ノーコードでクラウド上のデータとの連携を実現。
詳細はこちら →Amazon S3 Driver の30日間無償トライアルをダウンロード
30日間の無償トライアルへCData


こんにちは!ウェブ担当の加藤です。マーケ関連のデータ分析や整備もやっています。
Informatica は、データを転送・変換するための強力で立派な手段を提供します。CData JDBC Driver for AmazonS3 を利用することで、Informatica のEnterprise Data Catalog とシームレスに統合される、業界で実証済みの標準に基づくドライバーにアクセスできます。このチュートリアルでは、どんな環境でもAmazon S3 データを分類・整理する方法を説明します。
以下はJDBC ドライバーをロードする方法です。
$ java -jar setup.jar
$ cd ~/cdata-jdbc-driver-for-amazons3/lib
$ zip genericJDBC.zip cdata.jdbc.amazons3.jar cdata.jdbc.amazons3.lic
# mv genericJDBC.zip /opt/informatica/services/CatalogService/ScannerBinaries
# cd /opt/informatica/services/CatalogService/ScannerBinaries/CustomDeployer/
# nano scannerDeployer.xml
既存のExecutionContextProperty ノードを解凍したら、このコンテンツを含む新しいExecutionContextProperty ノードを追加します。
<ExecutionContextProperty
isLocationProperty="true"
dependencyToUnpack="genericJDBC.zip">
<PropertyName>JDBCScanner_DriverLocation</PropertyName>
<PropertyValue>scanner_miti/genericJDBC/Drivers</PropertyValue>
</ExecutionContextProperty>
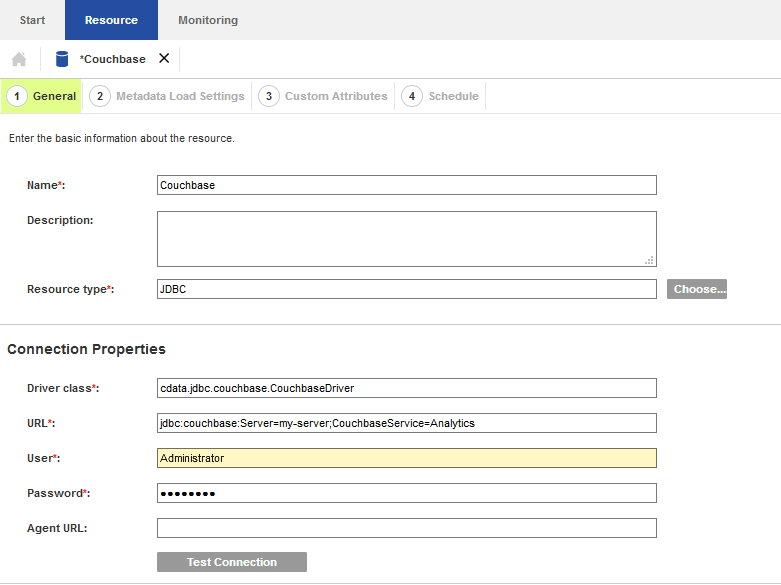
以下の手順でJDBC リソースを構成します。
jdbc.amazons3:AccessKey=a123;SecretKey=s123;Amazon S3 リクエストを認可するには、管理者アカウントまたはカスタム権限を持つIAM ユーザーの認証情報を入力します。AccessKey をアクセスキーID に設定します。SecretKey をシークレットアクセスキーに設定します。
Note: AWS アカウント管理者として接続できますが、AWS サービスにアクセスするにはIAM ユーザー認証情報を使用することをお勧めします。
尚、CData 製品はAmazon S3 のファイルの一覧表示やユーザー管理情報の取得用です。S3 に保管されているExcel、CSV、JSON などのファイル内のデータを読み込みたい場合には、Excel Driver、CSV Driver、JSON Driver をご利用ください。
IAM ユーザーの資格情報を取得するには:
AWS ルートアカウントの資格情報を取得するには:
多くの場合、認証にはAWS ルートユーザーのダイレクトなセキュリティ認証情報ではなく、IAM ロールを使用することをお勧めします。RoleARN を指定することでAWS ロールを代わりに使用できます。これにより、CData 製品は指定されたロールの資格情報を取得しようと試みます。
(すでにEC2 インスタンスなどで接続されているのではなく)AWS に接続している場合は、ロールを引き受けるIAM ユーザーのAccessKey とSecretKey を追加で指定する必要があります。AWS ルートユーザーのAccessKey および SecretKey を指定する場合、ロールは使用できません。
SSO 認証を必要とするユーザーおよびロールには、RoleARN およびPrincipalArn 接続プロパティを指定してください。各Identity Provider に固有のSSOProperties を指定し、AccessKey とSecretKey を空のままにする必要があります。これにより、CData 製品は一時的な認証資格情報を取得するために、リクエストでSSO 認証情報を送信します。
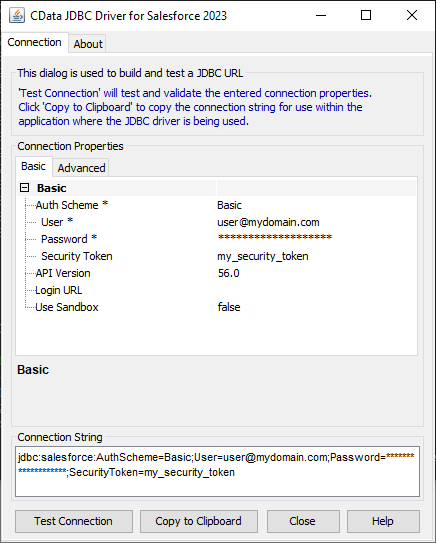
JDBC URL の構成については、Amazon S3 JDBC Driver に組み込まれている接続文字列デザイナを使用してください。.jar ファイルのダブルクリック、またはコマンドラインから.jar ファイルを実行します。
java -jar cdata.jdbc.amazons3.jar
接続プロパティを入力し、接続文字列をクリップボードにコピーします。
JDBC URL を構成する際に、Max Rows プロパティを定めることも可能です。これによって戻される行数を制限するため、可視化・レポートのデザイン設計時のパフォーマンスを向上させるのに役立ちます。
以下は、一般的な追加の接続文字列プロパティです。
JDBC;MSTR_JDBC_JAR_FOLDER=PATH\TO\JAR\;DRIVER=cdata.jdbc.amazons3.AmazonS3Driver;URL={jdbc:amazons3:AccessKey=a123;SecretKey=s123;};
使用しているドライバーに要求されなくても、ユーザー名とパスワードのプロパティは必須であることに注意してください。そのようなケースでは、代わりにプレスホルダー値を入力できます。
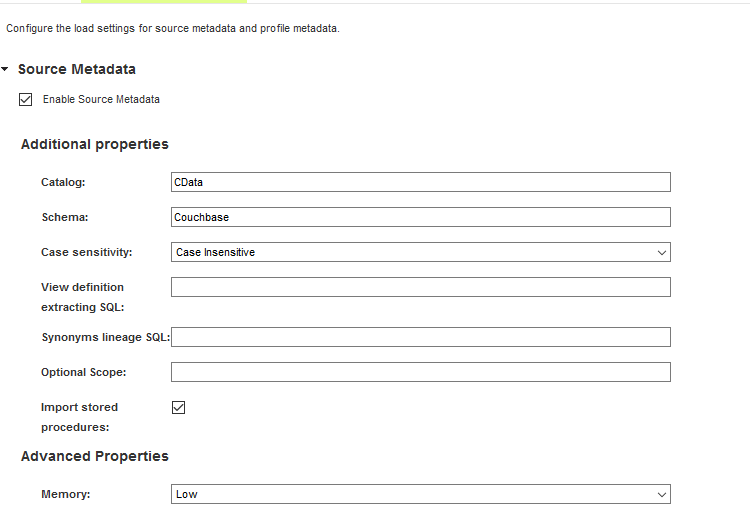
他のメタデータスキャナーは、必要に応じて有効にすることができます。
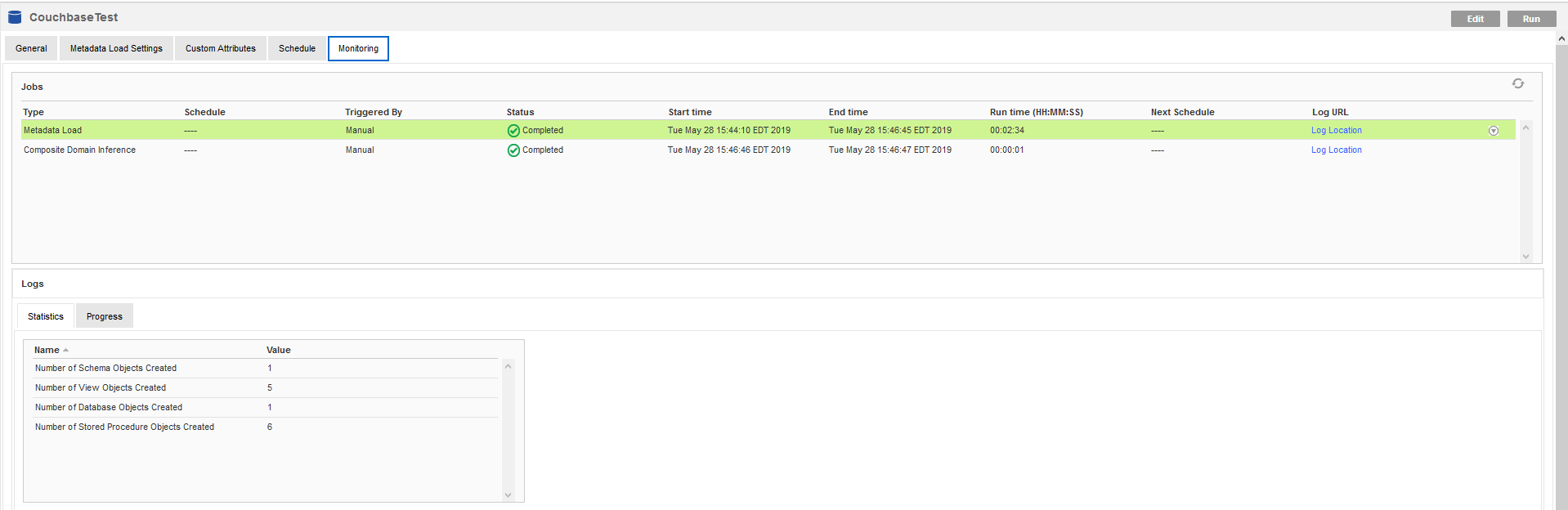
スキャンが完了すると、すべてのメタデータオブジェクトの概要が[Metadata Load job]のステータスとともに表示されます。エラーが発生した場合、[Log Location]リンクを開き、インフォマティカまたはドライバーから報告されたエラーを確認できます。
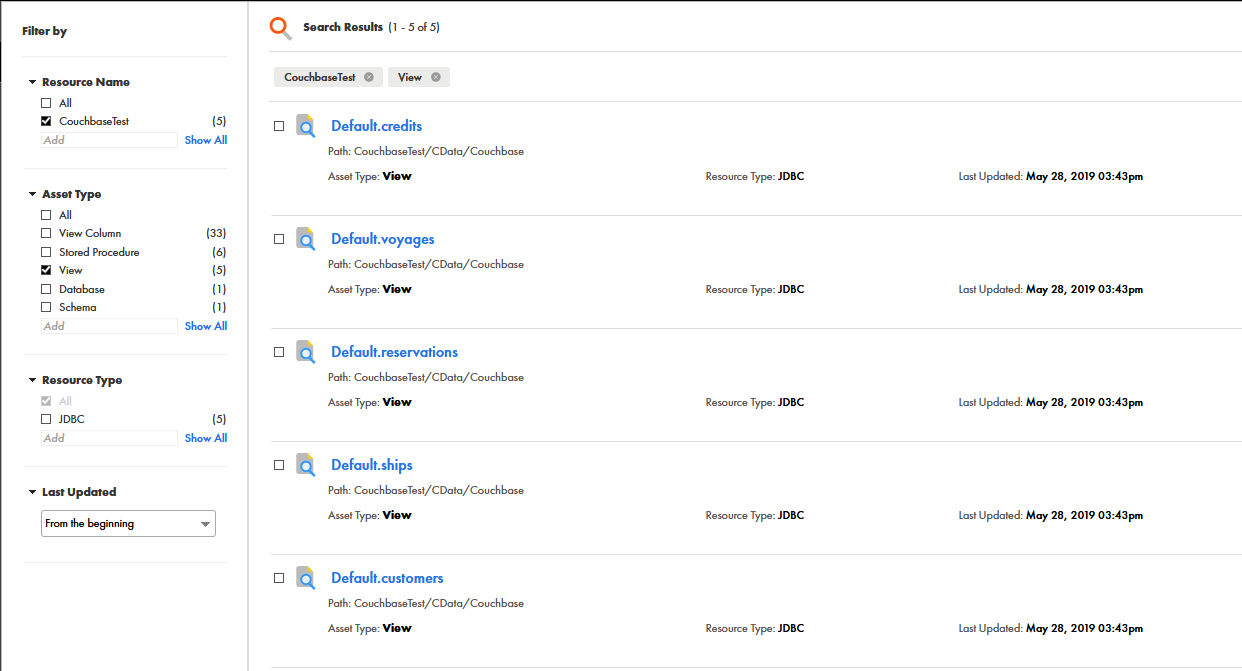
[Catalog Service]を開き、データソースから検出されたメタデータを表示します。メタデータスキャナーの構成時に選択したオプションによっては、定義したリソースのテーブル、ビュー、ストアドプロシージャの任意の組み合わせが表示される場合があります。