ノーコードでクラウド上のデータとの連携を実現。
詳細はこちら →Spanner Driver の30日間無償トライアルをダウンロード
30日間の無償トライアルへCData


こんにちは!リードエンジニアの杉本です。
CData JDBC Driver for GoogleSpanner は、JDBC 標準をインプリメントし、BI ツールからIDE まで幅広いアプリケーションでGoogle Spanner への接続を提供します。この記事では、超高速開発ツールであるWagby からGoogle Spanner に接続一覧表示する方法を説明します。
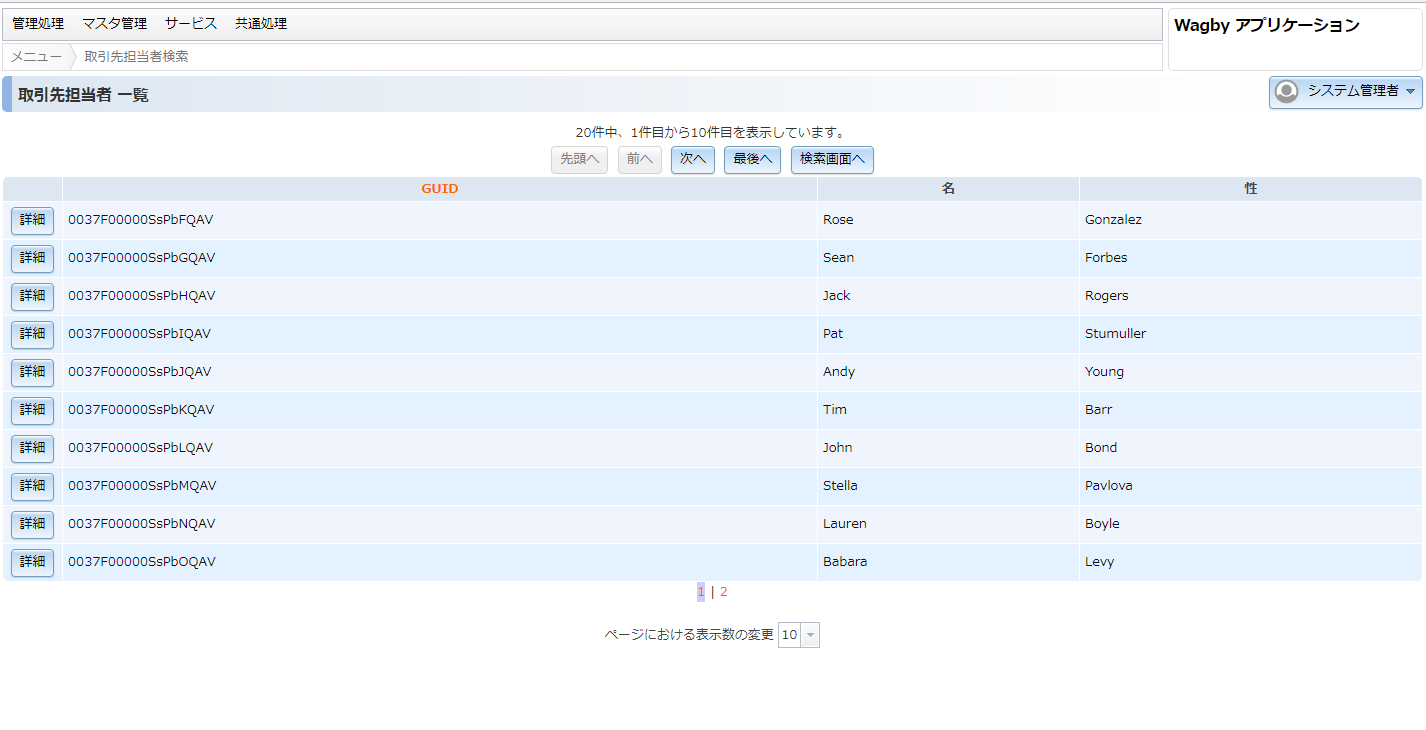
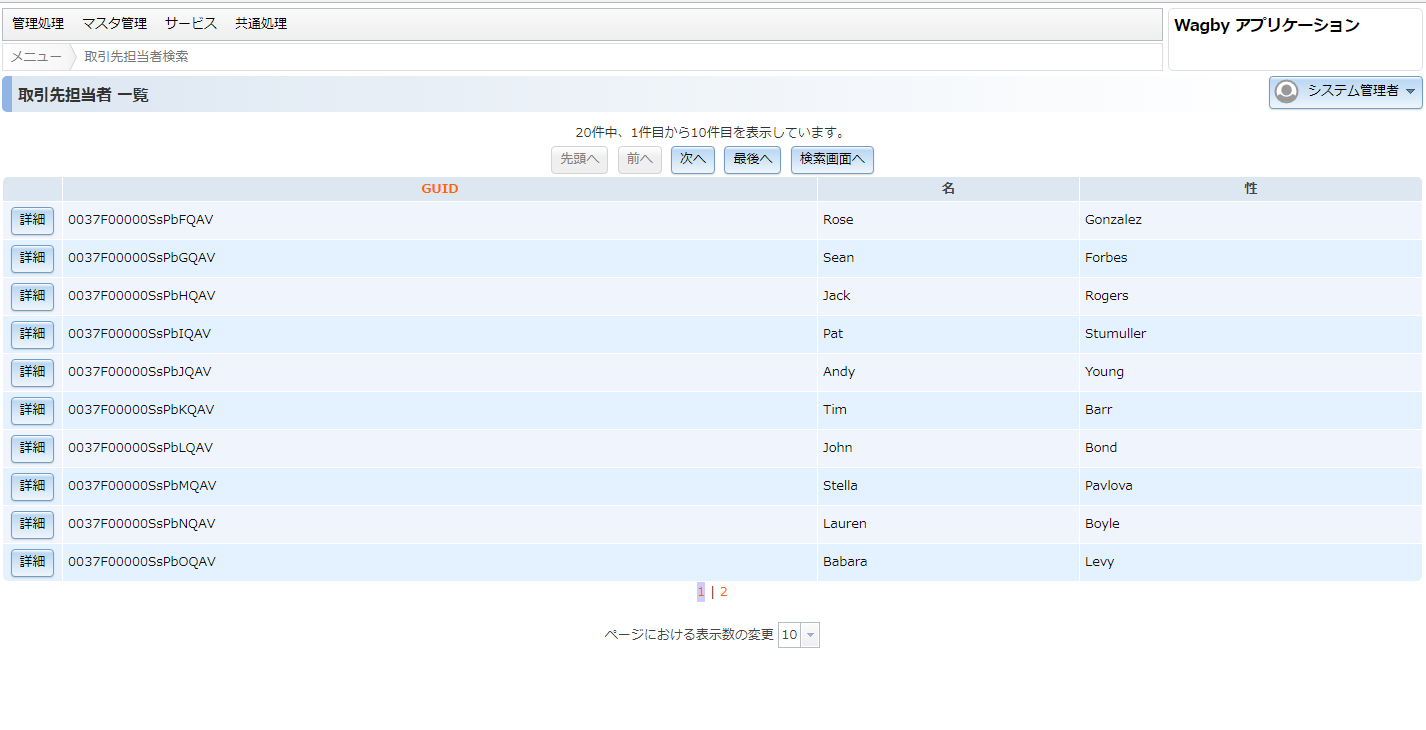
以下のようにWagbyの一覧画面で Google Spanner から取得したデータを表示する画面を作成します。
まず、WagbyとGoogle Spannerの連係のために使用するCData Google Spanner JDBC Driverのダウンロード・インストールを実施します。
CData Google Spanner JDBC Driverは下記URLより30日間試用版が入手できます。
https://www.cdata.com/jp/drivers/googlespanner/jdbc/
ダウンロード後、ZIPファイルを解凍しsetup.jarを実行します。
「cdata.jdbc.googlespanner.jar」
「cdata.jdbc.googlespanner.lic」
続いてCData DriverをWagbyで使用できるようにするための、データベース設定ファイルをWagby上へ配置します。
cdata.database_label=CData Google Spanner Driver
cdata.database_type=cdata
cdata.driver=cdata.jdbc.googlespanner.GoogleSpannerDriver
cdata.url=jdbc:googlespanner:ProjectId='project1';InstanceId='instance1';Database='db1';
cdata.quoteid=\"
cdata.quotewhere=
cdata.quoteidinwhere=\"
cdata.quoteidforhibernate=\"
cdata.hibernateDialect=jp.jasminesoft.jfc.hibernate.dialect.SQLServer2012Dialect
cdata.maxTablenameLength=128
cdata.maxIndexnameLength=128
cdata.maxColumnnameLength=128
cdata.maxLengthStringDataType=nvarchar(1000)
cdata.characterLargeObjectDataType=NVARCHAR(MAX)
cdata.supportTimeDataType=false
cdata.searchStringEscapeInLike=\\
cdata.createSequenceDDL=CREATE SEQUENCE $QUOTEID$SEQNAME$QUOTEID
$MINVALUE$MAXVALUESTART WITH $START NO CACHE CYCLE
cdata.sequenceDML=SELECT NEXT VALUE FOR $QUOTEID$SEQNAME$QUOTEID
cdata.springBatchDDL=batch_sqlserver.ddl
cdata.masterDDL=master_sqlserver2000.ddl
cdata.validationQuery=SELECT 1
それでは実際にWagbyで Google Spanner データを読み込むための設定を行っていきます。
Wagbyはシステムを構成するための基軸となるデータを保管するためのメインデータベースと外部データを参照するためのサブデータベースで構成されています。CData Driver はこのサブデータベースを利用することで、各データソースからシームレスにデータの参照を実施できます。
http://localhost:8920/wagbydesigner/logon.jsp
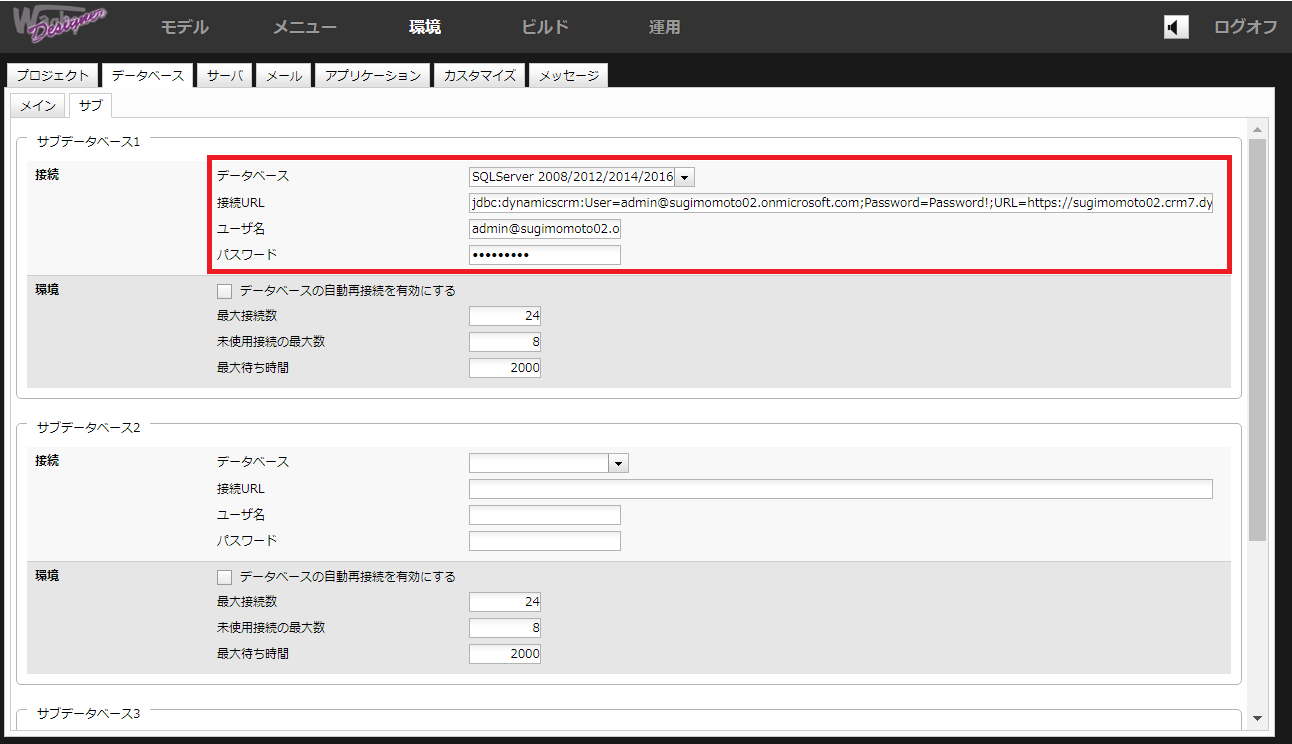
データベース:CData Google Spanner Driver
接続URL:jdbc:googlespanner:ProjectId='project1';InstanceId='instance1';Database='db1';
ユーザー名:使用しませんが、必須項目のため適当な文字列を入力します。
パスワード:使用しませんが、必須項目のため適当な文字列を入力します。
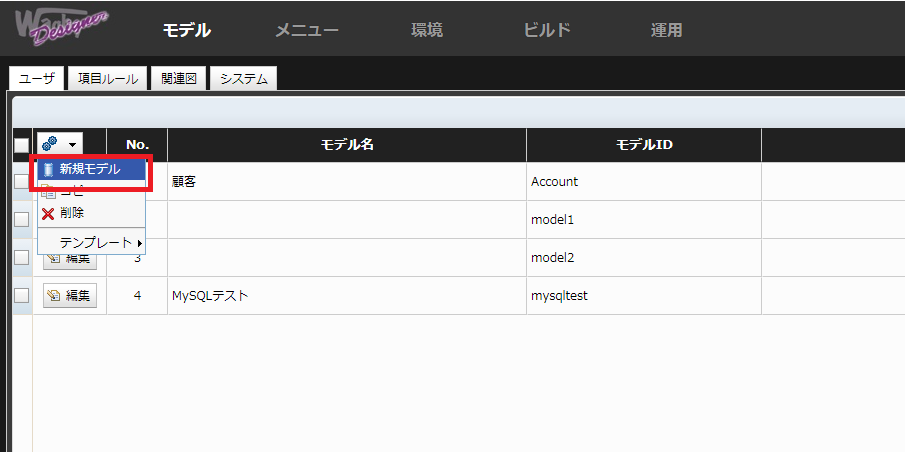
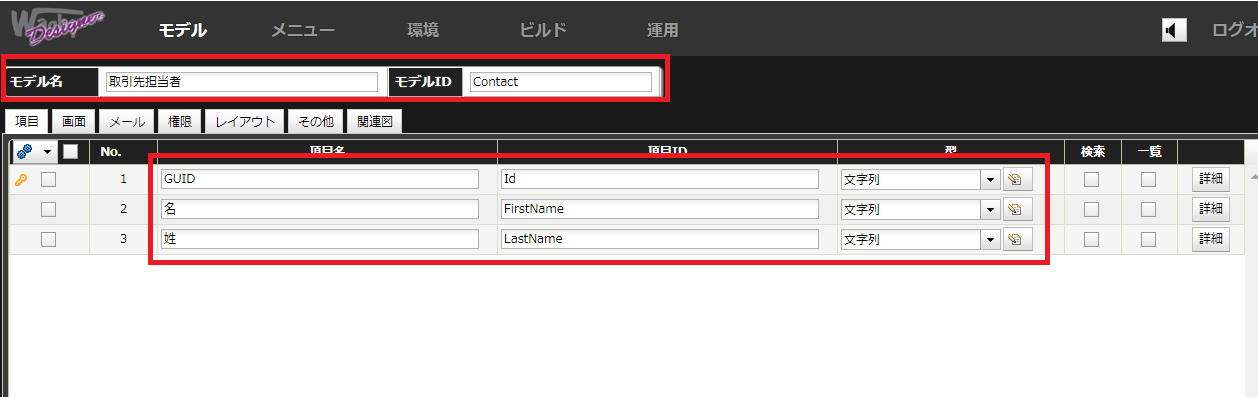
続いて、対象サービスと連携するモデルの作成を実施します。
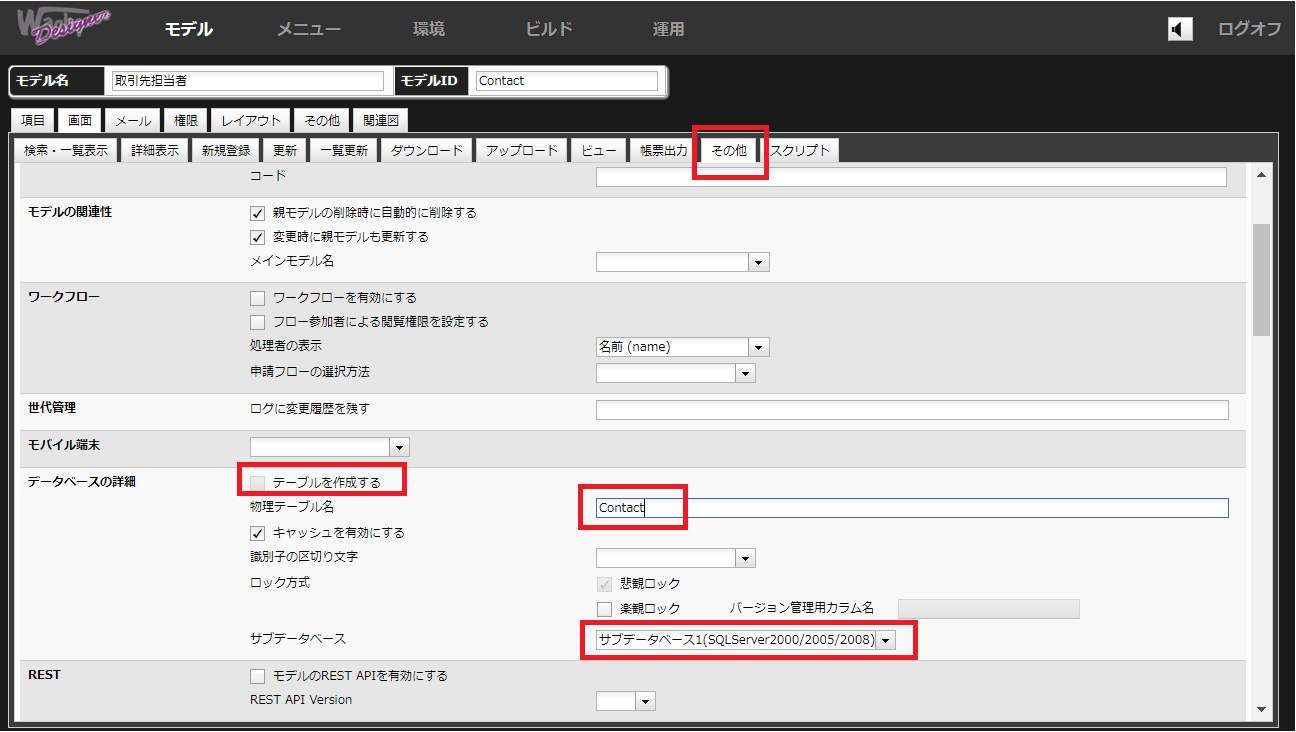
「テーブルを作成する」 ← チェックを外します。
「物理テーブル名」 ← 上記テーブル名と同じ名称を指定します。
「サブデータベース」 ← 手順2で指定したサブデータベースを選択します。
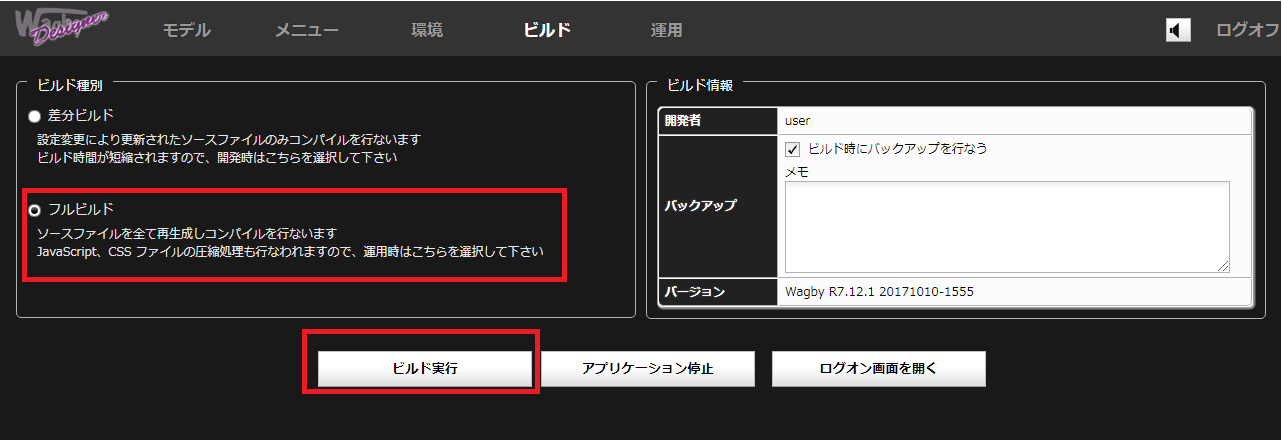
ビルドを実行し、サブデータベース・モデルの設定値をビルドファイルに反映させます。ビルドはサブデータベースを指定したため、フルビルドで行ってください。
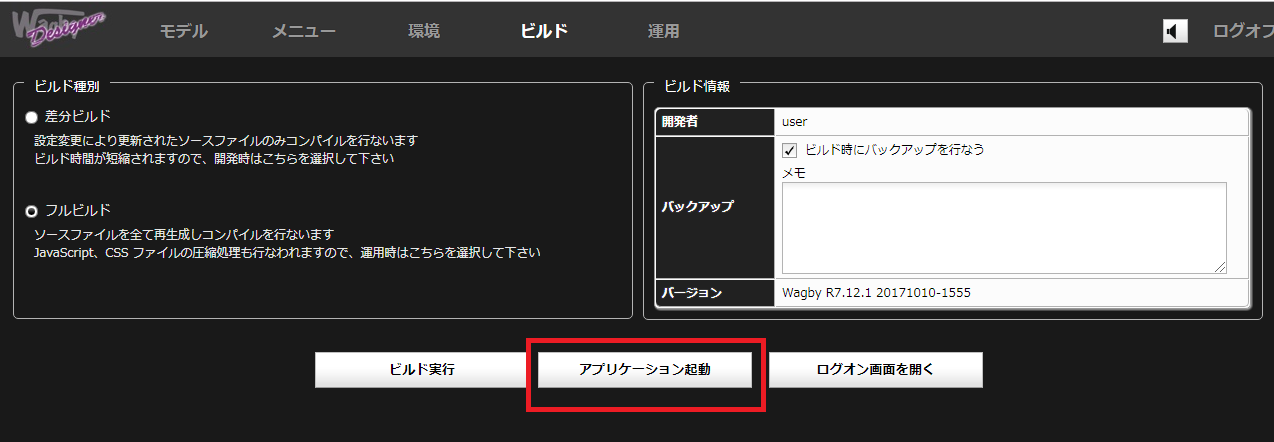
実際にユーザーが使用する画面を用いて、動作確認を実施します。
このように GoogleSpanner 内のデータを API を書くことなく Wagby 上で処理することができるようになります。
サポートされるSQL についての詳細は、ヘルプドキュメントの「サポートされるSQL」をご覧ください。テーブルに関する情報は「データモデル」をご覧ください。