ノーコードでクラウド上のデータとの連携を実現。
詳細はこちら →Backlog Driver の30日間無償トライアルをダウンロード
30日間の無償トライアルへCData


こんにちは!リードエンジニアの杉本です。
Apache Solr https://lucene.apache.org/solr/は Apache ソフトウェア財団のLucene プロジェクトのサブプロジェクトとして開発されているオープンソースの全文検索エンジンです。
API・データストアや各種データを取り込むためのデータインポート(Data Import Handler)を備えているので、手軽に独自アプリケーションに検索エンジンを組み込むことができるようになっています。通常 Apache Solr はXML・CSV・JSON といったフォーマットやPDF、Word、HTML などのファイル、もしくはJDBC 経由でのRDB 接続で取得したデータのみが取り込み対象ですが、Apache Solr のJDBC のインターフェースにCData JDBC ドライバを用いることで、各API の仕様を意識せず DataImport を実行でき、Apache Solr のエンジンでBacklog データを検索することができるようになります。 今回は Apache Solr が提供するデータインポート機能、Data Import Handler を使って、Backlog データを取り込み、Apache Solr で検索が実施できるようにするための手順を紹介します。
> solr create -c CDataCore
これでドライバーの配置などの準備は完了です。
それではデータ処理を担う機能であるDIH(DataImport Handler)の定義を追加しましょう。
solr-data-config.xml
> solr stop -all
> solr start
再起動後、以下のURL からDataImport を実行できます。
http://localhost:8983/solr/#/CDataCore/dataimport//dataimport
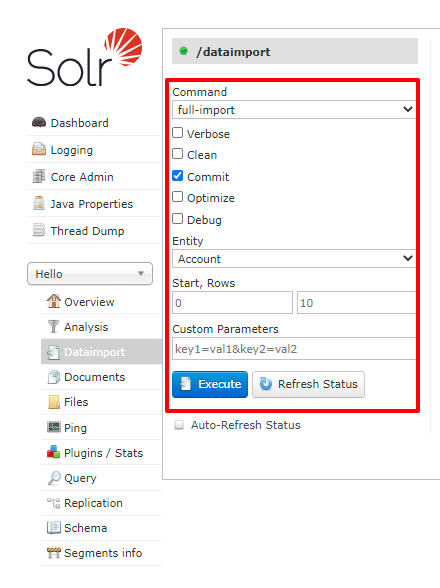
まず「full-import」、Entity から「テーブル名」を選択して、「Execute」してみます。
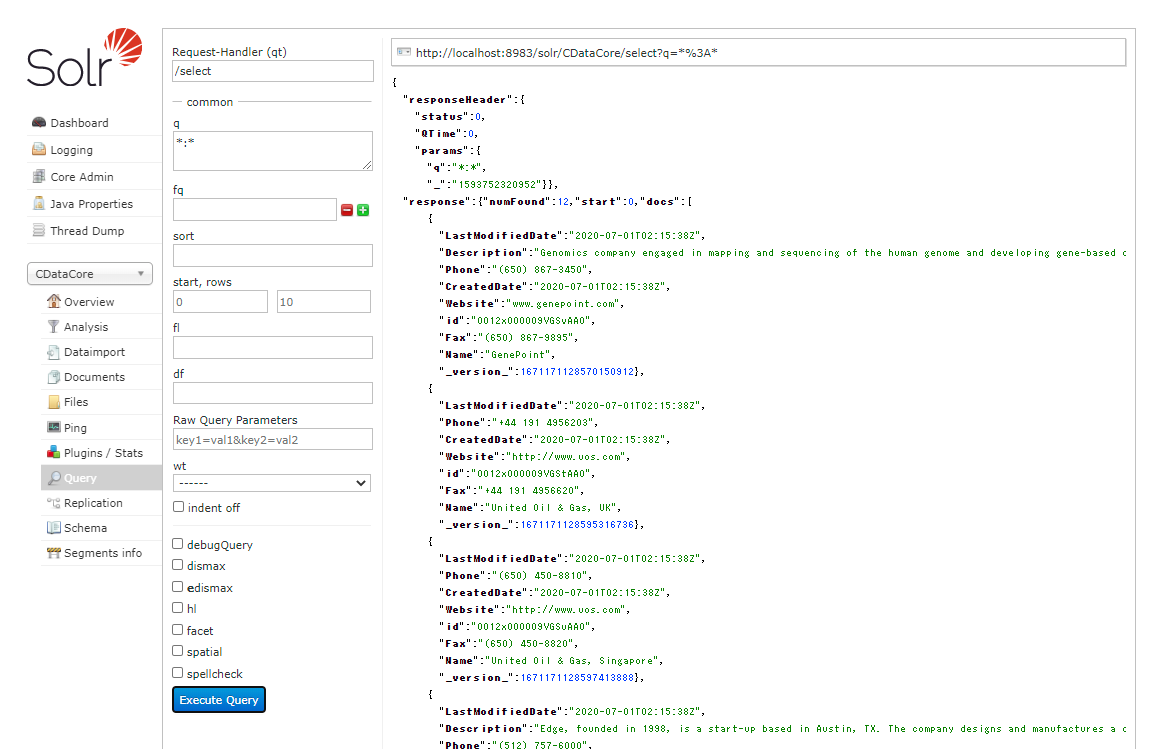
登録された結果を「Query」画面から見てみると、各スキーマにデータが取り込まれていることが確認できました。
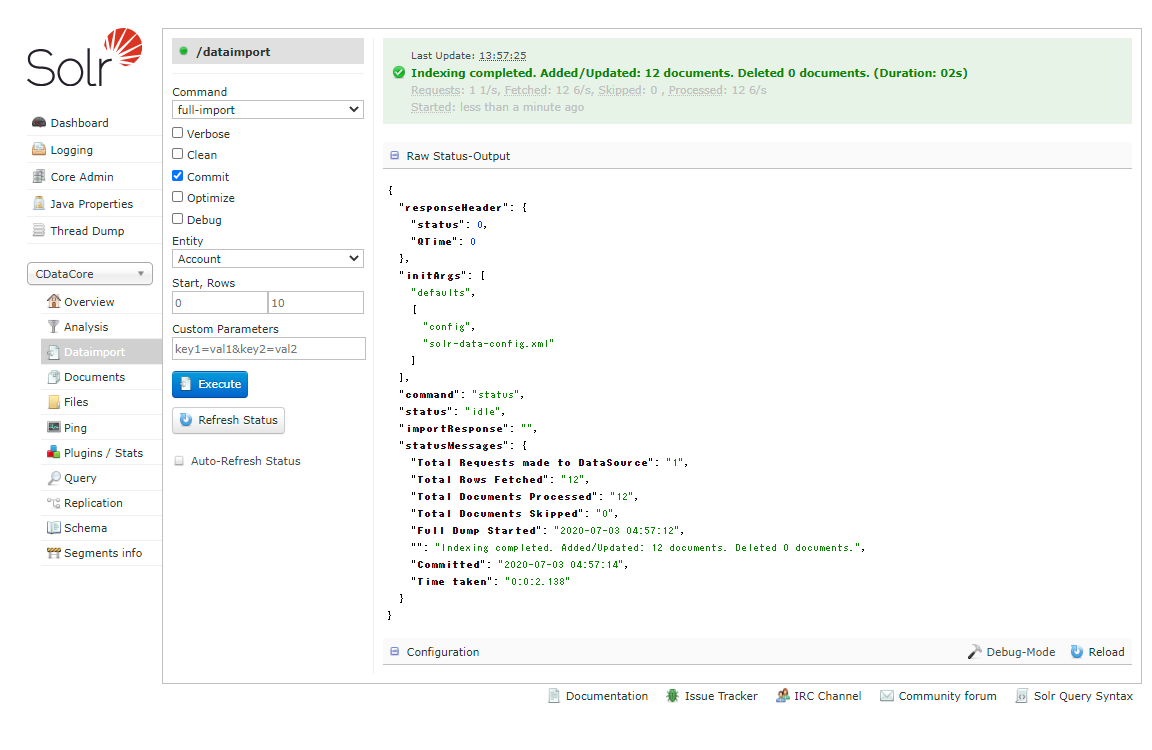
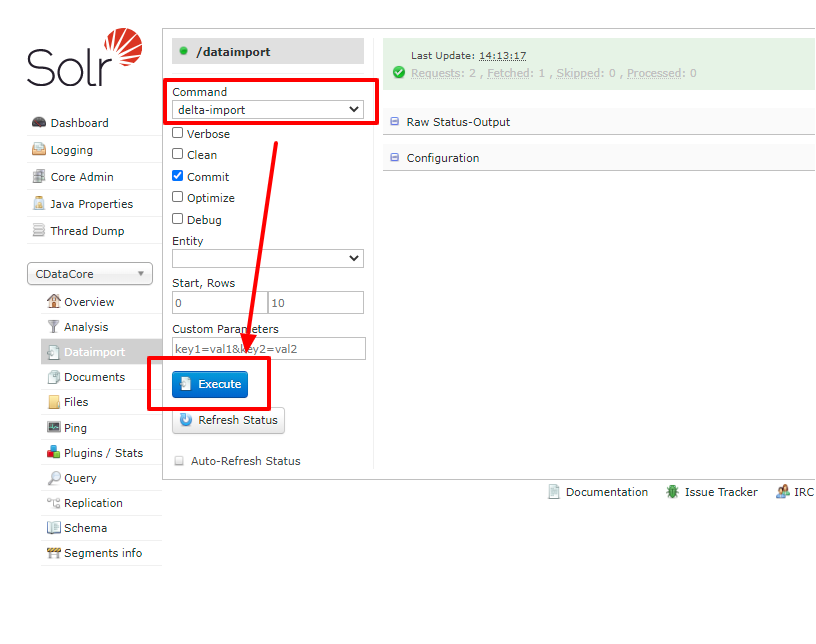
次に差分更新であるDeltaQuery も試してみましょう。Backlog 側のデータを書き換えてください。DataImport の画面から今度は「Delta-Import」を選択して、Execute を押してみます。
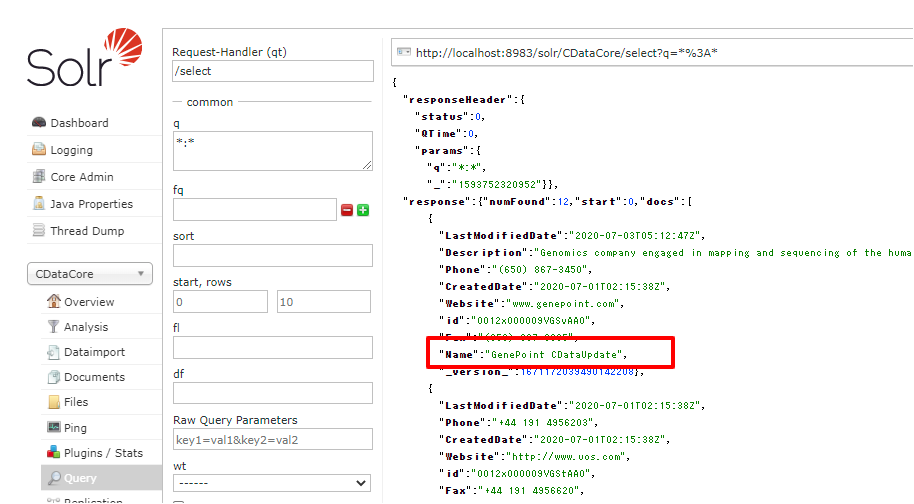
正常に取り込みが完了すると、以下のようにレコードが更新されていることが確認できました。
このようにCData JDBC ドライバとSolr Data Import Handler を一緒に使うことで、簡単にSolr でBacklog データをノーコードで連携し、全権検索に使うことが可能です。
是非、CData JDBC Driver for Backlog 30日の無償評価版 をダウンロードして、お試しください。