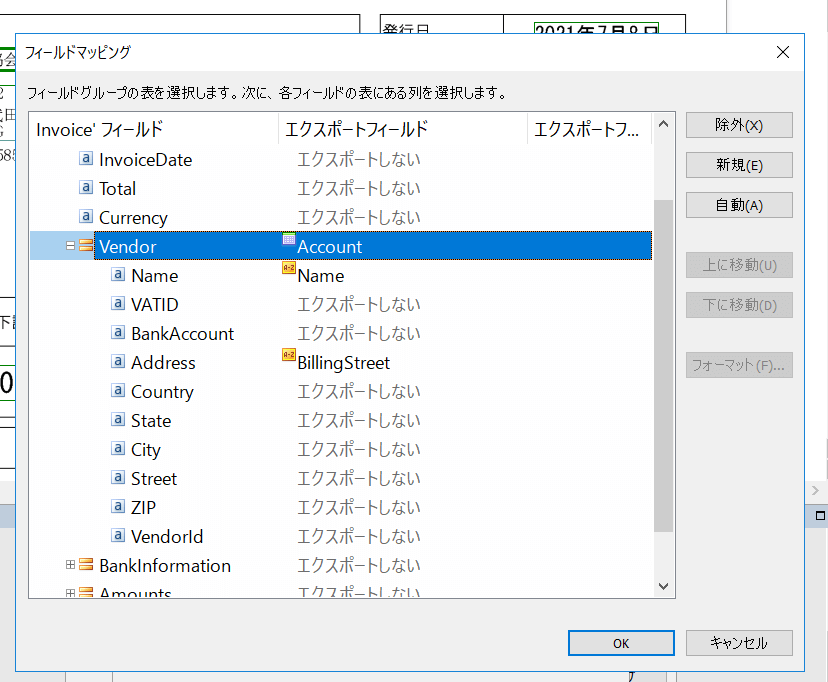
必要な項目のマッピングが終わったらエクスポートの設定に任意の名前を入力し「完了」をクリックします。
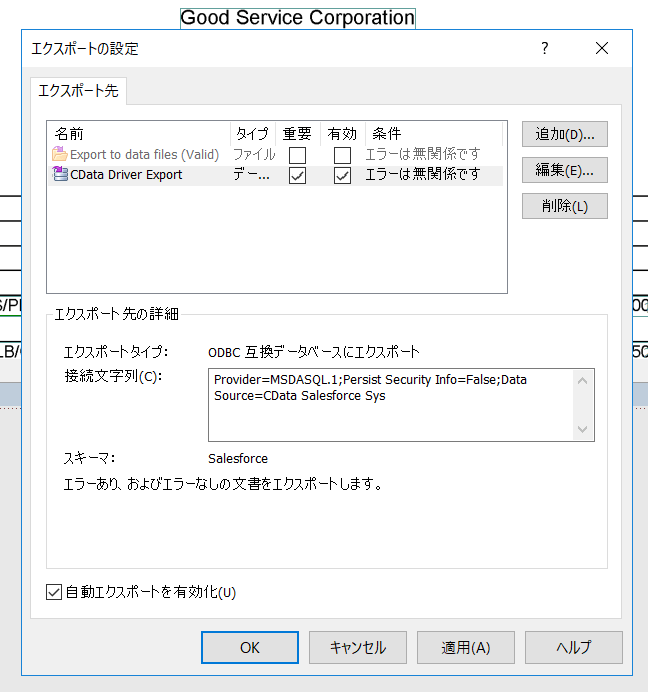
エクスポート設定の追加が完了したら、対象のエクスポートの設定の「有効」と「自動エクスポートを有効化」にチェックを入れて「OK」をクリックします。
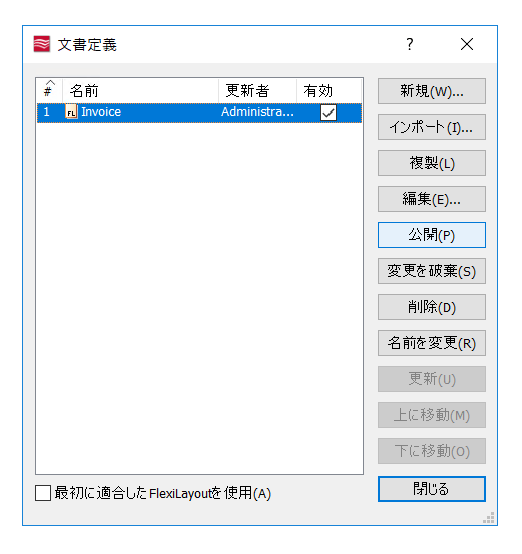
「エクスポートの設定」を変更したら、対象の文書定義を公開しましょう。
これでOCRした結果がODBC 経由でSalesforce に書き込まれるようになります。
テスト実行
それでは、実際にOCR した結果がSalesforce に取り込まれるかどうか、テスト実行してみましょう。
※ちなみにこのTemplateProjects にはデフォルトで様々なルールが設定されていますが、テスト実行のためにそれらは解除しています。
適当な作業バッチを作成し、画像を読み込みます。
処理が正常に完了すると、読込結果を以下のように確認できます。
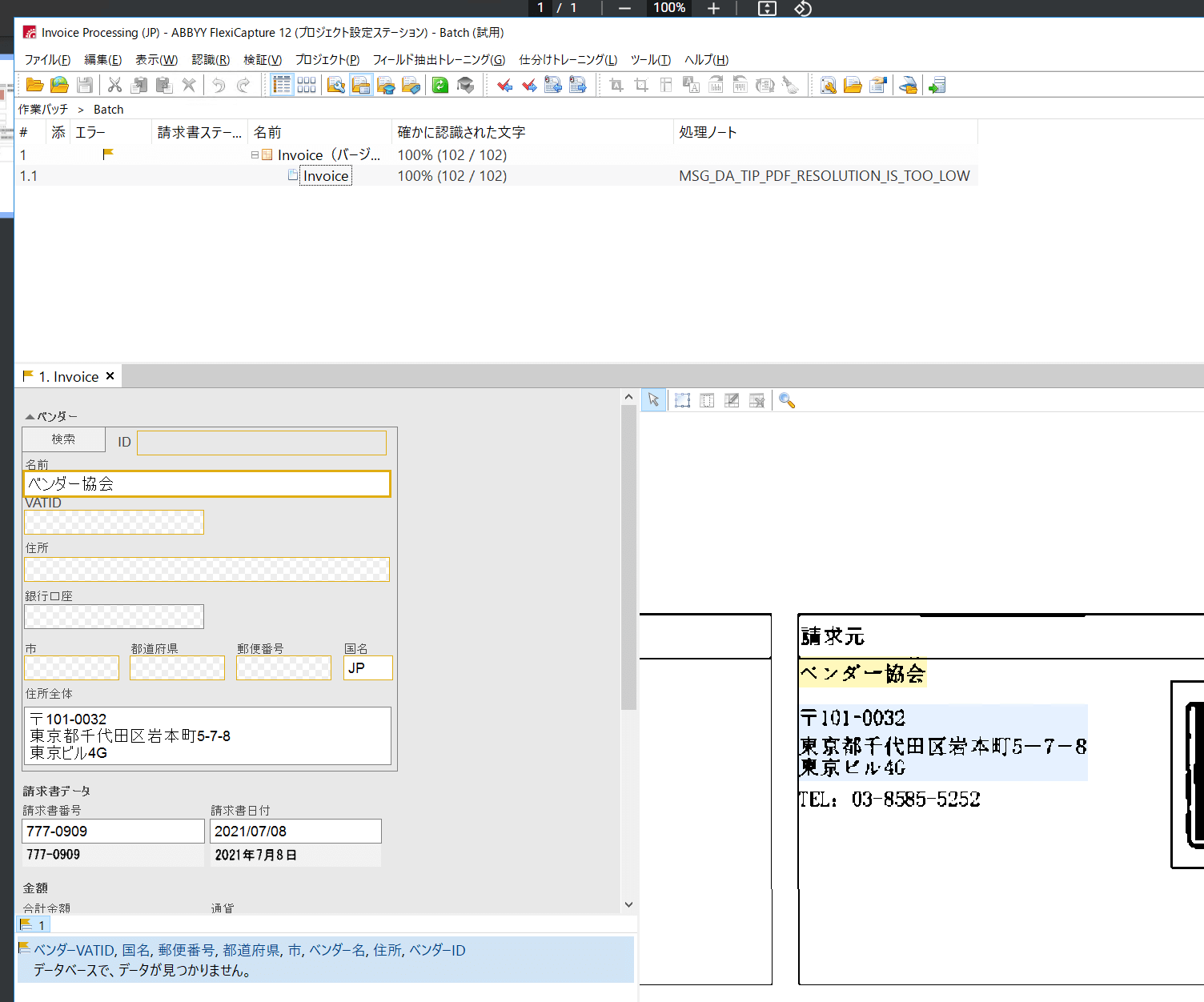
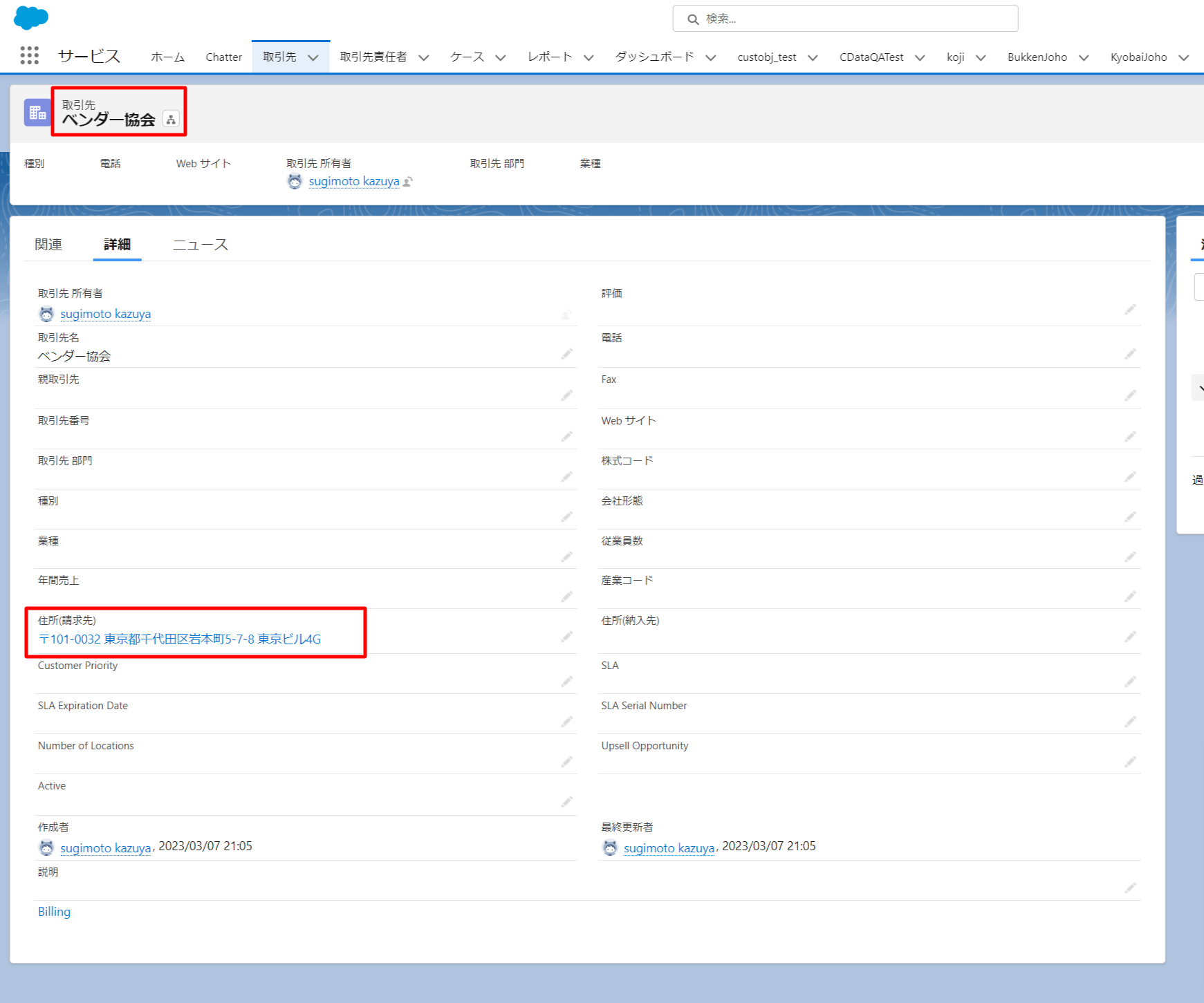
Salesforce の画面も確認してみると、以下のように正常にデータが登録されたことが確認できました!
おわりに
このようにCData ODBC Driver を利用することで、各種クラウドサービスやNoSQL、DWHなどにABBYY FlexiCapture のOCR の結果を取り込めるようになります。
CData では Salesforce 以外にもODBC Driver を多数提供しています。Kintone や HubSpot、Sansanなど様々なデータソースをサポートしているので、ぜひ自社で使っているクラウドサービスやNoSQL と合わせて活用してみてください。
ご不明な点があれば、お気軽にテクニカルサポートまでお問い合わせください。
https://www.cdata.com/jp/support/submit.aspx