ノーコードでクラウド上のデータとの連携を実現。
詳細はこちら →




Kodak Capture Pro を使ってOCR スキャンした結果をSalesforce のデータと組み合わせる方法:CData ODBC Driver
こんにちは。CData Software Japan リードエンジニアの杉本です。
今回はKodak が提供するスキャナー用ソフトウェアKodak Capture Pro とCData ODBC Driver を組み合わせて利用する方法を紹介します。
Kodak Capture Pro とは?
Kodak Capture Pro はKodak Alarisのスキャナーキャプチャ用ソフトウェアです。
https://www.alarisworld.com/ja-jp/solutions/software/document-scanning-software/capture-pro-software
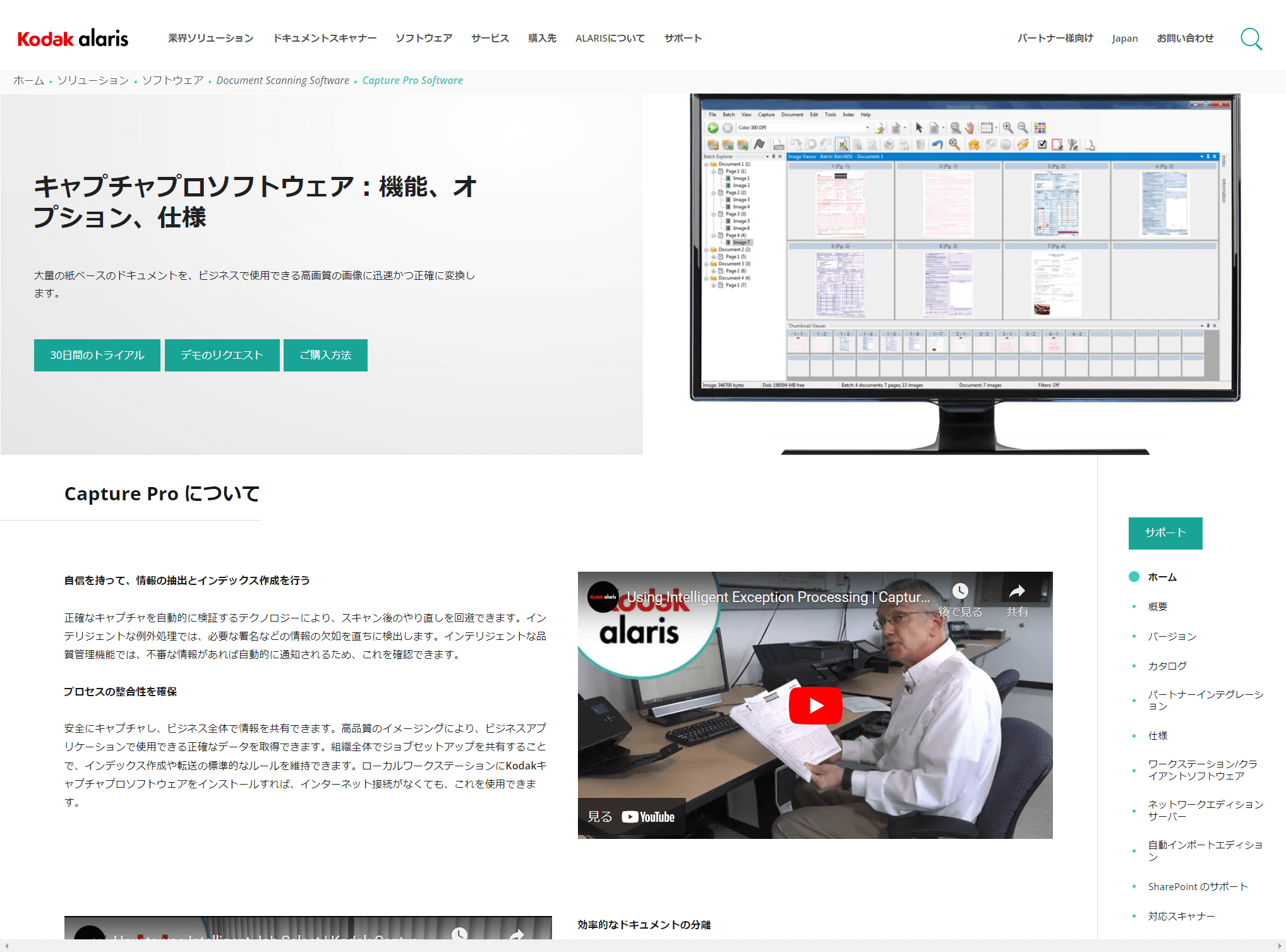
大容量の業務に向けて最適化されており、重要なデータをキャプチャしてインデックスを付け、データベースやSharePointなどのアプリケーション、ユーザーに自動的に配信する機能を備えています。
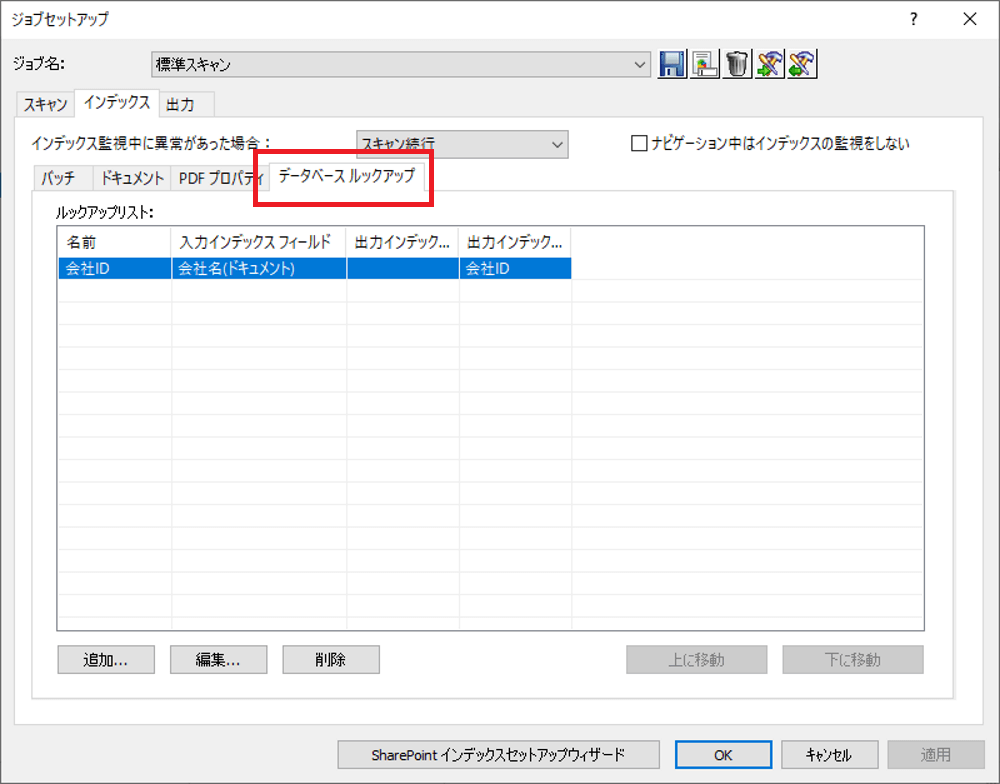
今回はこのKodak Capture Pro が持つデータベースルックアップの機能を使って、スキャンおよびOCRした結果をもとにSalesforce のデータに基いて出力結果をコントロールする方法を紹介します。
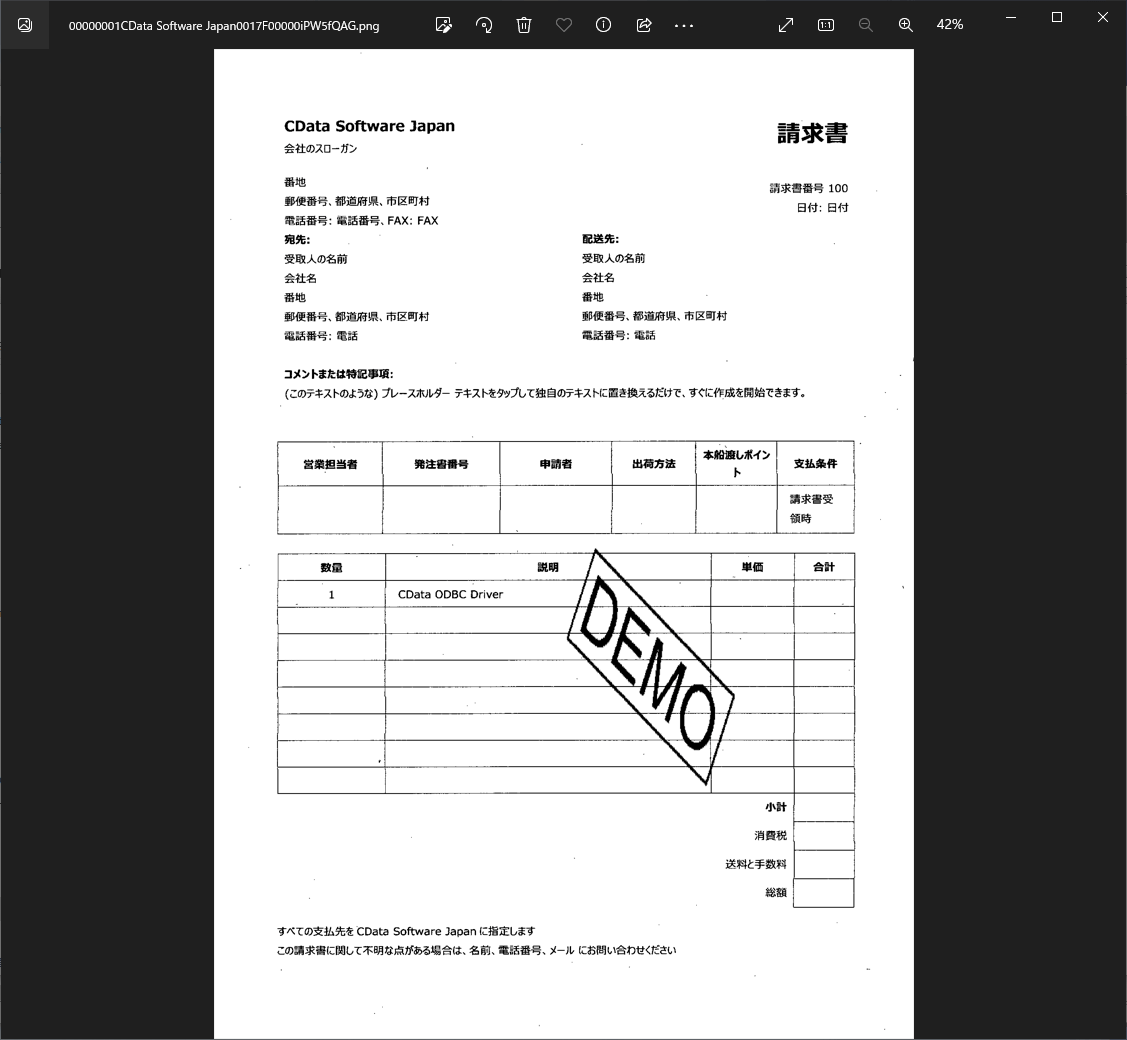
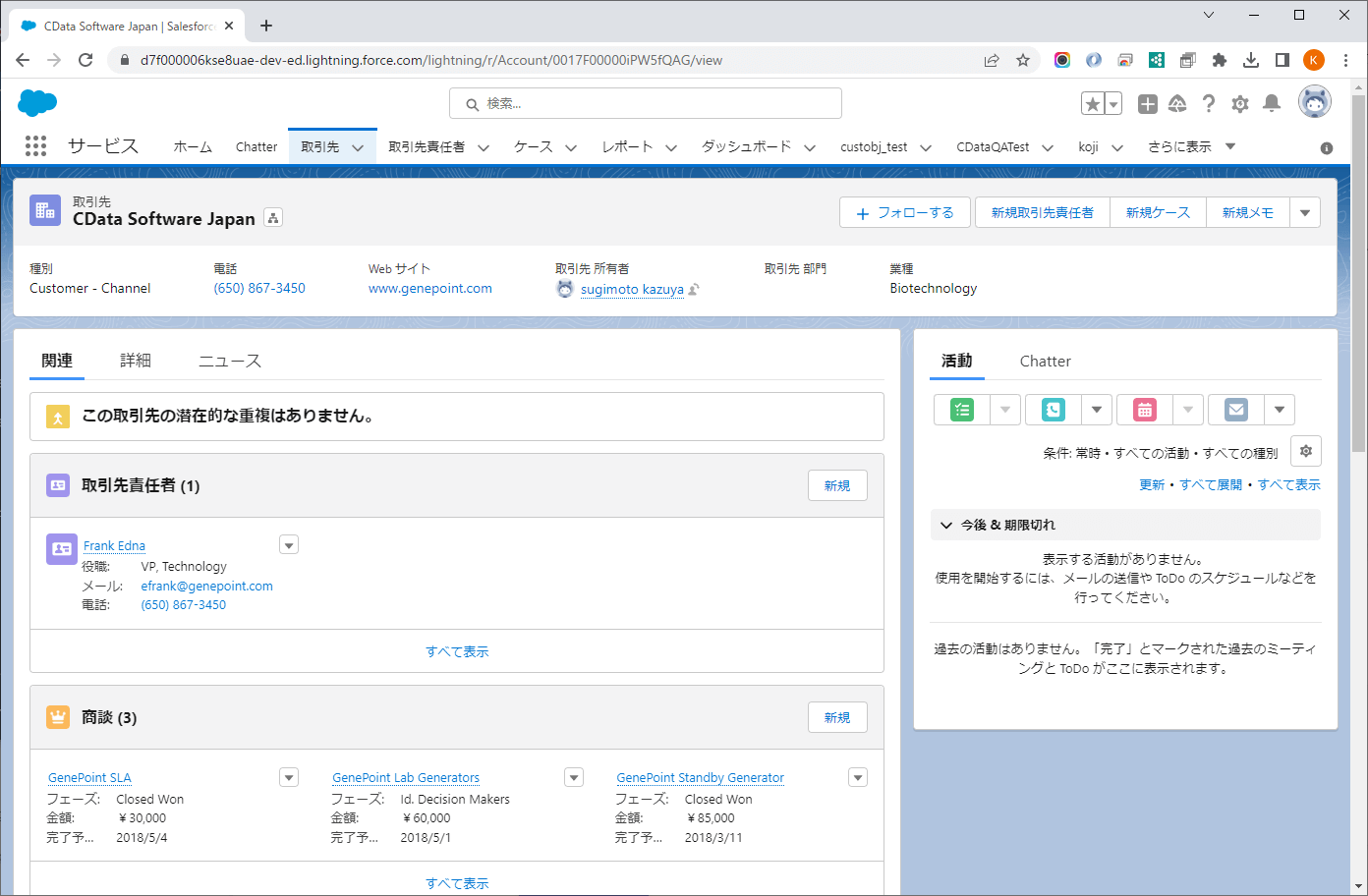
具体的には以下のような請求書のデータを取り込んだ際に、Salesforce のデータを検索して付随する情報を取得し、出力結果に反映させます。
Salesforce上では取引先オブジェクトで以下のような項目を管理しており、これらのデータに基いて出力フォルダやファイル名を操作することができるようになります。
CData Salesforce ODBC Driverのインストール・セットアップ
最初に CData Salesforce ODBC Driverを対象のマシンにインストール・セットアップします。
CData Salesforce ODBC Driver は以下のURLから30日間のトライアル版が入手できます。
https://www.cdata.com/jp/drivers/salesforce/odbc/
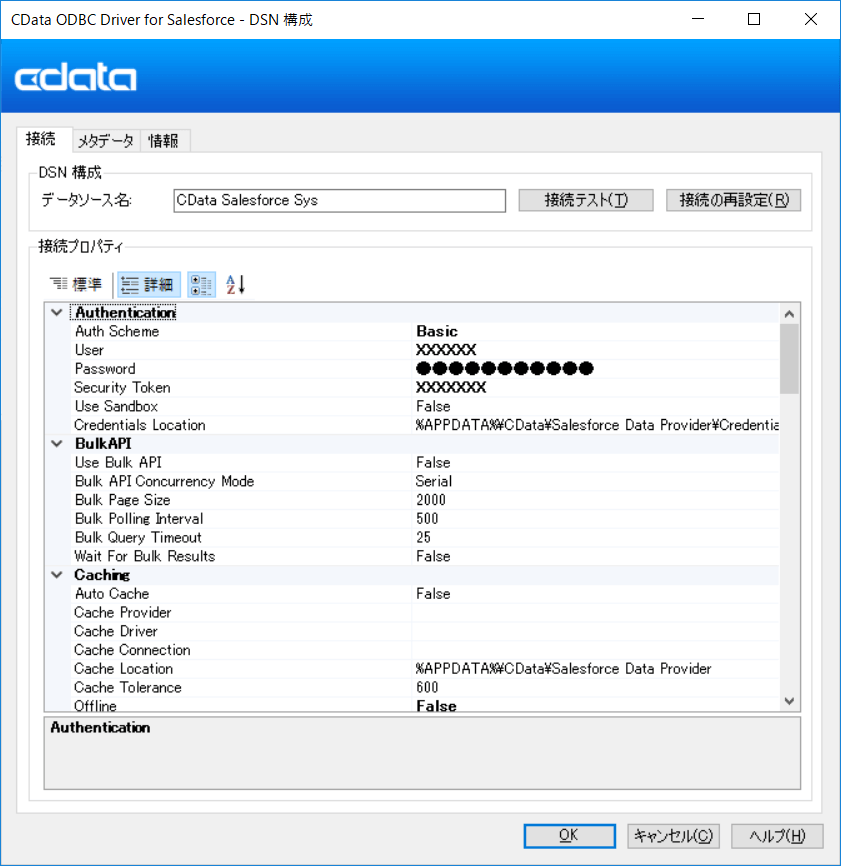
セットアップ完了後、接続設定画面が立ち上がります。下記の項目に Salesforce への接続情報を設定します。
|
Salesforceの接続情報 |
設定項目 |
備考 |
|
ユーザID |
User |
|
|
パスワード |
Password |
|
|
セキュリティートークン |
Security Token |
取得方法はこちら |
「接続のテスト」ボタンをクリックします。下記のようなダイアログが表示されれば成功です。
「接続ウィザード」の「OK」ボタンをクリックして保存します。
OCR項目の追加
それでは実際にKodak Capture Pro 側の設定を試してみましょう。
まずKodak Capture Pro を立ち上げて、ジョブセットアップからOCR項目を追加します。今回は標準スキャンのジョブに設定を追加しています。
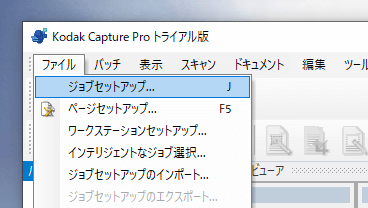
今回は請求書の会社名を識別するOCR項目を追加しました。
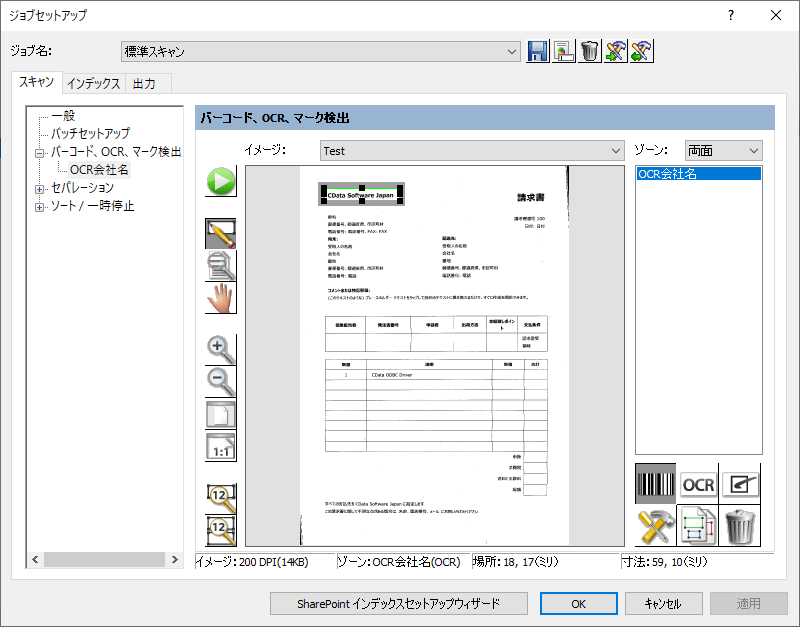
OCRゾーンのセットアップは以下のように指定しています。
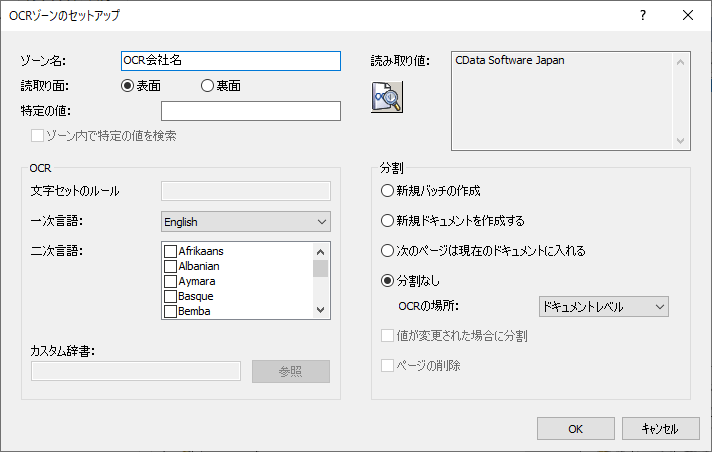
インデックスの追加
続いてOCRの結果、およびデータベースルックアップした結果のデータ格納する場所となる変数のような設定、インデックスを追加します。
インデックスはバッチ・ドキュメントそれぞれの単位で指定できます。
今回は以下のようにドキュメント単位で「会社名」と「会社ID」というインデックスを追加しました。
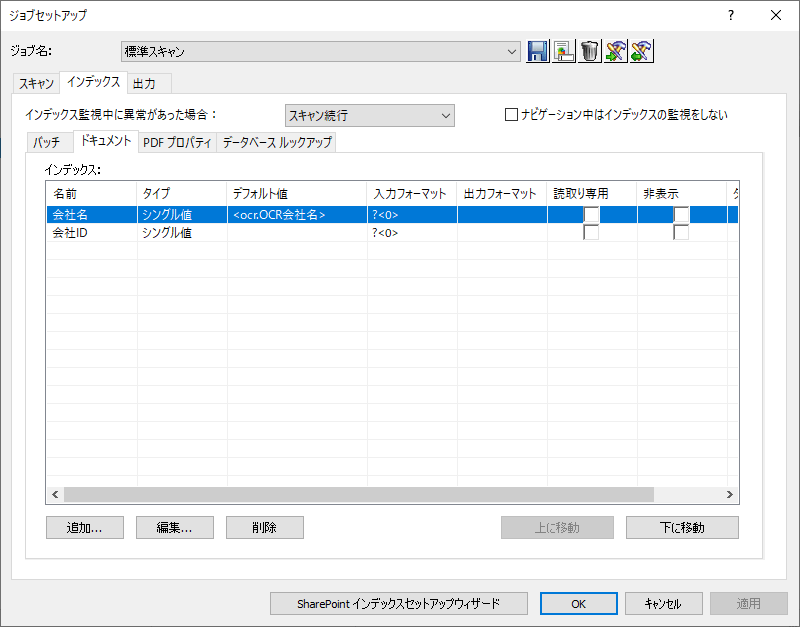
1つ目はOCRの結果を保存するためのインデックスは以下のように指定し、デフォルト値としてOCR項目に紐づけています。
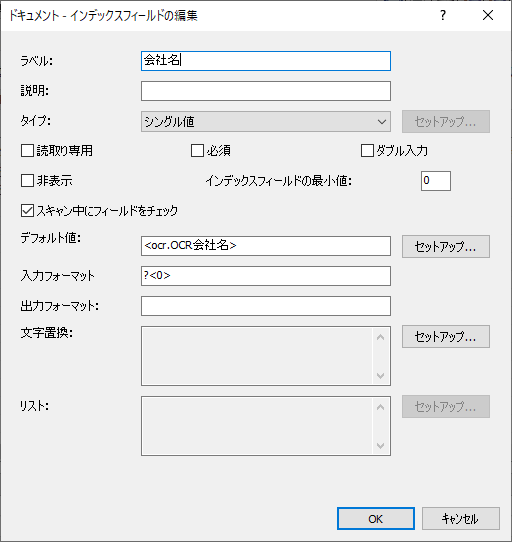
もう一つはデータベースルックアップの結果を保存するインデックスです。
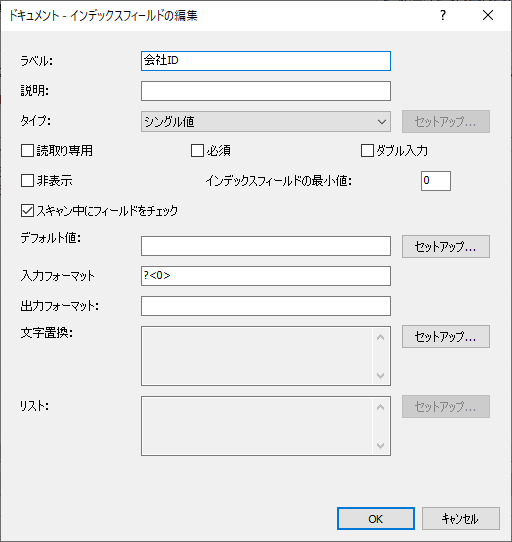
データベースルックアップの追加
続いてデータベースルックアップの項目を追加します。今回はOCRして読み取った結果となる会社名に基いて、Salesforce 上のIdを取得してくる処理を追加します。
「追加」ボタンをクリックし
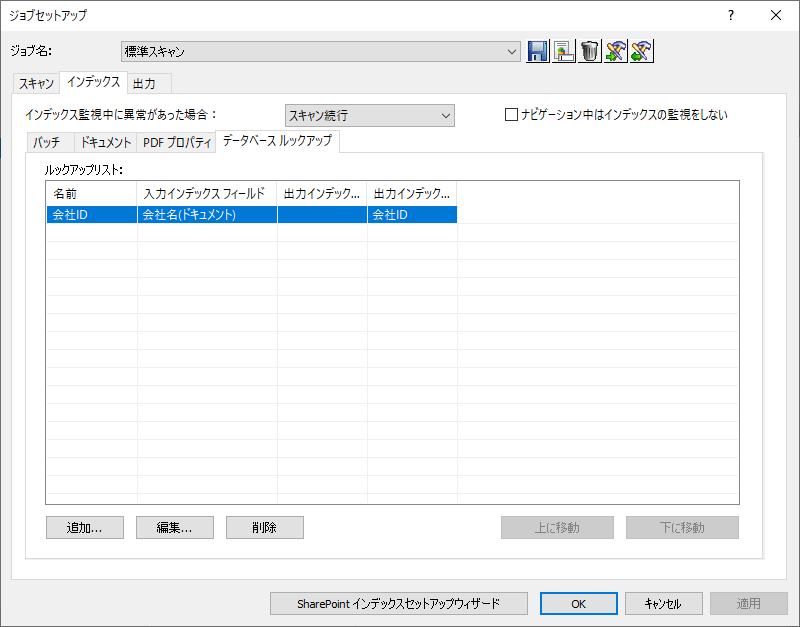
DB ルックアップウィザードに従って、設定を追加します。任意のルックアップ名を入力し、データソース名から「参照」をクリックしましょう。
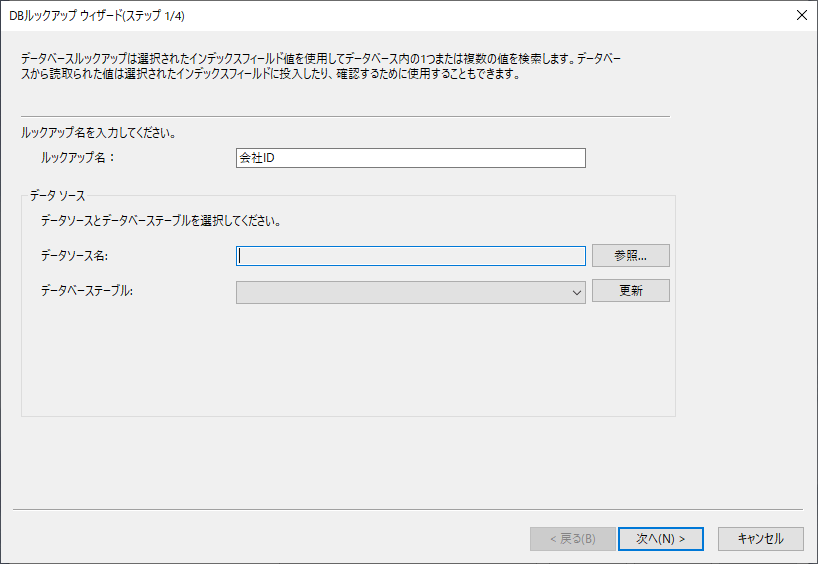
参照先としてODBC DSNを選択することができるので、先ほど設定したSalesforce のODBC DSNを選択します。
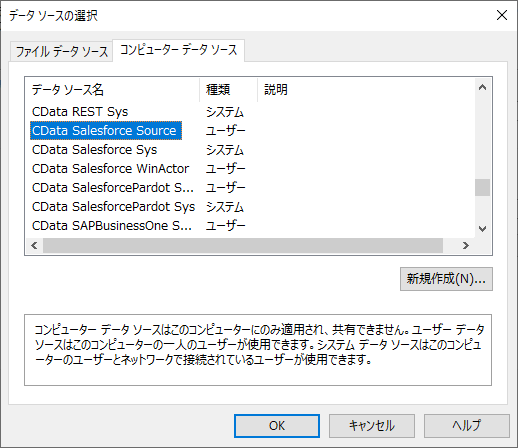
そして、対象のデータベーステーブルを選択しましょう。今回は取引先情報を管理している「Account」テーブルを指定しました。
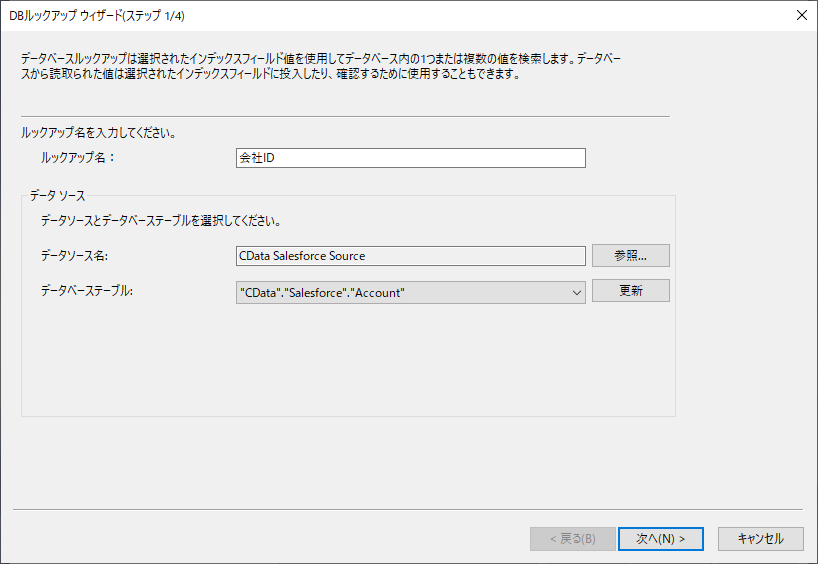
次にどのようにルックアップを行うのか? を設定します。今回はルックアップした結果をインデックスにデータとして格納するので「ルックアップの結果からインデックスフィールドに投入」を選択し、事前に作成したOCR結果が格納されるインデックスフィールドとSalesforce の取引先名称を格納しているNameを紐づけます。
そして、ルックアップ結果を保存するインデックスに取引先のIdを指定しました。
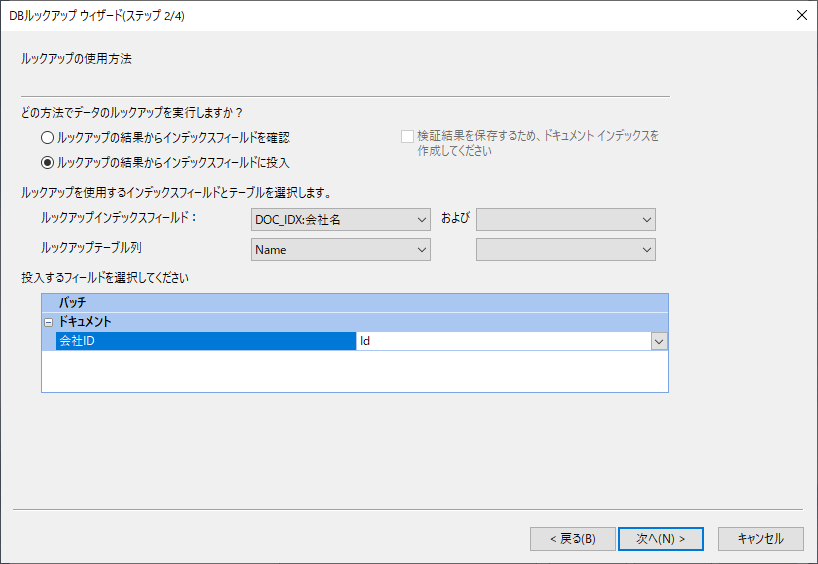
あとはルックアップのオプションを調整して設定は完了です。
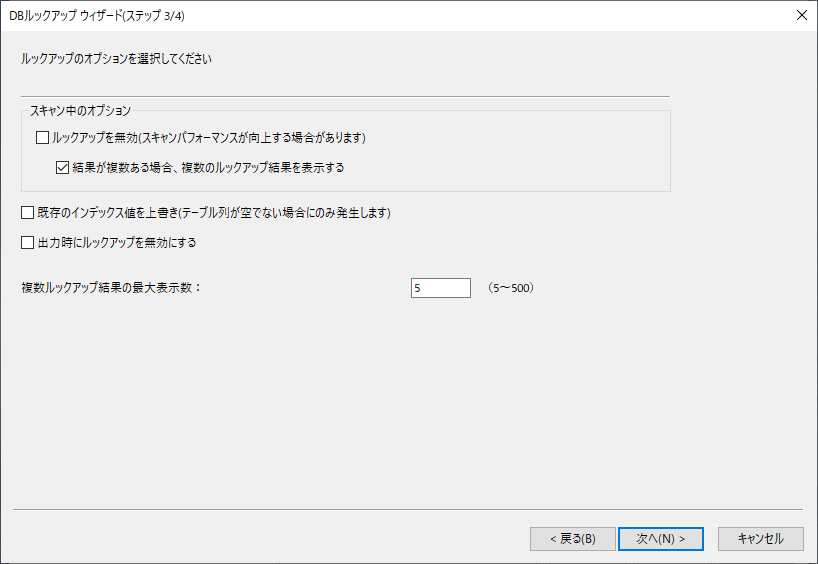
最後にテストクエリを入力し、Salesforce からId が正常に取得できているかどうか確認しましょう。以下のように任意の取引先名称を入力して、Salesforceが持つId を参照できていればOK です。
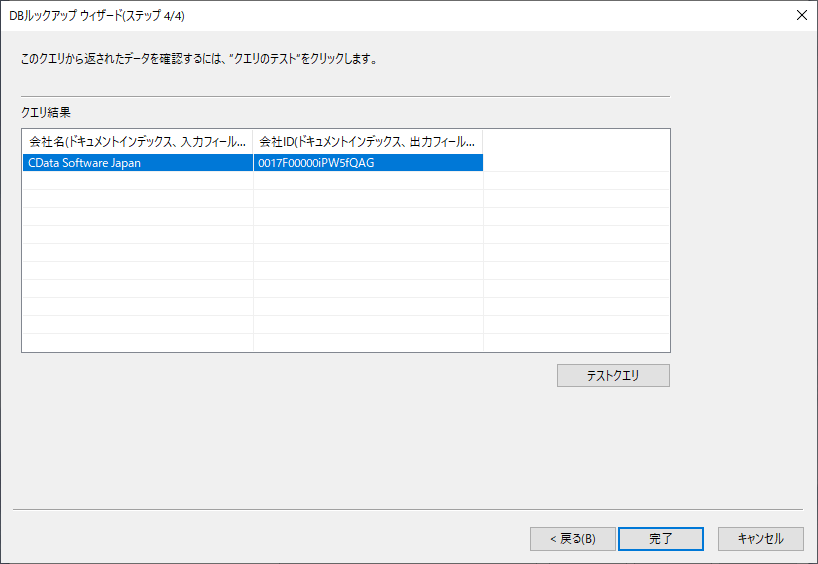
出力結果の設定
データベースルックアップの構成が完了したら出力結果にルックアップの結果を反映させてみましょう。今回はテストとしてシンプルにファイル名に取得した結果のIdを付随させてみます。
「出力」タブから「ファイル」を選択し「セットアップ」をクリックします。
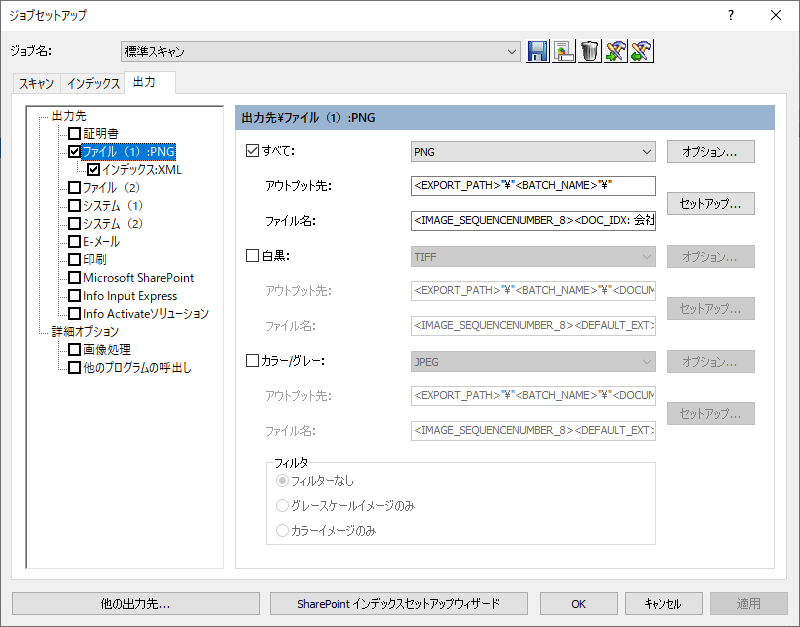
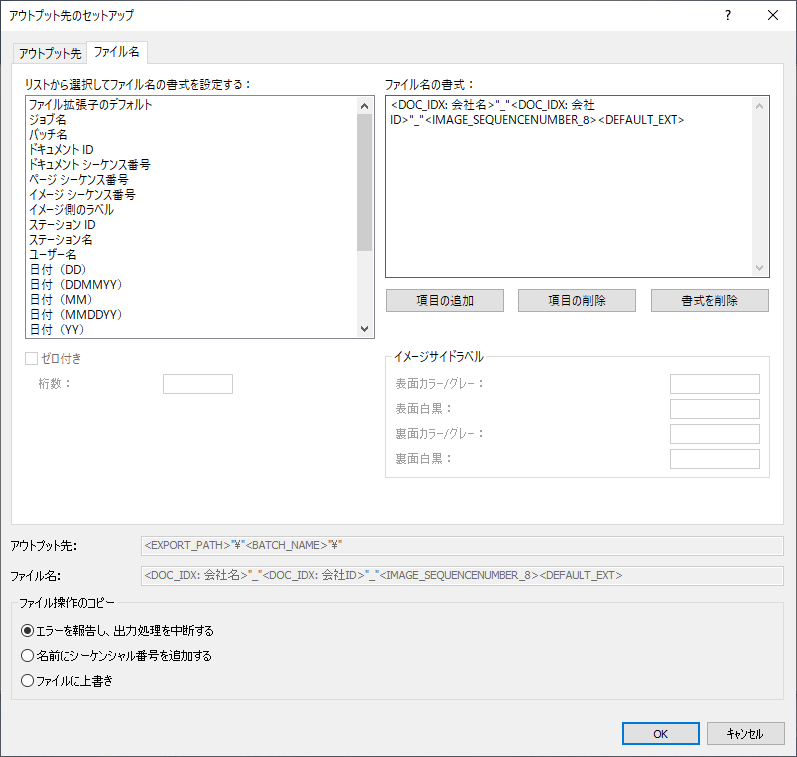
ファイル名にIdを入れるので、以下のようにインデックスに基いてファイル名を構成してみました。
<DOC_IDX: 会社名>"_"<DOC_IDX: 会社ID>"_"<IMAGE_SEQUENCENUMBER_8><DEFAULT_EXT>
テスト実行
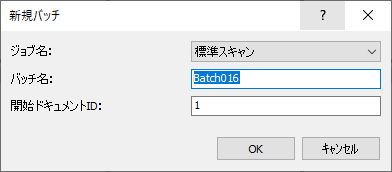
これで構成は完了です。それでは新規バッチをクリックし実際に取り込みを行ってみましょう。
先程作成したジョブを指定して、バッチを作成します。
バッチを作成後、実際に紙をスキャンします。
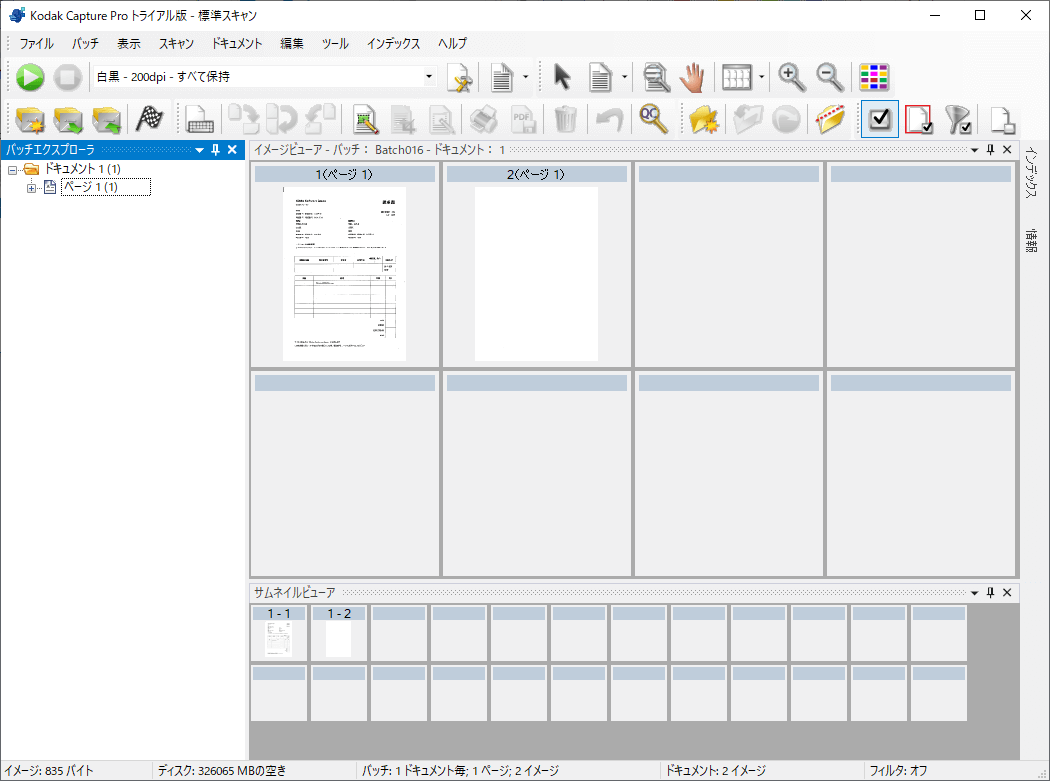
スキャンした結果が表示されたら画面上の旗アイコンをクリックするとジョブの設定に基づいてファイルが出力されます。
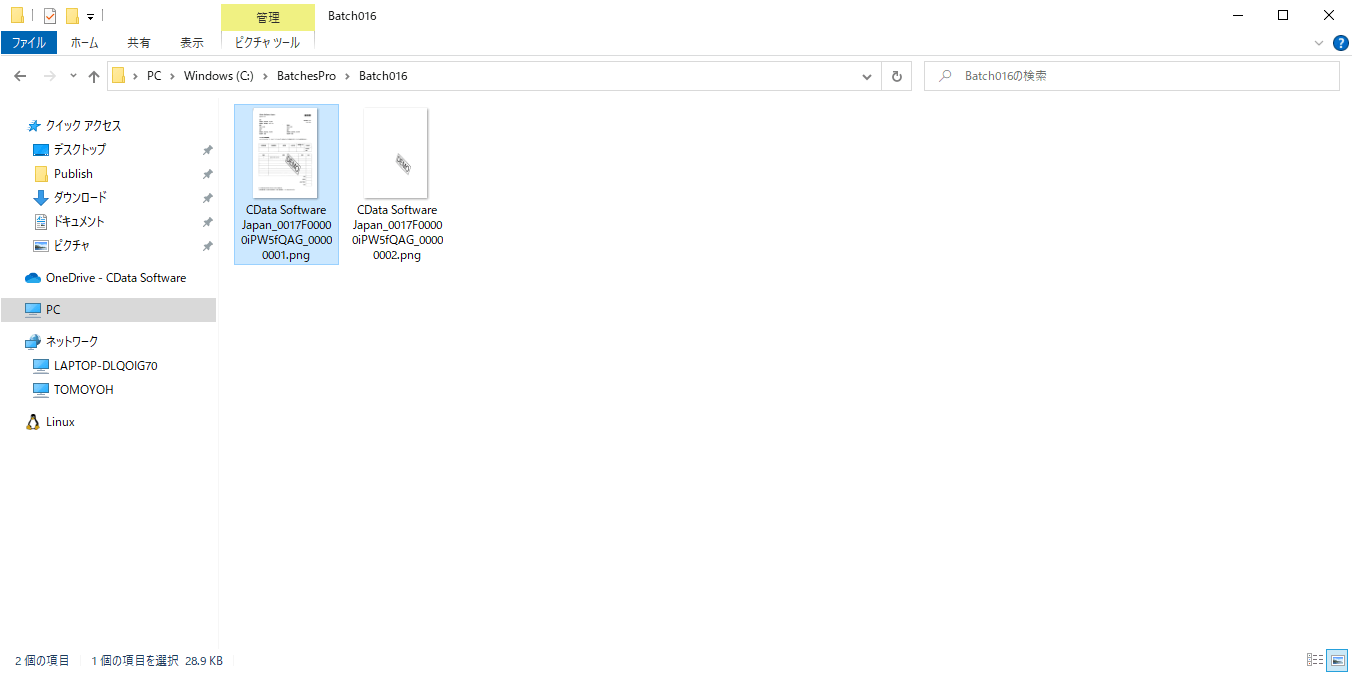
出力結果のフォルダを見てみると、以下のようにSalesforceのIdを含めたファイルが生成されていました。
おわりに
このようにCData ODBC Driver を利用することで、様々なクラウドサービスのデータをKodak Capture Pro で活用することができます。
今回はSalesforce を例として紹介しましたが、CData では Salesforce 以外にもODBC Driver を多数提供しています。
Kintone や HubSpot、Sansanなど様々なデータソースをサポートしているので、ぜひ自社で使っているクラウドサービスやNoSQL と合わせて活用してみてください。
ご不明な点があれば、お気軽にテクニカルサポートまでお問い合わせください。
https://www.cdata.com/jp/support/submit.aspx