ノーコードでクラウド上のデータとの連携を実現。
詳細はこちら →




CData Arcを使ってSQL ServerのデータをSharePoint Onlineのリストにノーコードで連携:CData Arc & CData SharePoint Driver

こんにちは。CData Software Japanの色川です。この夏に CData に加わりました。CData Arc を担当しています。
いま様々なお客様とお話しさせて頂く中で「オンプレミスにあるデータを SharePoint Online へ連携したい」というご相談を数多くお聞きします。
そこで今回は CData Arc と CData SharePoint Driver を使って SQL Server のデータを SharePoint Online のリストに連携する方法をご紹介します。
CData Arc とは?
ファイル転送(MFT)とSaaSデータ連携をノーコードで実現できるデータ連携ツールです。ファイル・データベース・SaaS API、オンプレミスやクラウドにある様々なデータをノーコードでつなぐ事ができます。
CData Arc は世界中で10,000社を超える導入実績を持ち、多様な業界のデータ連携を支えている製品です。
この記事のシナリオ
この記事では SQL Server のテーブルにある従業員データを、SharePoint Online に作成した従業員リストへ連携するシナリオを実現します。
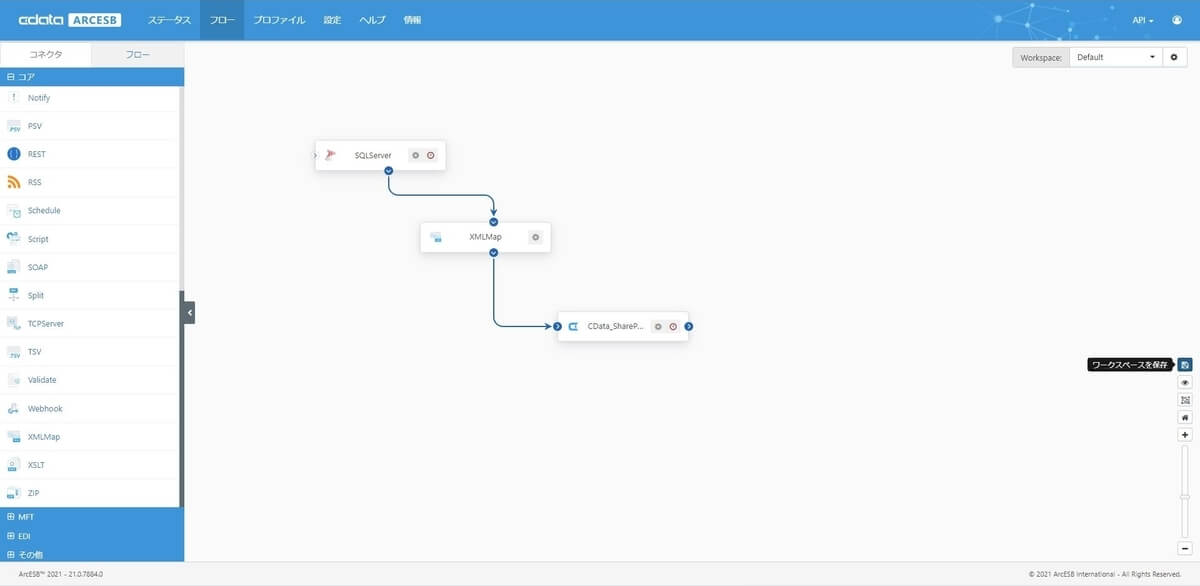
この記事のシナリオを進めて頂くと、このような連携フローが出来上がります。
必要なもの
以下の製品のインストールが必要になります。すべて30日間のトライアルが提供されていますので、ぜひ試してみてください。
事前準備
まずシナリオで利用する製品をそれぞれインストールします。以下のURLから CData Arc の本体を入手できます。必要に応じて、Windows、Java/Linux、Cloud Hostedのバージョンから選択してください。なお、この記事ではWindowsベースで進めます。
インストールはダイアログに従って進めて頂ければ大丈夫です。難しいところはありません。ログインする際のパスワード入力を求められる場所がありますので、忘れないようにしてください。
次に SharePoint リストへ接続するために CData SharePoint ADO.NET Provider を入手し、インストールします。
連携元の SQL Server テーブル
今回は、pubs サンプルデータベースの employee テーブルを利用しました。
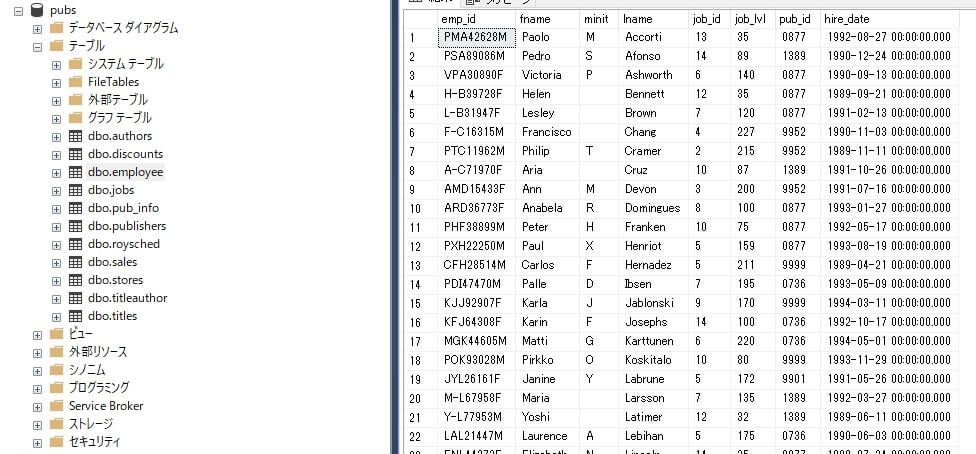
このデータを SharePoint Online のリストへ連携します。
連携先の SharePoint Online リスト
今回は、SharePoint Online に従業員データを保持するリストを作成しました。
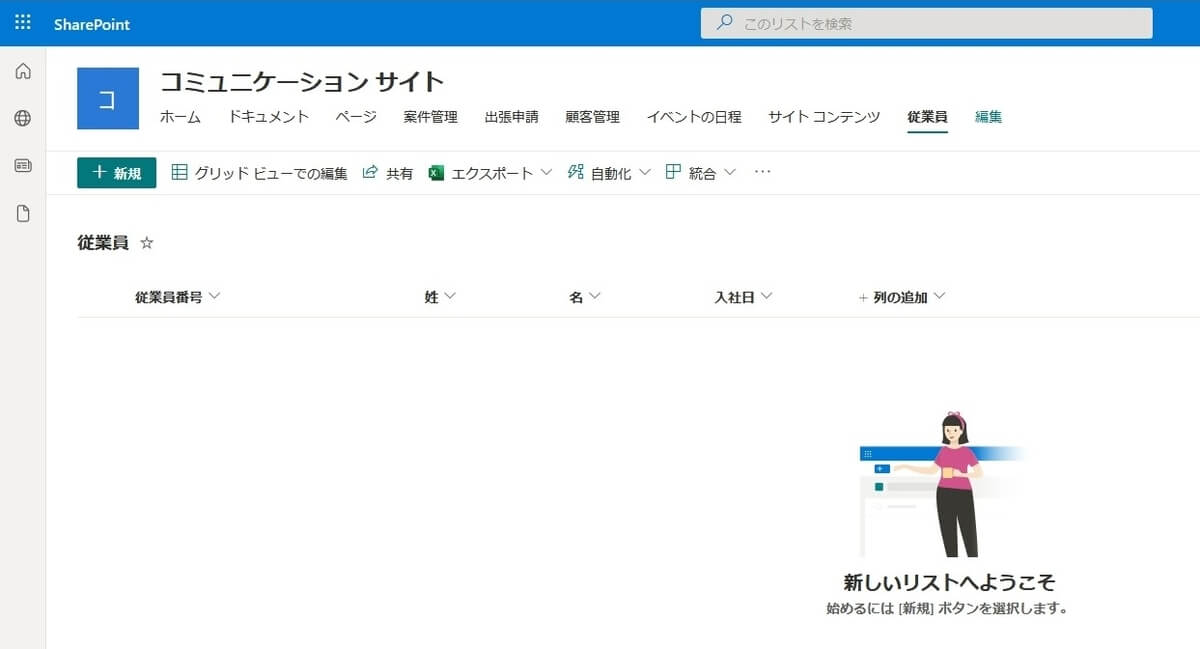
| 列 | 種類 | 必須 |
|---|---|---|
| 従業員番号 | 1 行テキスト | 〇 |
| 姓 | 1 行テキスト | |
| 名 | 1 行テキスト | |
| 入社日 | 日付と時刻 |
このリストに SQL Server のデータを連携します。
シナリオの開発と実行
それでは、実際に CData Arc を使って連携処理を作っていきます。
CData Arc にログイン
CData Arcが起動すると、ログイン画面が表示されます。UserName:adminとインストール時に入力したパスワードを使って、ログインしてください。
ログイン後、トライアルライセンスをアクティベーションしてください。
CData Arcでは「フロー」からデータ連携処理を作成します。
SQL Server コネクタ の配置と構成
フローのデザイン画面に移動したら、それぞれのデータ処理コネクタを配置していきます。
まずは、SQL Server の接続を構成しましょう。左側のコネクタ一覧から「その他」の「SQL Server」を選択し、フローキャンパスに配置します。
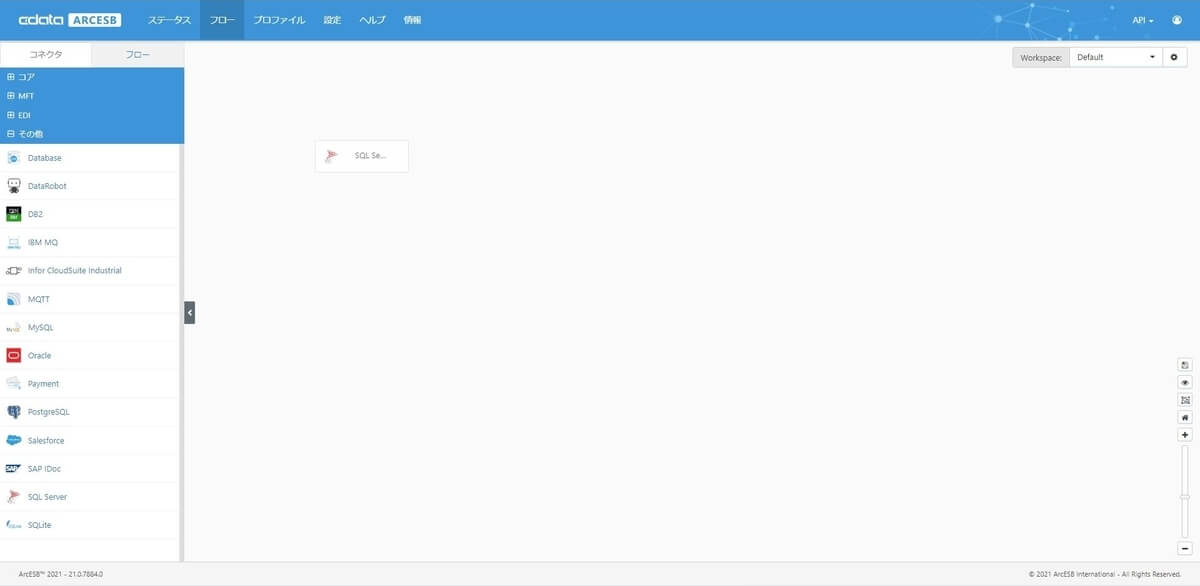
任意のコネクタId(ここでは SQL Server としました)を入力し「+コネクタを作成」をクリックします。
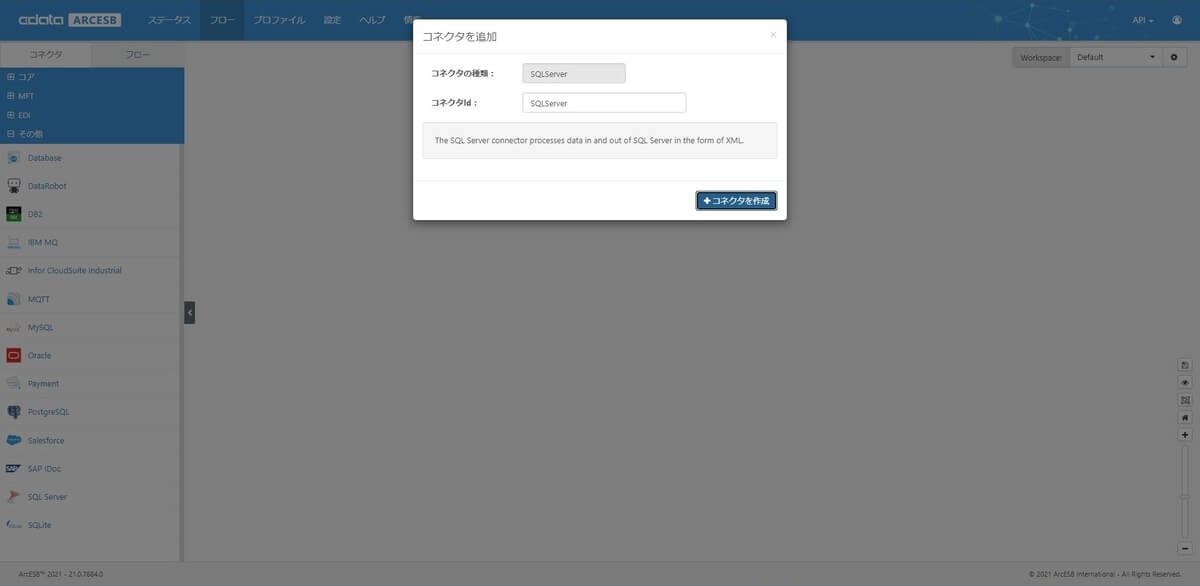
コネクタが作成されると、右側に設定画面が表示されるので、まずはデータベース接続を設定しましょう。プロパティリストか接続文字列の何れかで指定ができます。ここではプロパティリストで指定します。「Authentication」「Server」「ユーザー」「パスワード」を指定し、接続するSQL Serverデータベースを選択してください。接続テストが無事に完了したら設定を保存しましょう。
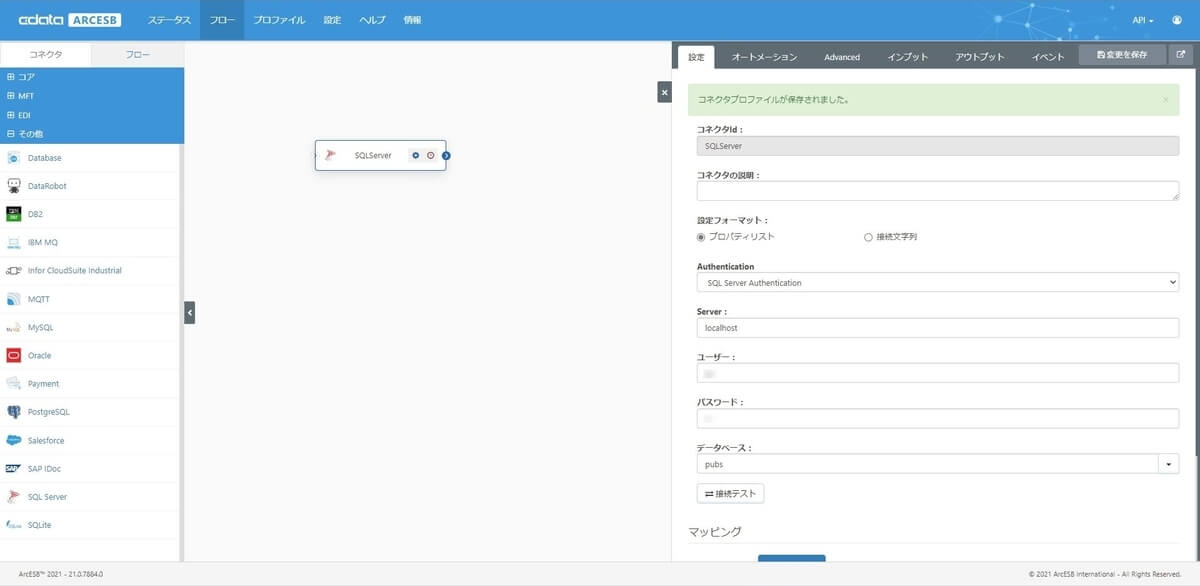
次に取得したいテーブルを選択するために、マッピングを設定しましょう。SQL Server からはデータを出力するので、マッピングのアウトプットを選択し、アウトプットマッピングから「+」ボタンをクリックします。
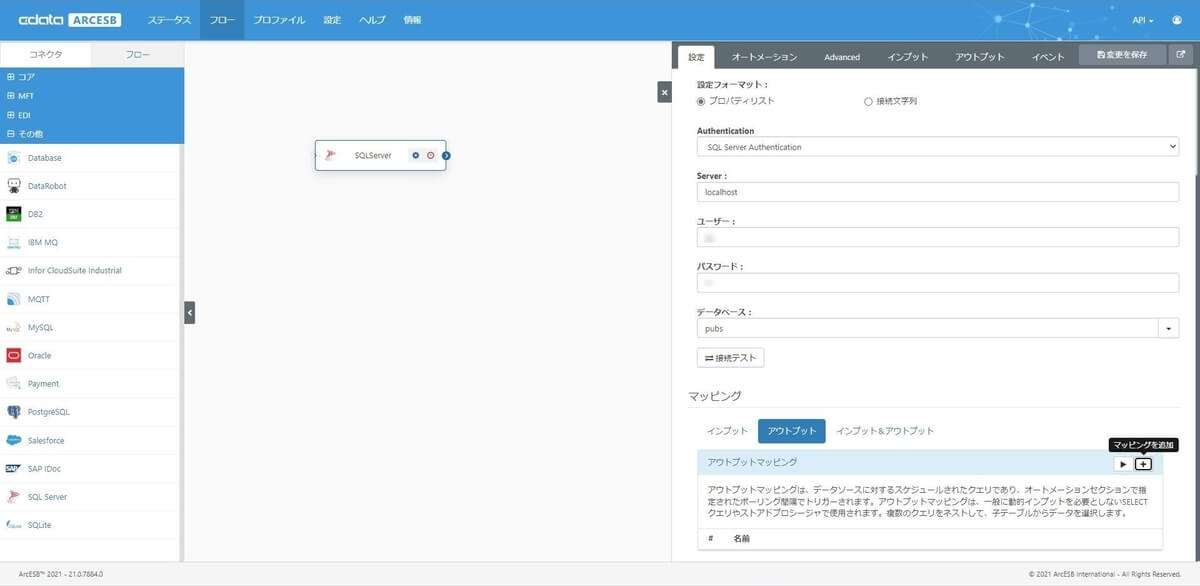
SQL Server コネクタで使用できるテーブル一覧が出てくるので、従業員データを取得できる「employee」を選択します。
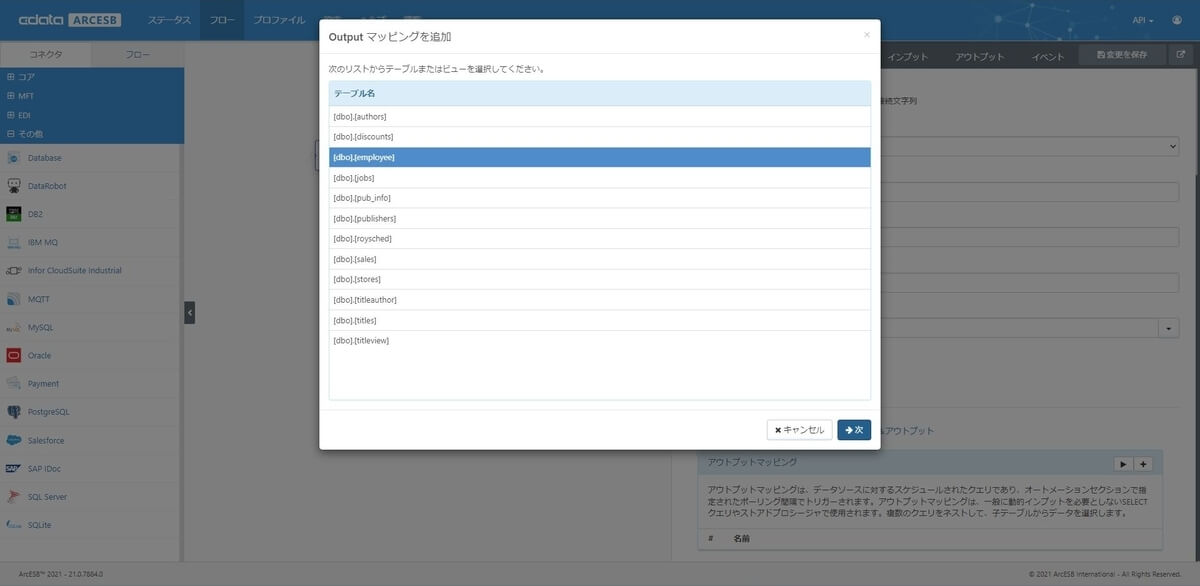
次の画面に移動すると、取得する項目や諸条件を指定することができるマッピングエディタに移ります。
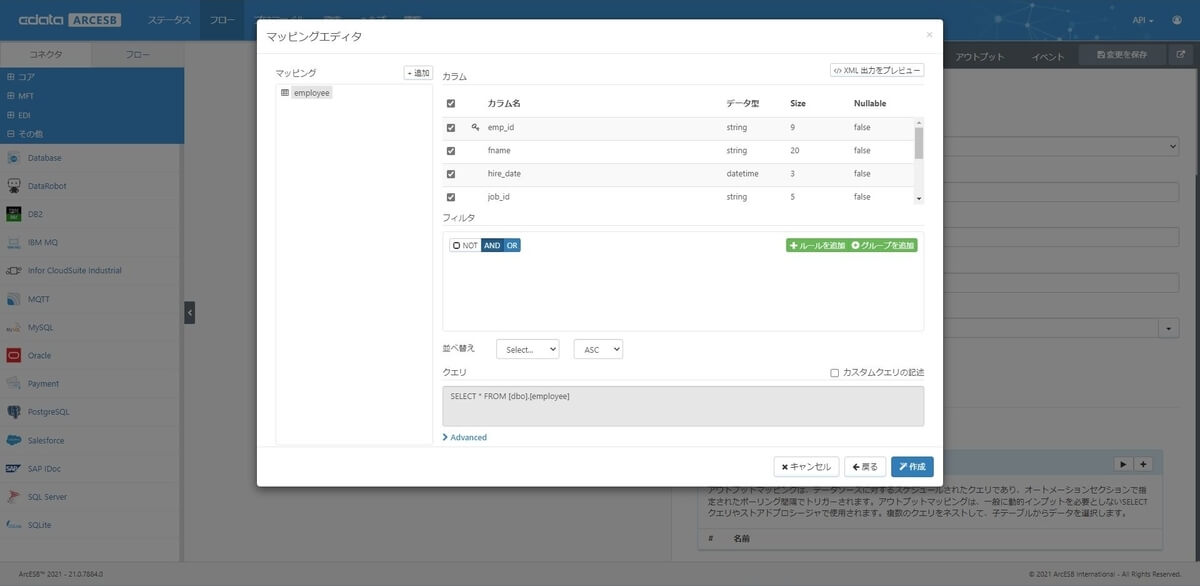
今回は細かな設定は行わず employee テーブルの全レコードを取得しますが、取得するレコードの絞り込みや並べ替えも指定する事ができます。
新規または変更されたレコードのみを処理したい
1回限りでない連携フローでは前回実行した以降に新規または変更されたレコードのみを処理したいケースは多いと思います。CData Arcのアウトプットマッピングでは2つの方法をご用意しています。
1. 最終更新日時を表すカラムを指定する
1つ目の方法では、レコードの最終更新時刻を表す DateTime 型のカラムが必要です。マッピングエディタで、パネルの下部にある「Advanced」を展開してください。DateTime 型のカラムが検出された場合「新規または変更されたレコードを処理するために、カラム「xxx」を使用する」というオプションが用意されています。ここにレコードの最終更新時刻を表す適切な DateTime カラムを指定してください。
2. 処理済を表すカラムを指定する
2つ目の方法では、レコードを処理すべきかどうかを表す値を明示的に格納するカラムが必要です。
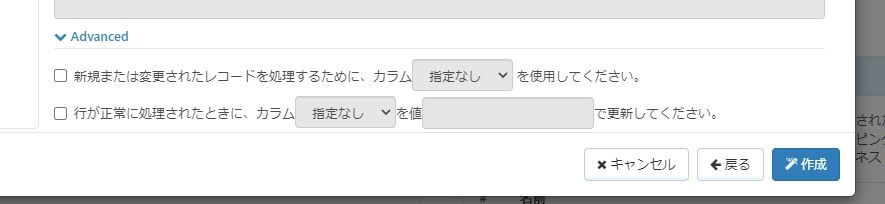
アウトプットマッピングでは、正常に取得されたレコードのテーブル内のカラムを更新するように設定できます。これは、処理すべき(まだ取得されていない)ことを示すカラム値を持つレコードのみを SELECT するフィルタルールと組み合わせることができます。
正常に取得された後のカラムの更新を有効にするには、マッピングエディタの下部にある [Advanced] を展開してください。「行が正常に処理されたときに、カラム「xxx」を値「xxx」で更新してください」を有効にして、更新するカラムと、このカラムに設定する値を指定します。
例えば、アウトプットマッピングは、レコードを取り出した後、Processedカラムを「1」に更新するように構成されているかもしれません。次に、Processed が 1 になっていないレコードのみに制限する フィルタ ルールを適用することができます。
CData(SharePoint)コネクタの配置と構成
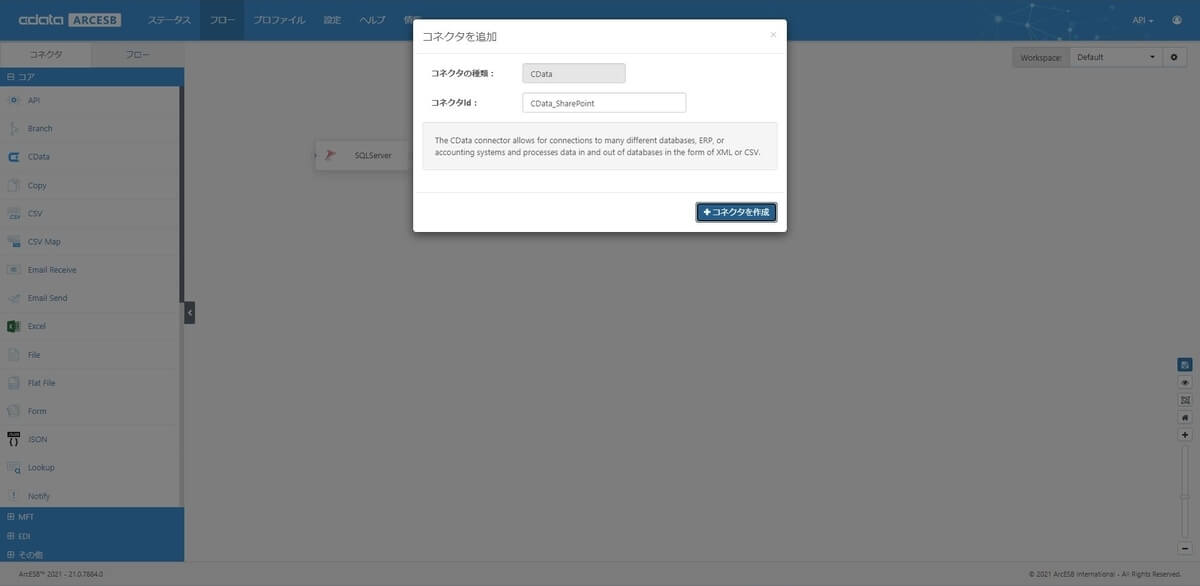
続いて SharePoint の接続を構成していきます。左側のコネクタ一覧から「コア」の「CData」を選択し、フローキャンパスに配置します。コネクタIdは CData_SharePoint としました。
データソースは CData SharePoint を選択し、SharePoint Online 環境の接続情報を入力します。今回は REST API へ OAuth 認証で接続しています。接続が無事に完了したら設定を保存しましょう。
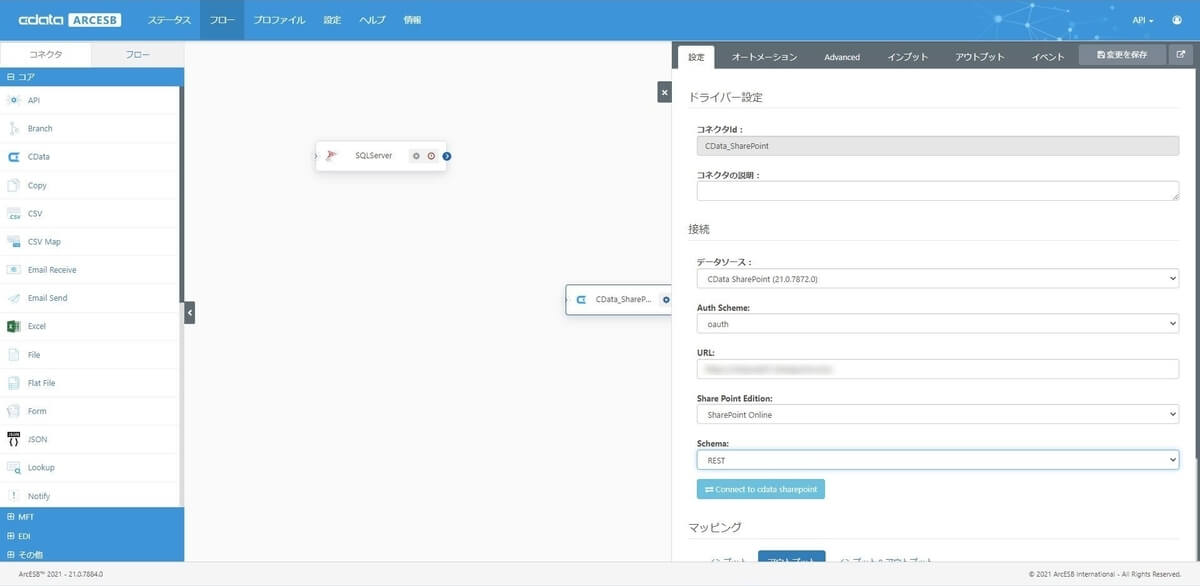
次に登録したいリスト(テーブル)を選択するために、マッピングを設定しましょう。SharePoint Online へはデータを入力するので、マッピングのインプットを選択し、インプットマッピングから「+」ボタンをクリックします。
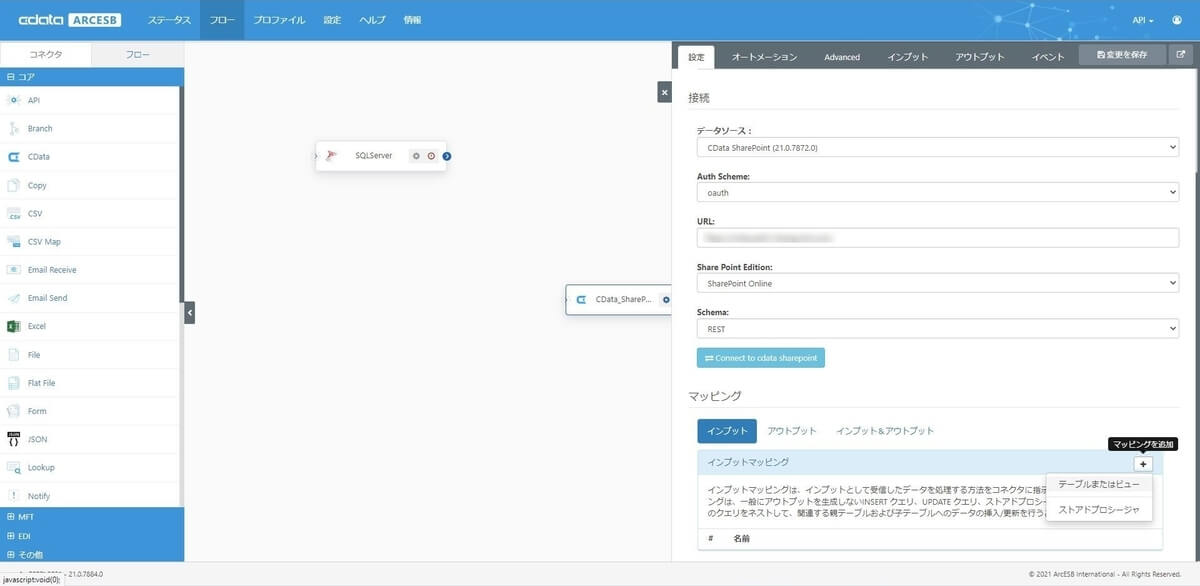
対象のリスト(テーブル)一覧がリストアップされるので、あらかじめ用意した従業員リストを選択します。
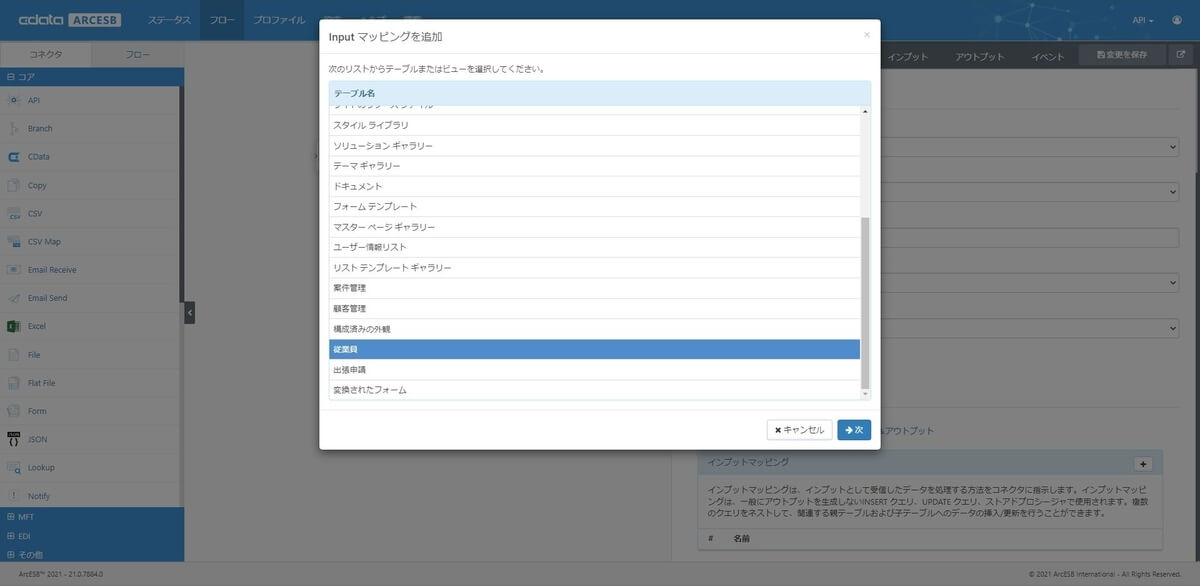
次の画面で登録する項目と処理方法(UPSERTするかどうか)、UPSERTする場合のKey項目を指定します。今回は employee テーブルの主キーである emp_id と紐づける「従業員番号」を一意の項目として指定しています。
以上で、SQL Server と SharePoint のコネクター構成は完了です。
マッピングコネクタの配置と構成
続いて、SQL Server と SharePoint の項目を紐付けるために必要な マッピングコネクタを配置します。
左側のコネクタ一覧から「コア」の「XMLMap」を選択し、フローキャンパスに配置します。コネクタIdは XMLMap としました。
XMLMapコネクタを配置後、まずインプットとアウトプットをフローで紐付けます。以下のようにドラッグアンドドロップで、事前に作成した SQL Serverコネクタ / CData(SharePoint)コネクタと紐付けて、画面右下にある保存ボタンで設定を保存してください。これでXMLMapにどのような形式で入力され、どのような形式で出力するかの情報が伝わります。
次に、XMLMapの設定画面を開きます。フローの紐づけが正常に構成されていれば、ソースファイルとデスティネーションファイルが以下の様に入力されているはずです。
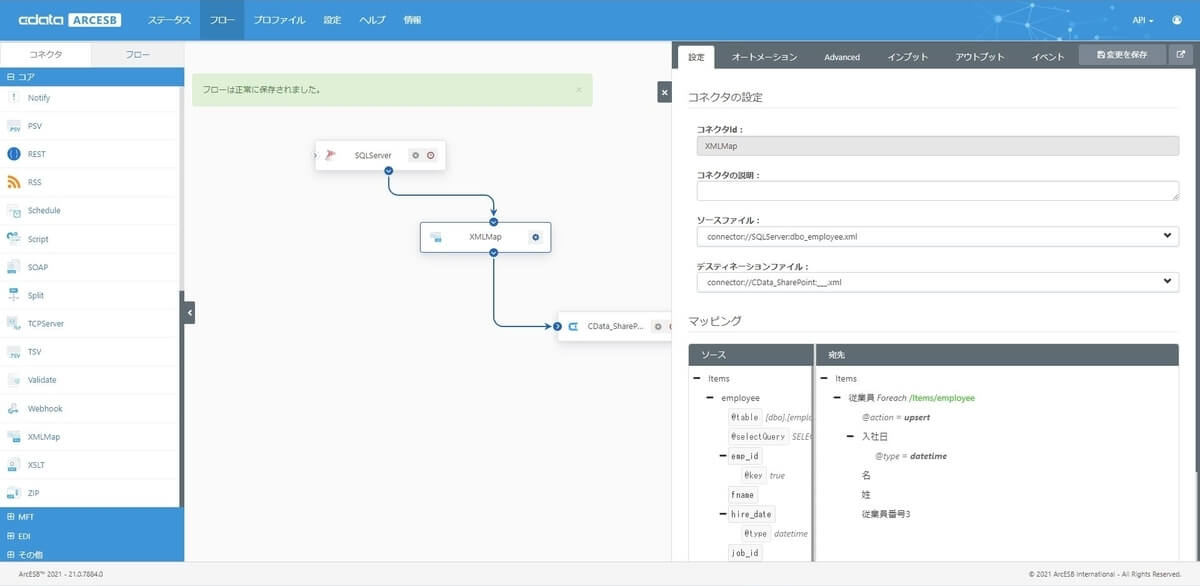
画面下で各項目のマッピングを行う領域が表示されているので、ここで項目をドラッグ・アンド・ドロップして、SQL Serverと SharePoint Onlineのリスト項目一覧を紐付けていきます。
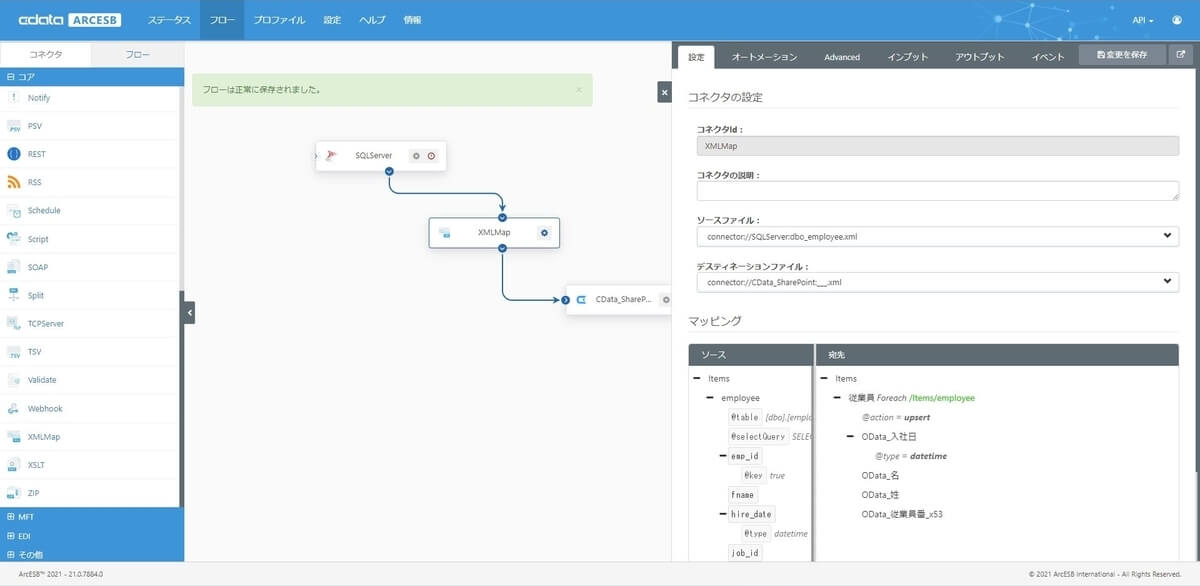
紐付け後、保存をすれば、設定完了です。
自動実行の設定
設定したフローを自動的なタイマー起動するには、データ連携の実行間隔を設定します。実行間隔の設定は、データ取得元である SQL Server コネクタの設定画面にある「オートメーション」タブで設定します。
受信のチェックボックスにチェックを入れて、受信間隔と時間を指定しましょう。以下の画面では、毎日12時に起動する設定にしています。
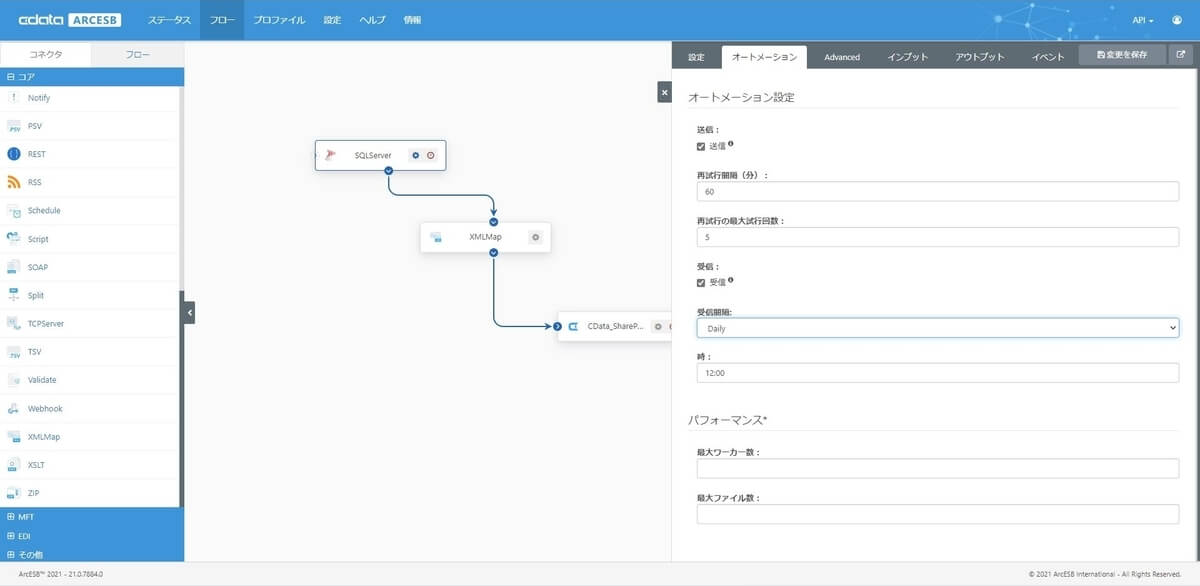
実行
それでは構成したフローを実行してみます。
タイマー起動ではない、手動での実行は「アウトプット」の「受信」ボタンをクリックすることで可能です。
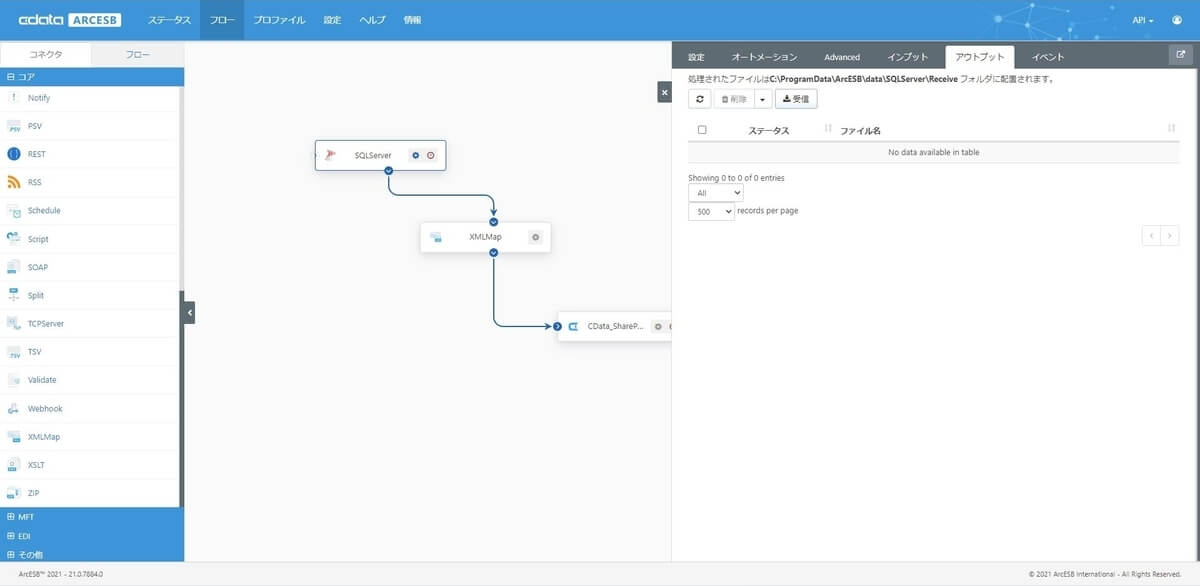
「受信」ボタンをクリックすると、SQL Serverからデータが取得され、以下のようにCData Arcにロードされたことがわかります。
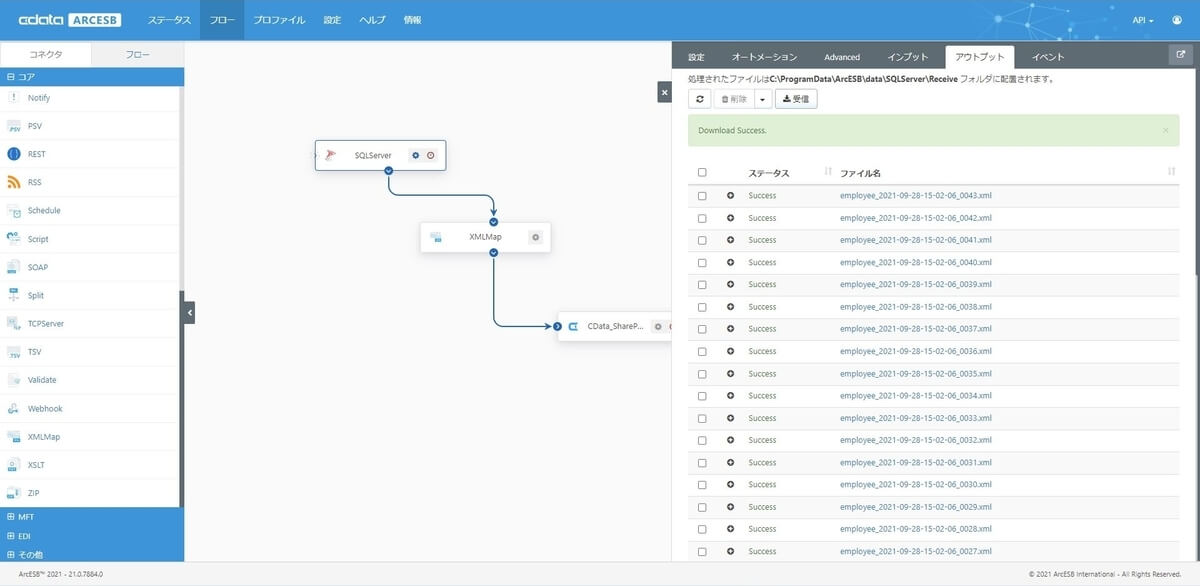
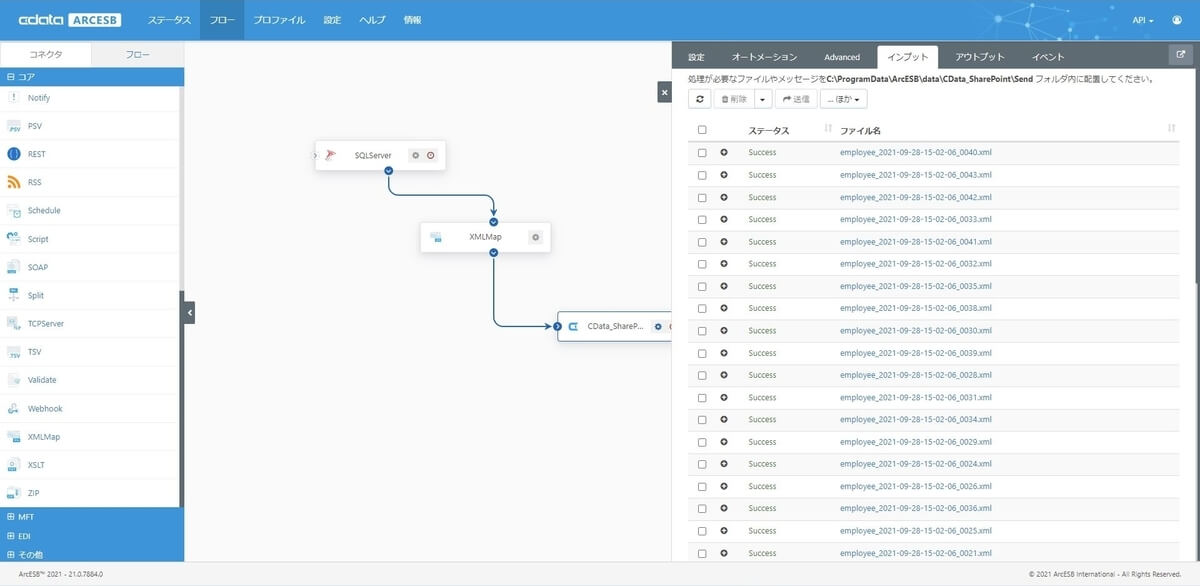
最終的な処理結果は CData(SharePoint)コネクタのインプットタブから確認できます。ここで処理結果がSuccessになっていれば、SharePoint Online側に正常に処理が行われたことになります。
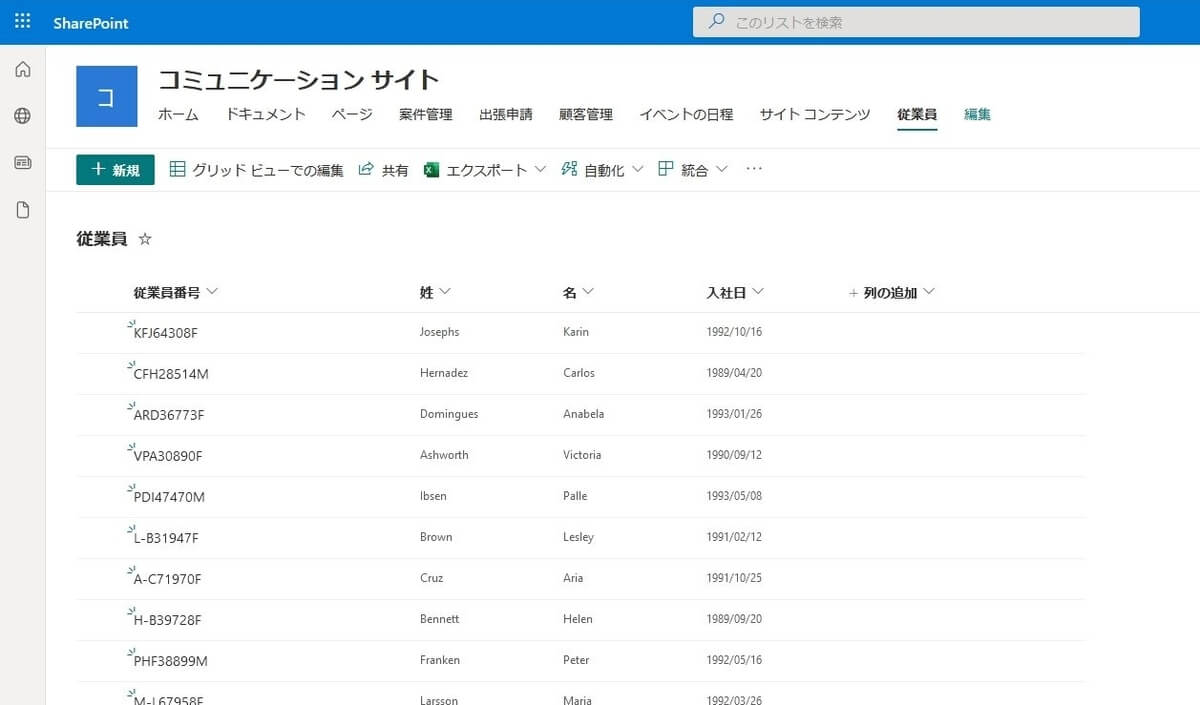
実際に SharePoint Online 上の従業員リストを見てみると、SQL Server の employee テーブルから従業員データが登録されていることが確認できます。
一括処理
基本的に CData Arc では、1レコードずつXMLドキュメントとして出力し処理を実行します。レコード数が多い場合など、処理対象レコードを1つのXMLドキュメントに一括して出力し処理を実行したい場合には「batchResults」属性を活用する事ができます。
例えば、今回のシナリオで SQL Server の employee テーブルから結果を取得するアウトプットマッピングを以下のように変更(追記)する事で結果がバッチ処理されるようになります。
<Items> <employee table="[dbo].[employee]" selectQuery="SELECT * FROM [dbo].[employee] " batchResults="true"> <emp_id key="true" /> <fname /> <hire_date type="datetime" /> <job_id /> <job_lvl /> <lname /> <minit /> <pub_id /> </employee> </Items>
尚、batchResultsが有効になっている場合、処理中にエラーが発生すると、どのレコードがエラーだったかを特定するのが難しくなることがありますのでご注意ください。
SharePoint ライブラリとの連携
今回は SharePoint の「リスト」へ連携する方法をご紹介しましたが、CData Arc はファイル転送(MFT)も得意です。SharePoint ライブラリとファイル連携したい場面でも活用頂けます。こちらはまた別の記事でご紹介したいと思います。
おわりに
このように、CData Arc と CData SharePoint ADO.NET Providerを活用することで、SQL Server から SharePoint Online リストへの連携処理を簡単に構築することができました。
今回は、データベースから SaaS への連携シナリオをご紹介しましたが、CData Arc はシンプルで拡張性の高いコアフレームワークに、豊富なMFT・EDI・エンタープライズコネクタを備えたパワフルな製品です。CData Drivers との組み合わせで100を超えるアプリケーションへの連携を実現できます。
クラウド/オンプレミスのファイル連携、業界標準のEDI、数多くの SaaS のAPI をノーコードでつなぐ事ができます。皆さんのつなぎたいシナリオでぜひ CData Arc を試してみてください。