ノーコードでクラウド上のデータとの連携を実現。
詳細はこちら →Apache Hive Driver の30日間無償トライアルをダウンロード
30日間の無償トライアルへCData


こんにちは!テクニカルディレクターの桑島です。
CData JDBC Driver for ApacheHive は、JDBC 標準をインプリメントし、BI ツールからIDE まで幅広いアプリケーションでHive への接続を提供します。この記事では、RACCOON からHive に接続し、CSV 出力する方法を説明します。
下記の手順に従って、RACCOON のプロジェクト・フォーマット変換定義を作成し、Hive のJDBC 抽出処理を作成します。
まずは、本記事右側のサイドバーからApacheHive JDBC Driver の無償トライアルをダウンロード・インストールしてください。30日間無償で、製品版の全機能が使用できます。
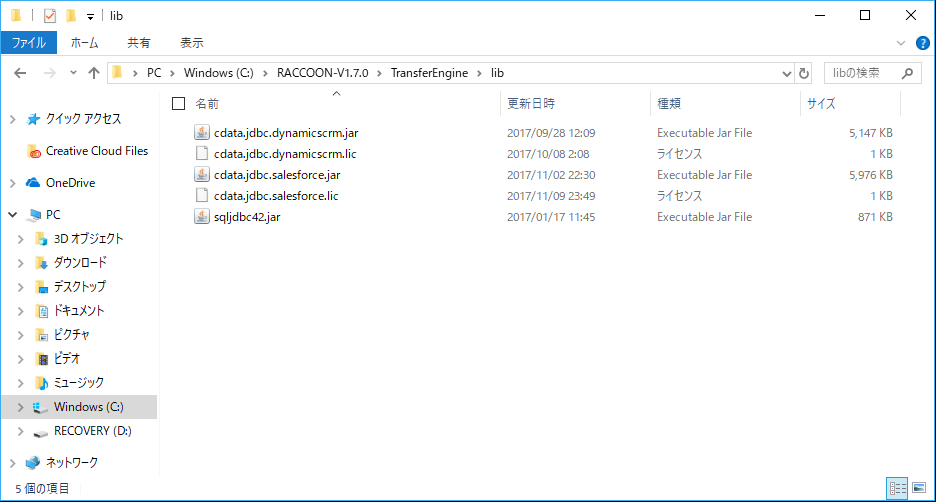
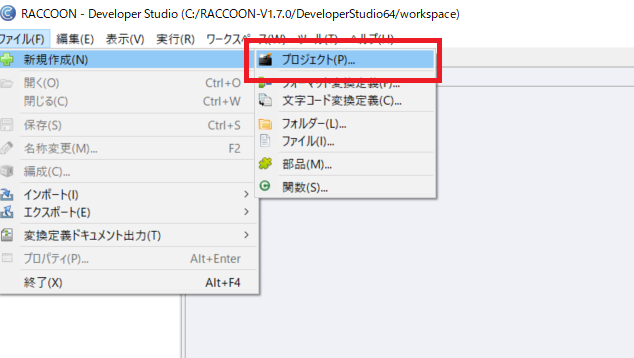
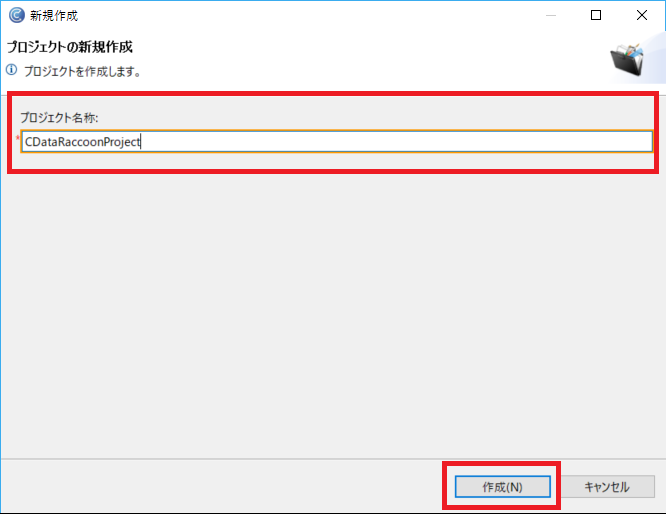
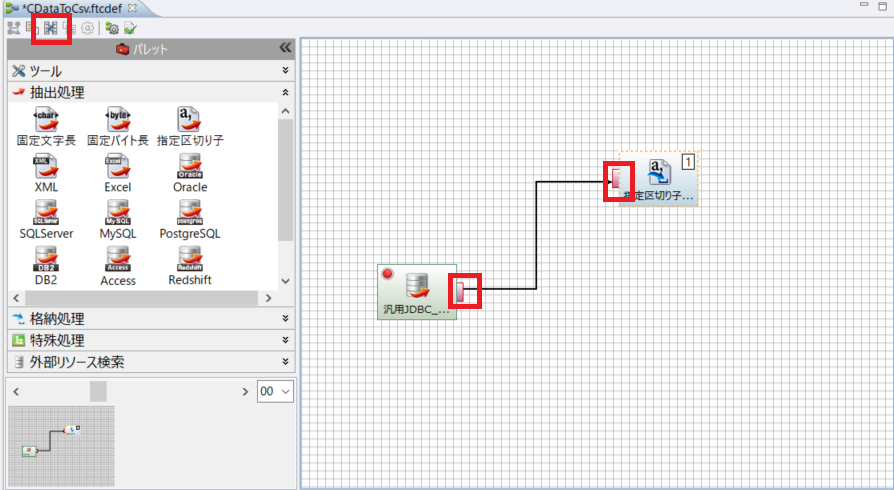
ここから、必要なファイルの配置とプロジェクトの作成を行います。
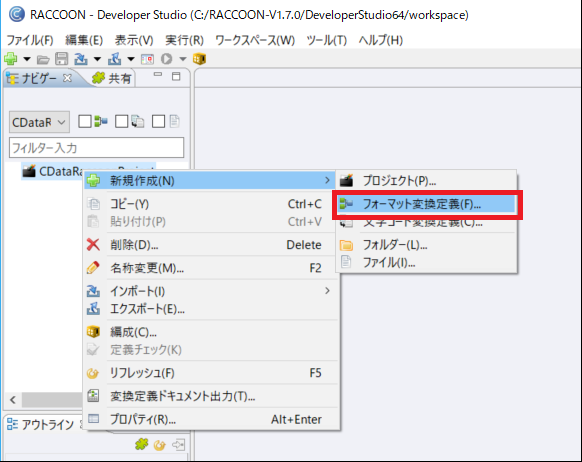
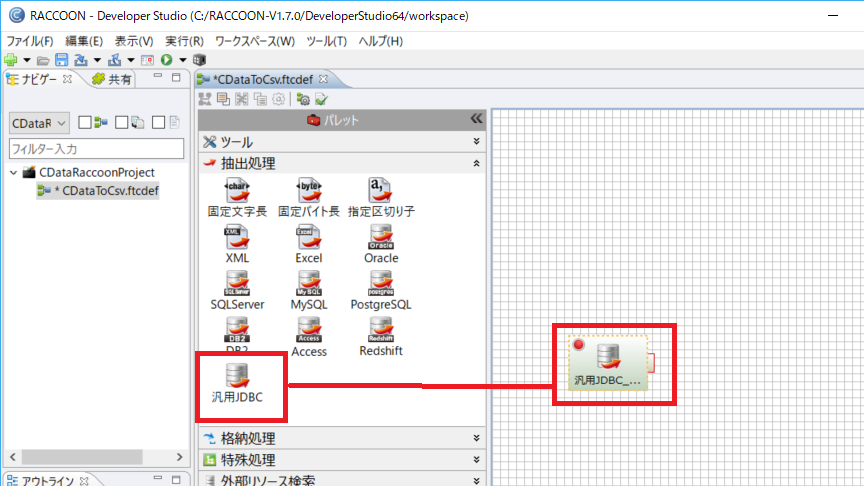
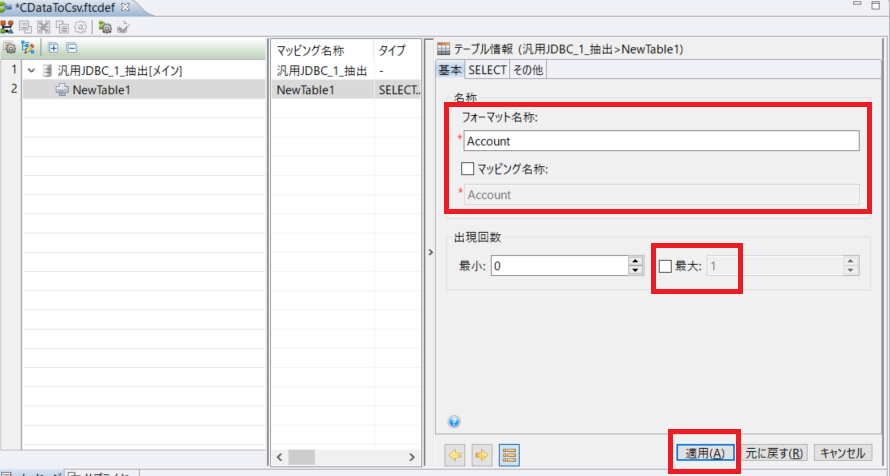
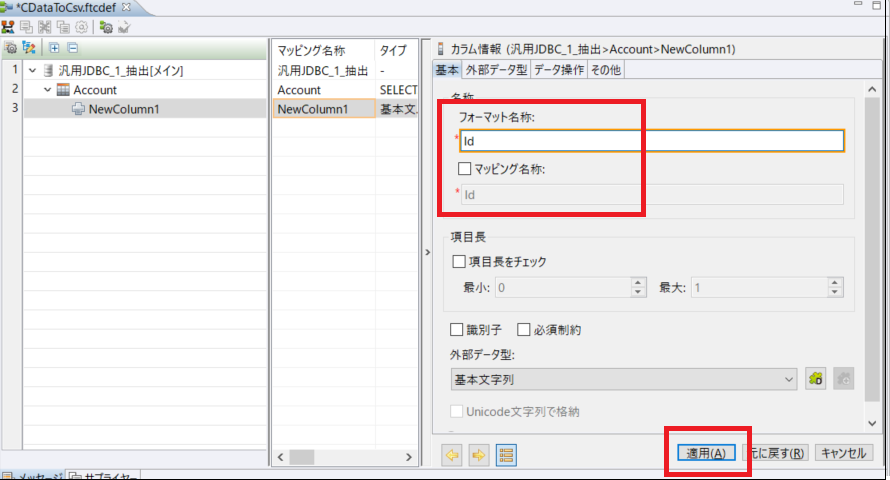
次にフォーマット変換定義を作成し、抽出処理を構成します。
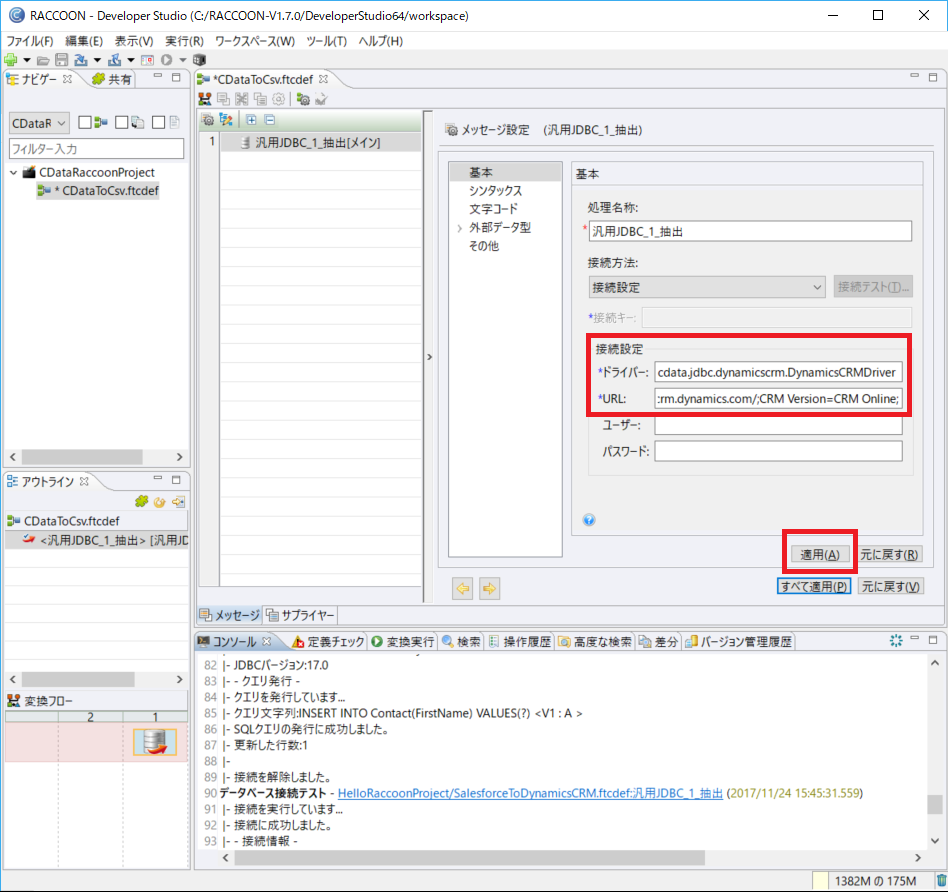
jdbc:apachehive:Server=127.0.0.1;Port=10000;TransportMode=BINARY;
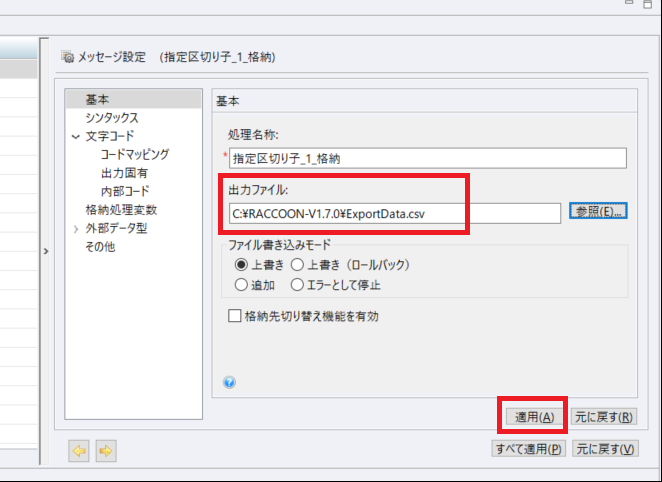
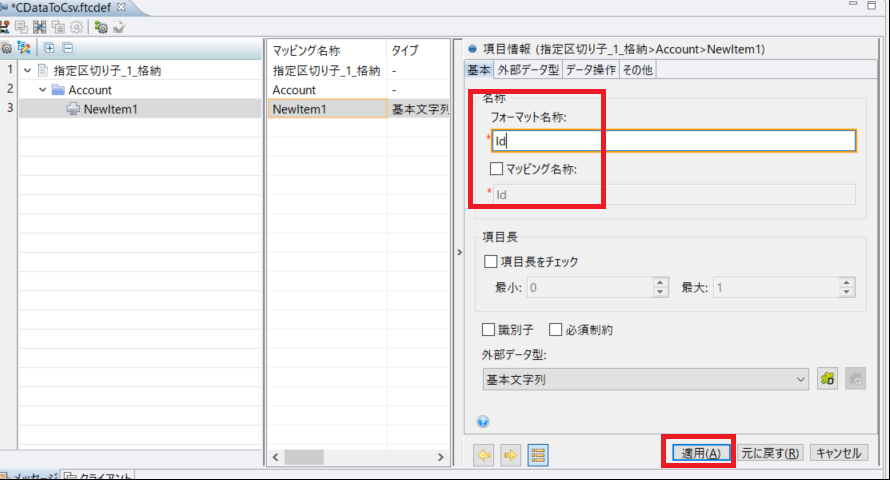
入力後、[適用]をクリックします。
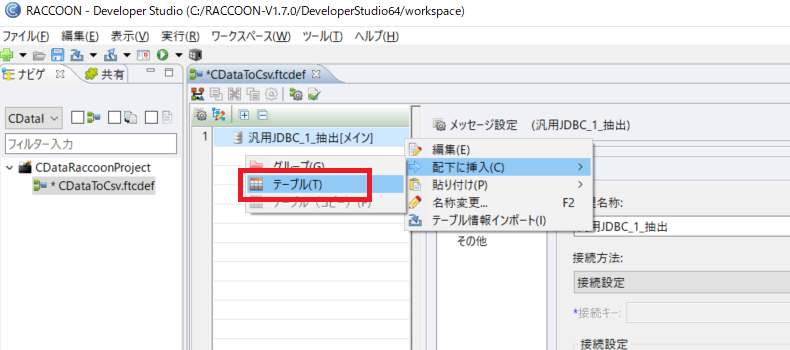
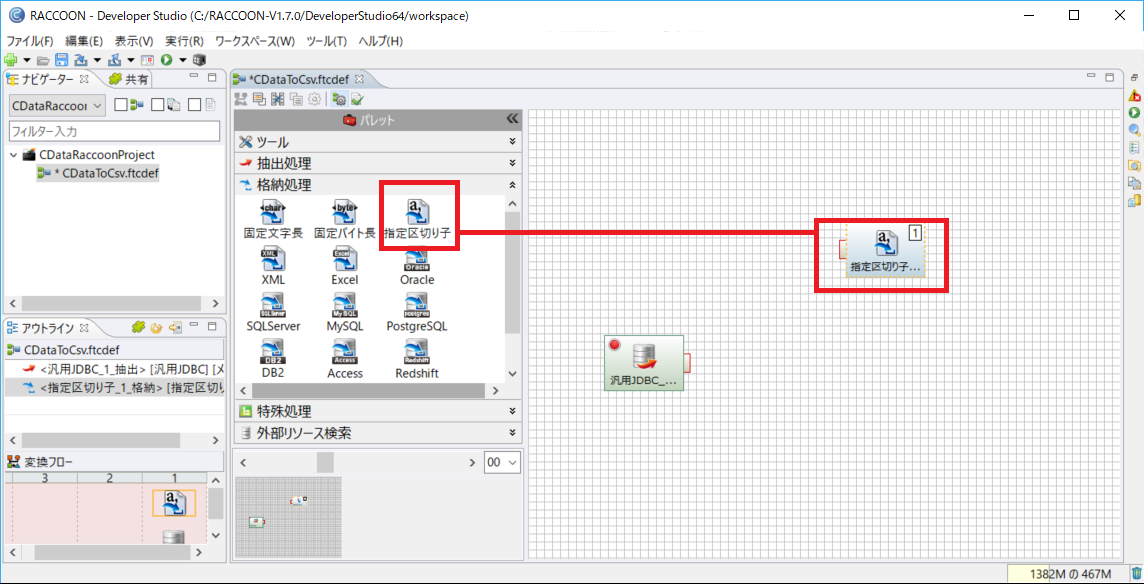
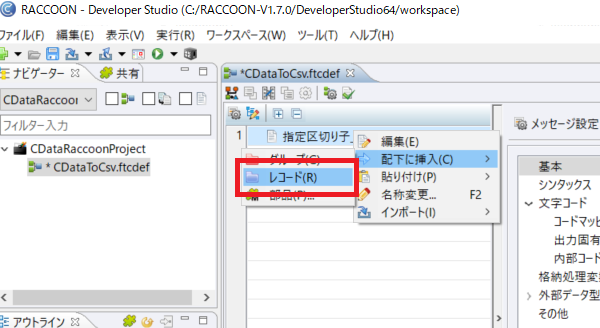
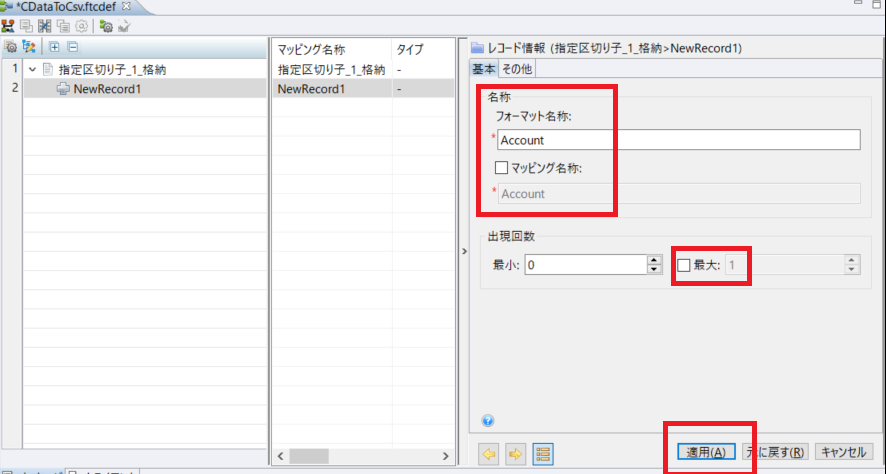
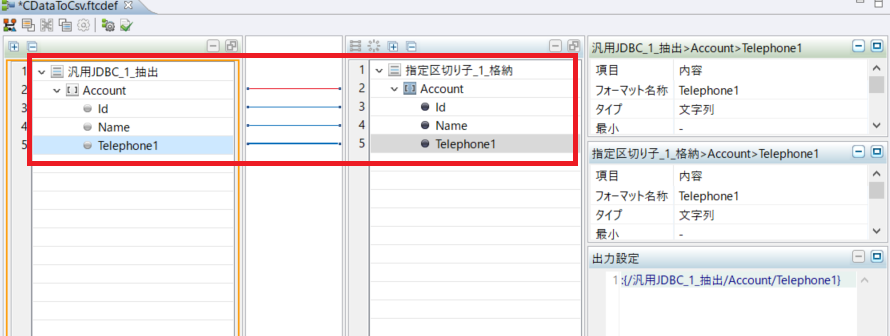
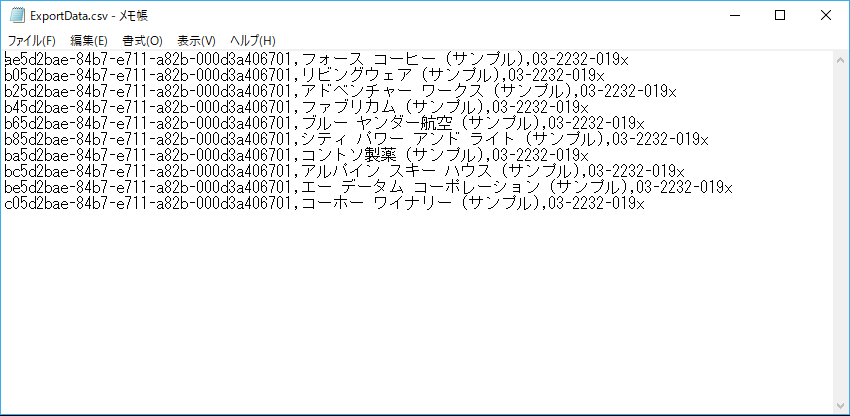
最後に抽出したデータの変換先として指定区切り子(CSV)の格納処理構成を行います。
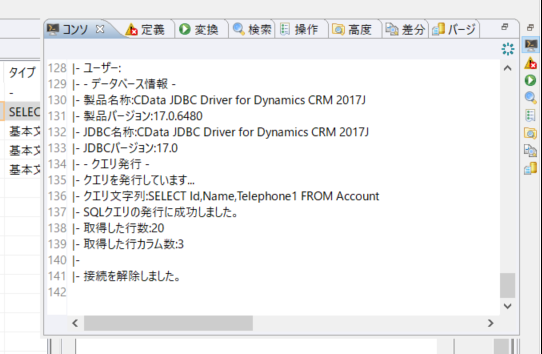
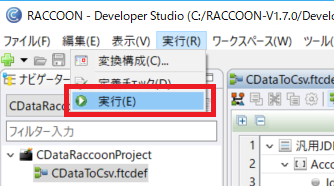
このようにApacheHive 内のデータをプログラムやWeb APIの処理を記述することなくRACCOON 上で処理することができるようになります。
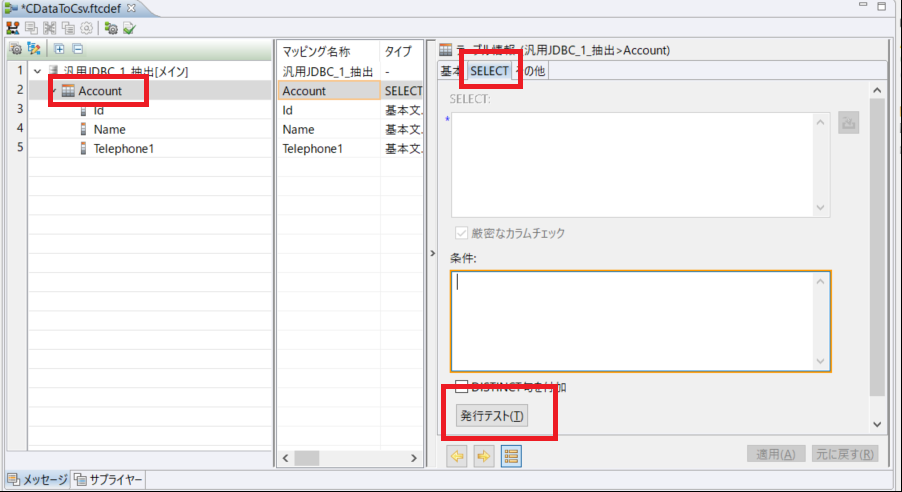
サポートされるSQL についての詳細は、ヘルプドキュメントの「サポートされるSQL」をご覧ください。テーブルに関する情報は「データモデル」をご覧ください。