ノーコードでクラウド上のデータとの連携を実現。
詳細はこちら →Confluence Driver の30日間無償トライアルをダウンロード
30日間の無償トライアルへCData


こんにちは!プロダクトスペシャリストの宮本です。
Google Cloud Data Fusion は、ノーコードでデータ連携の設定が可能な言わば GCP の ETL ツール(サービス)です。たくさんのコネクタや変換・分析機能がデフォルトで用意されているため、さまざまなデータソースを色々な組み合わせで扱うことが可能なようです。 また JDBC を扱うこともできるため、この記事では、CData JDBC Driver for Confluence データ を使って、Confluence データ データをCloud Data Fusion でGoogle BigQuery にノーコードでパイプラインします。
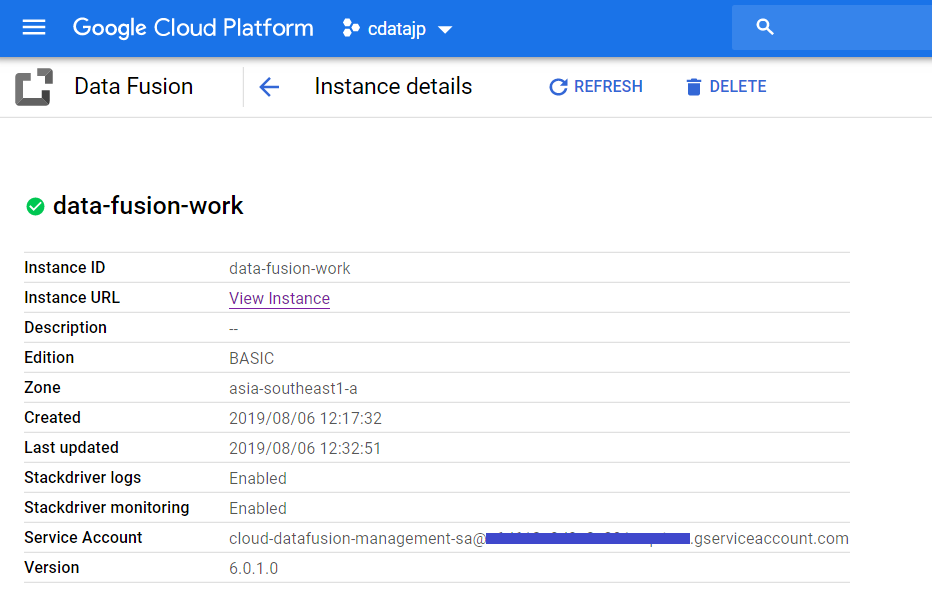
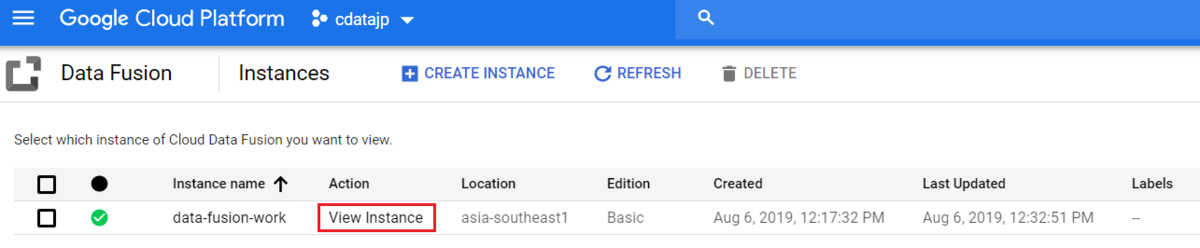
まずはCloud Data Fusion のインスタンスを作成します。
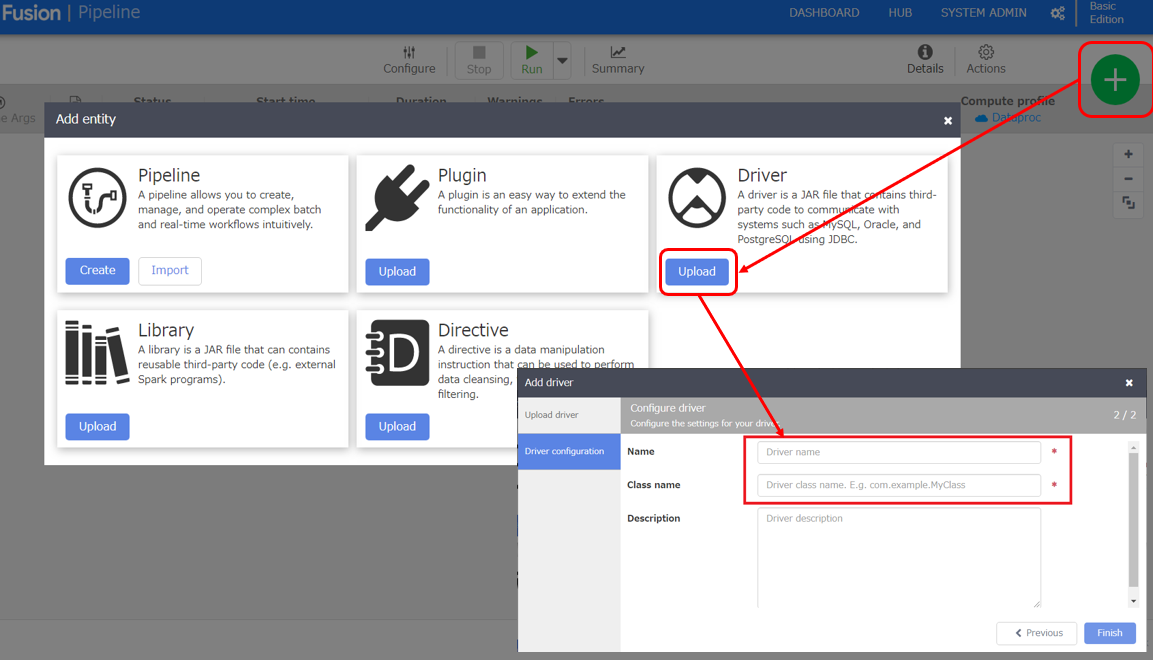
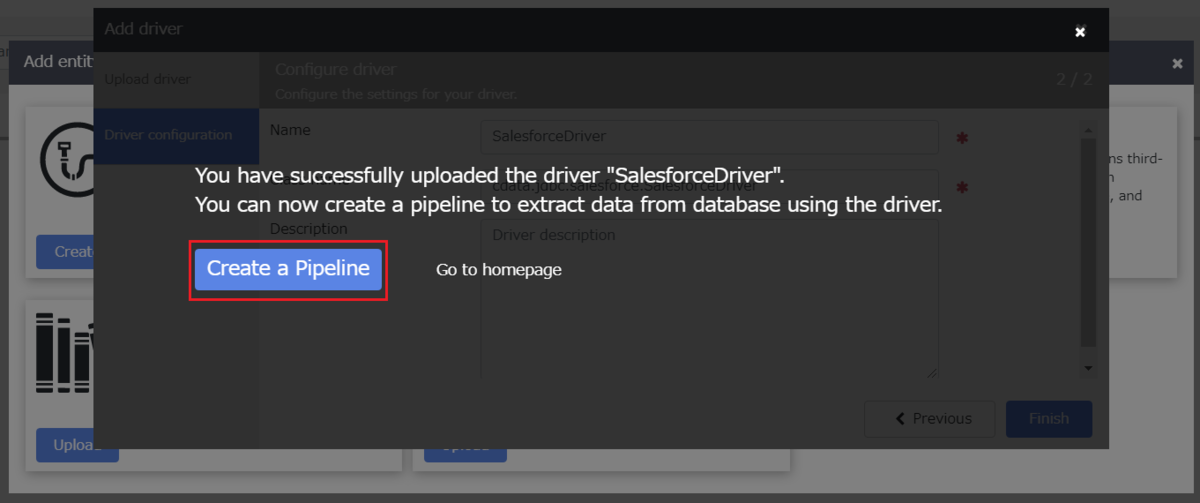
ここからは実際に、Data Fusion の設定をしていきます。 まずは JDBC Driver をアップロードを行います。
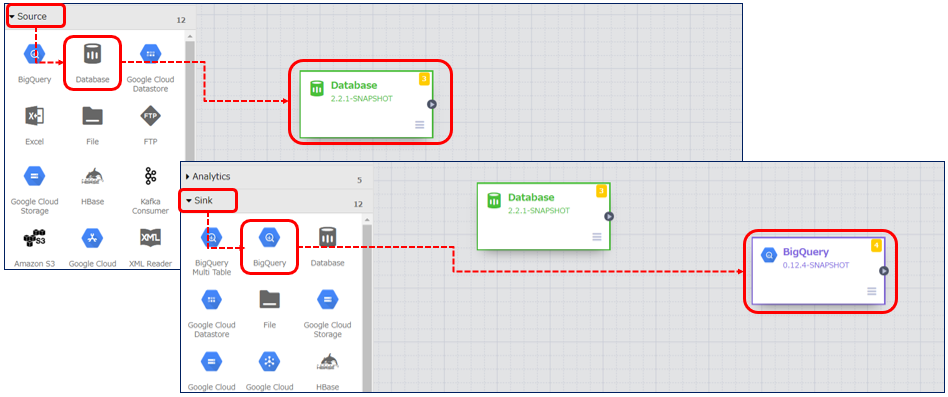
インプット元はサイドメニューの「Source」から選択します。今回は先ほどアップロードした Confluence データ の JDBC Driver を使用するため、「DataBase」を選択します。 アウトプット先は同じくサイドメニューより「Sink」→「BigQuery」を選択します。
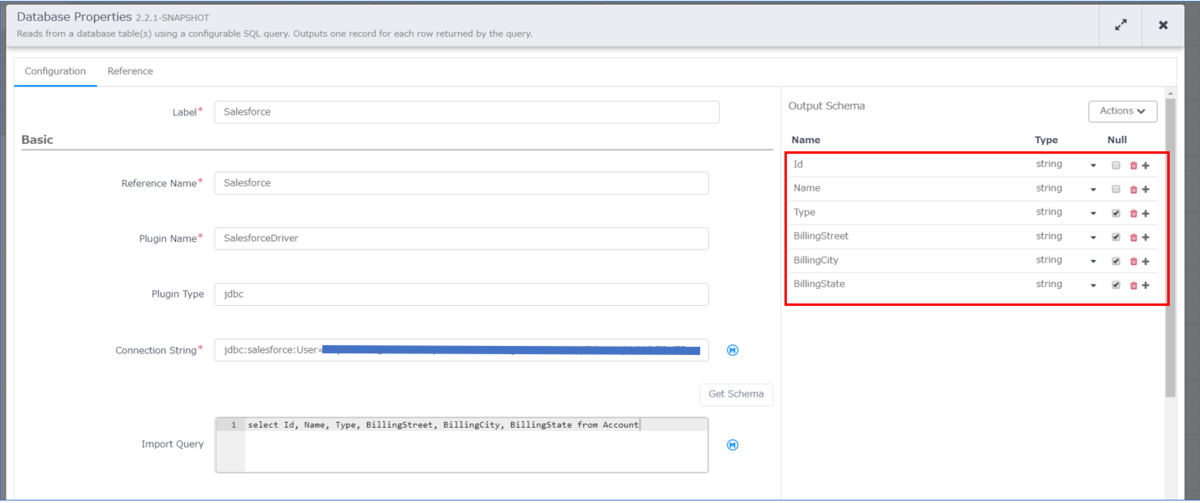
「DataBase」のアイコンにカーソルを持ってくるとプロパティというボタンが表示されるのでクリックし、下記内容を設定します。
API token は、アカウントへの認証に必須です。トークンの生成には、Atlassian アカウントでサービスにログインし、API tokens > Create API token に進みます。生成されたトークンが表示されます。
Cloud アカウントへの接続には、以下のプロパティを設定します(Password は、Server Instance への接続時のみ必要で、Cloud Account への接続には不要になりました。):
Server instance への接続には以下を設定します:
Connection String は以下の形式です。
jdbc:confluence:User=admin;APIToken=myApiToken;Url=https://yoursitename.atlassian.net;Timezone=America/New_York;
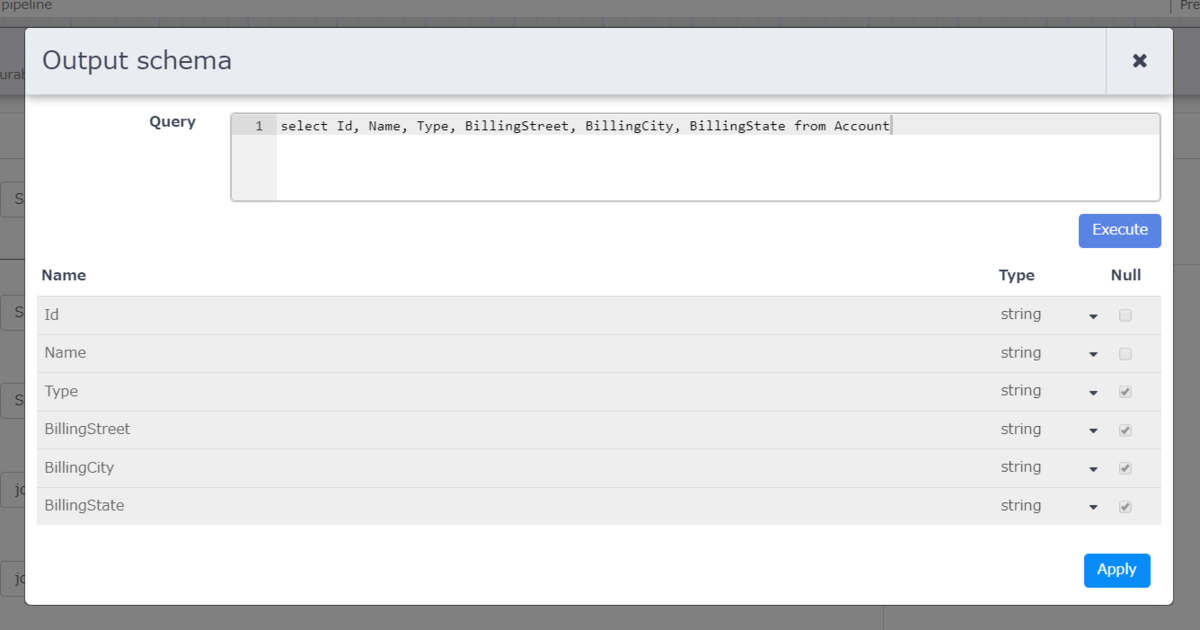
上のキャプチャの赤枠は、Salesforce から BigQuery へアウトプットするデータの定義となります。 こちらは「Import Query」のすぐ右上にある「Get Schema」をクリックすると下の画面が表示されますので、「Import Query」で入力したクエリを実行し、カラムを定義します。
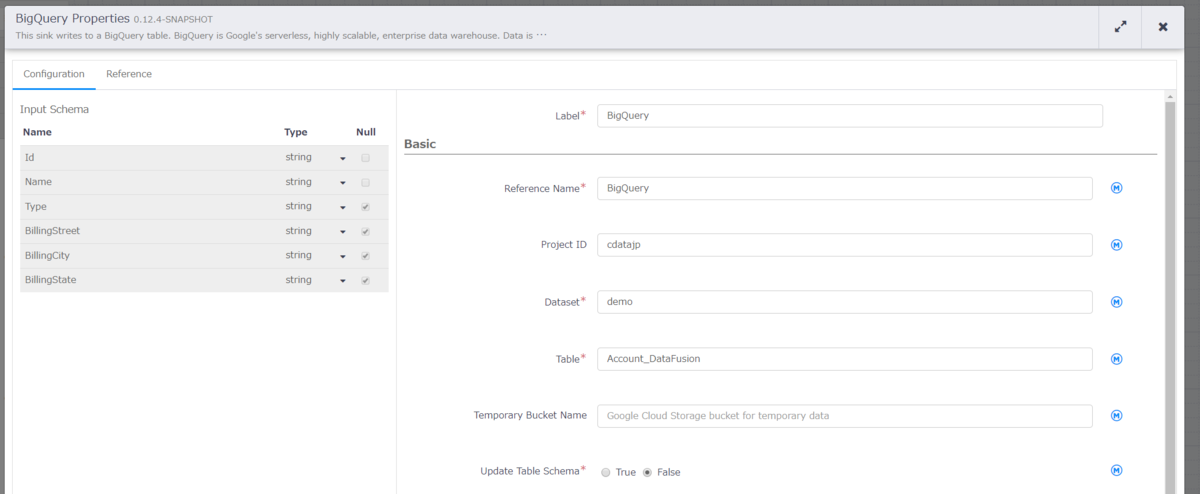
こちらも同様に BigQuery のプロパティから下記内容を設定します。
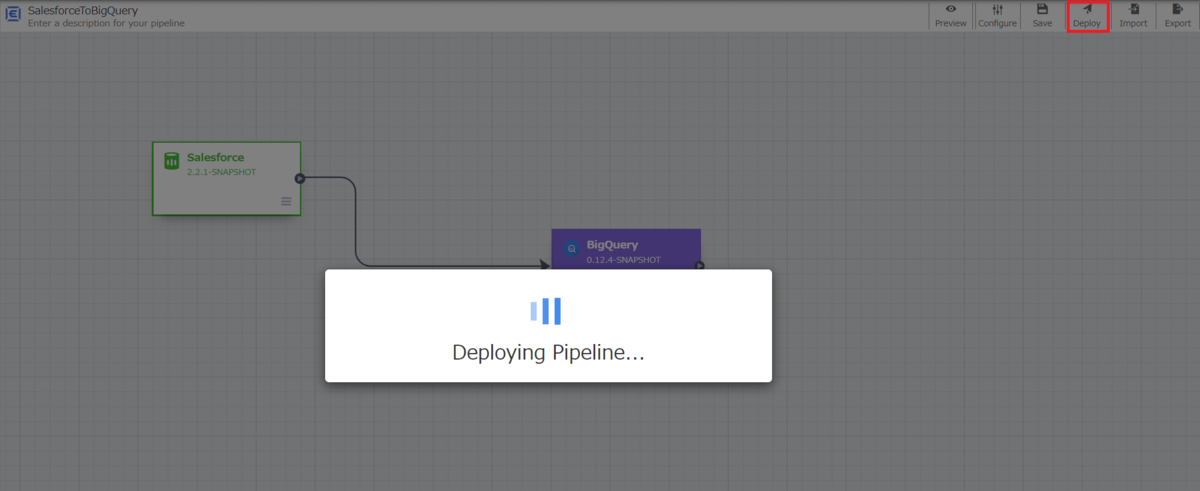
まずは作成したパイプラインをデプロイします。赤枠の「Deploy」ボタンをクリックしてデプロイを行います。
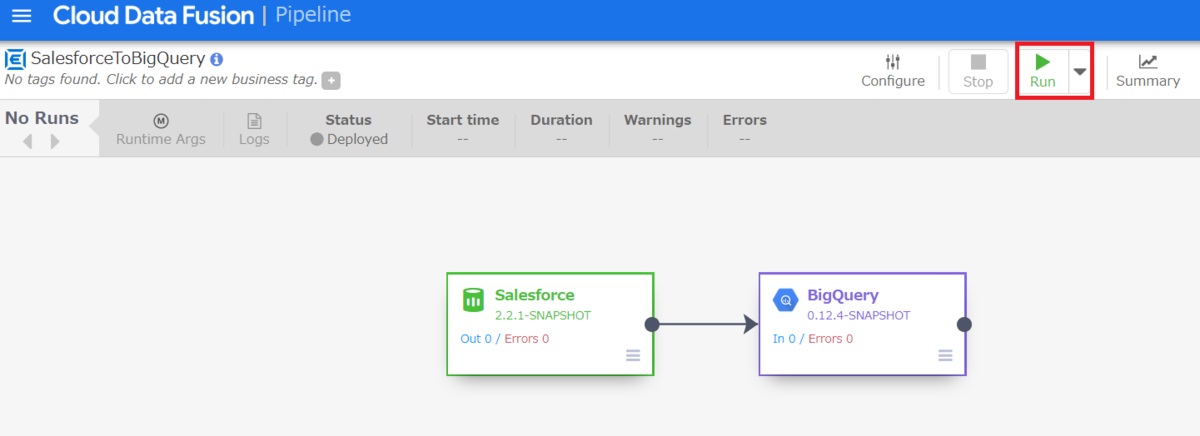
デプロイ完了後、Runボタンが表示されますので、クリックします。
このようにCData JDBC ドライバをアップロードすることで、簡単にGoogle Cloud Data Fusion でConfluence データ データをノーコードで連携し、BigQuery などへのパイプラインを作成することができます。
是非、CData JDBC Driver for Confluence 30日の無償評価版 をダウンロードして、お試しください。