ノーコードでクラウド上のデータとの連携を実現。
詳細はこちら →CData


こんにちは!プロダクトスペシャリストの宮本です。
CData Sync は、いろいろなシナリオのデータレプリケーション(同期)を行うことができるスタンドアロンのアプリケーションです。例えば、sandbox および本番インスタンスのデータをデータベースに同期することができます。Kafka データ をHeroku 上のPostgreSQL に同期することで、Salesforce の通常オブジェクトに加えて、Salesforce 外部オブジェクト(Salesforce Connect)としてKafka データへのアクセスが可能になります。
本レプリケーション例では、次が必要です:
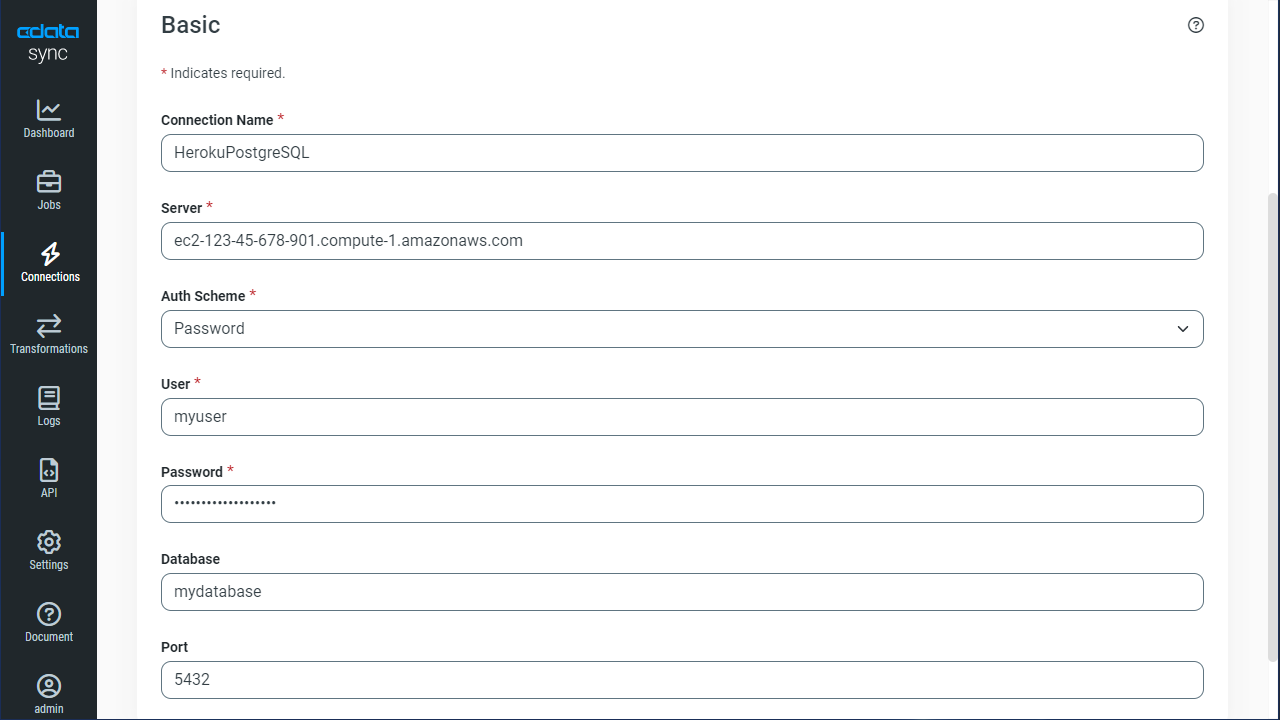
CData Sync を使って、Kafka データ をHeroku 上のPostgreSQL データベースにレプリケーションできます。本記事では、Heroku 上の既存のPostgreSQL を使用します。PostgreSQL データベースをレプリケーション先に指定するには、[接続]タブから進みます。
PostgreSQL への接続には、Port(デフォルトでは5432)、およびデータベース接続プロパティを設定し、サーバーに認証するuser およびpassword を設定します。データベースプロパティが指定されていない場合には、ユーザーのデフォルトデータベースに接続します。
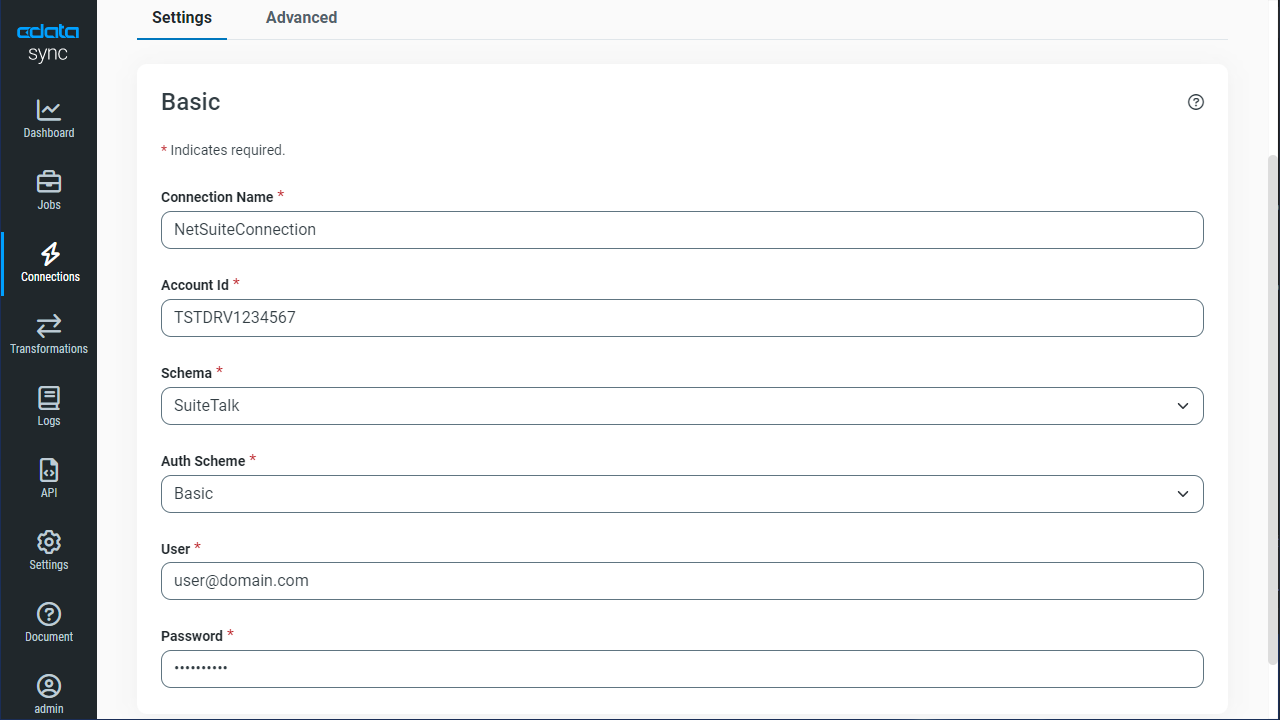
データソース側にKafka を設定します。[接続]タブをクリックします。
BootstrapServers およびTopic プロパティを設定して、Apache Kafka サーバーのアドレスと、対話するトピックを指定します。
サーバー証明書を信頼する必要がある場合があります。そのような場合は、必要に応じてTrustStorePath およびTrustStorePassword を指定してください。
Data Sync はレプリケーションをコントロールするSQL クエリを簡単なGUI 操作で設定できます。
レプリケーションジョブ設定には、[ジョブ]タブに進み、[ジョブを追加]ボタンをクリックします。
次にデータソースおよび同期先をそれぞれドロップダウンから選択します。
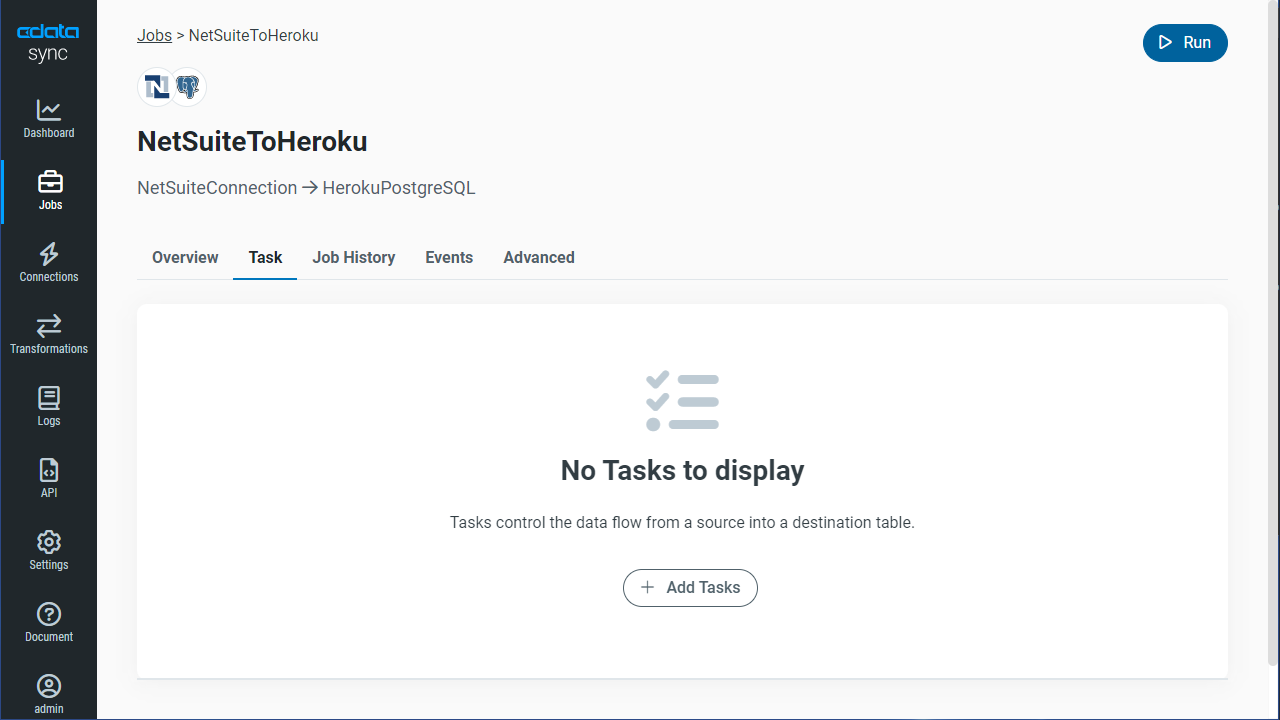
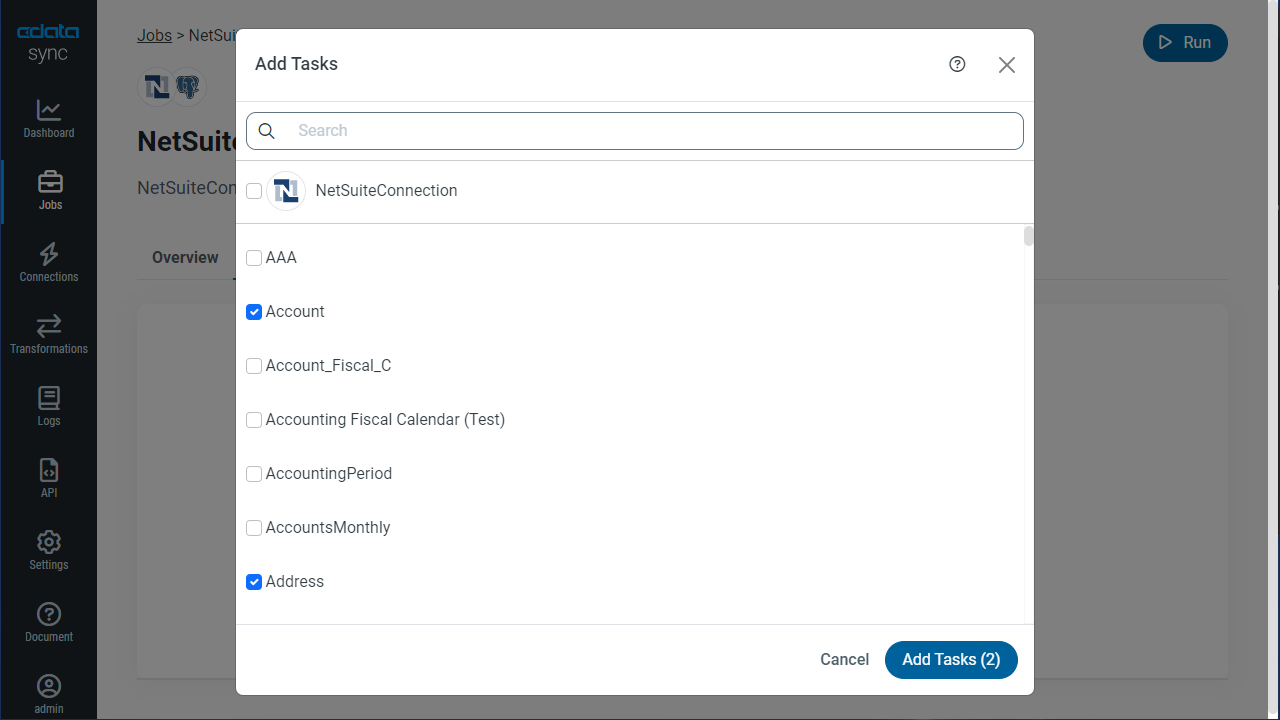
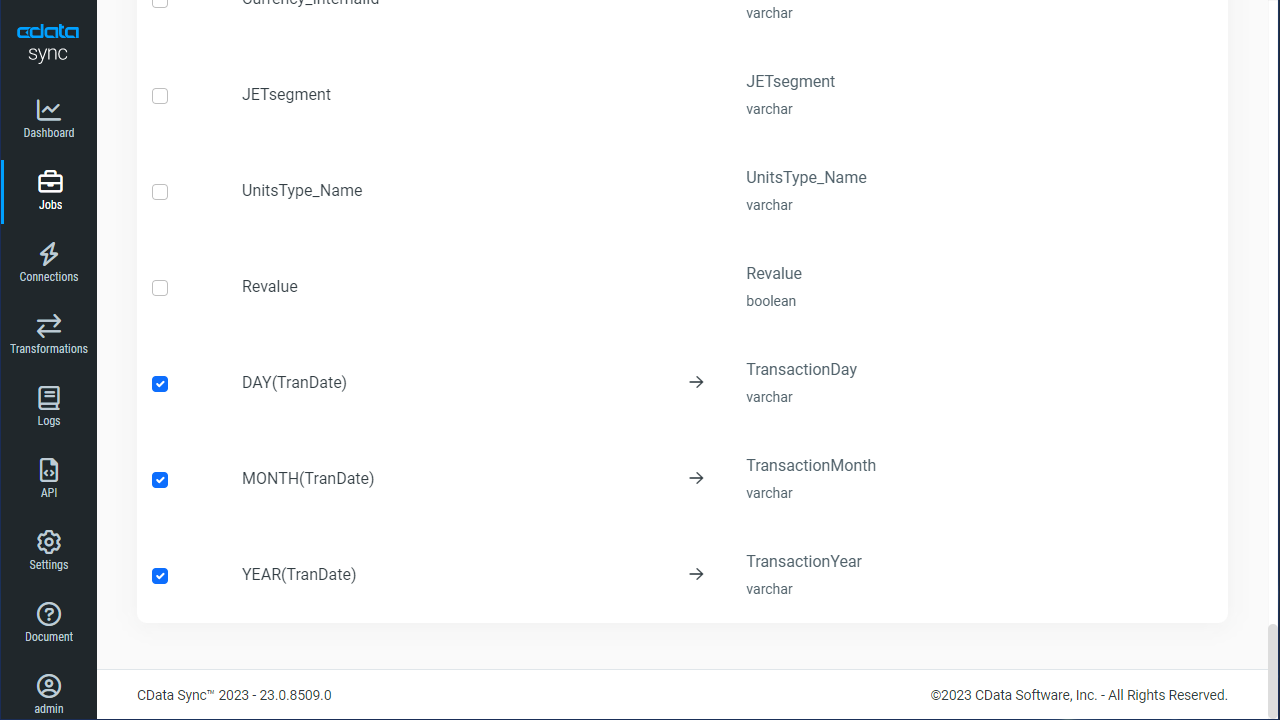
テーブル全体をレプリケーションするには、[テーブル]セクションで[テーブルを追加]をクリックします。表示されたテーブルリストからレプリケーションするテーブルをチェックします。
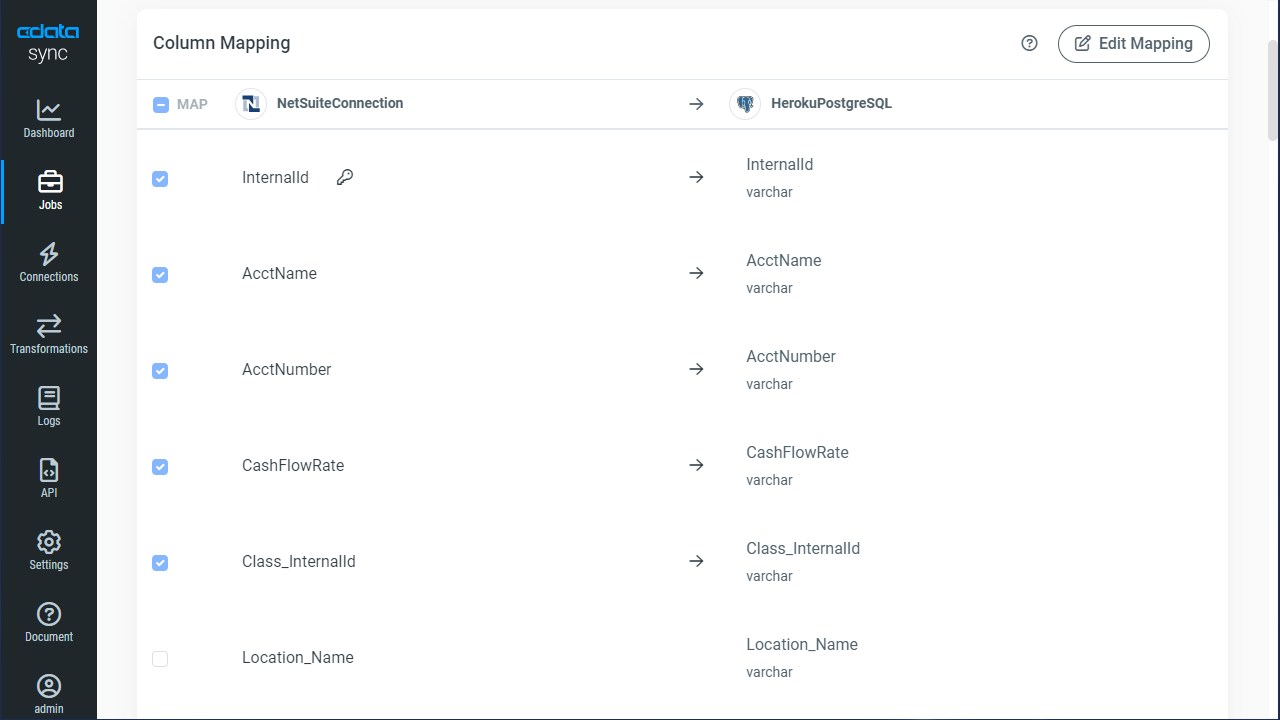
レプリケーションはテーブル全体ではなく、カスタマイズが可能です。[変更]機能を使えば、レプリケーションするカラムの指定、同期先でのカラム名を変更しての保存、ソースデータの各種加工が可能です。レプリケーションのカスタマイズには、ジョブの[変更]ボタンをクリックしてカスタマイズウィンドウを開いて操作を行います:
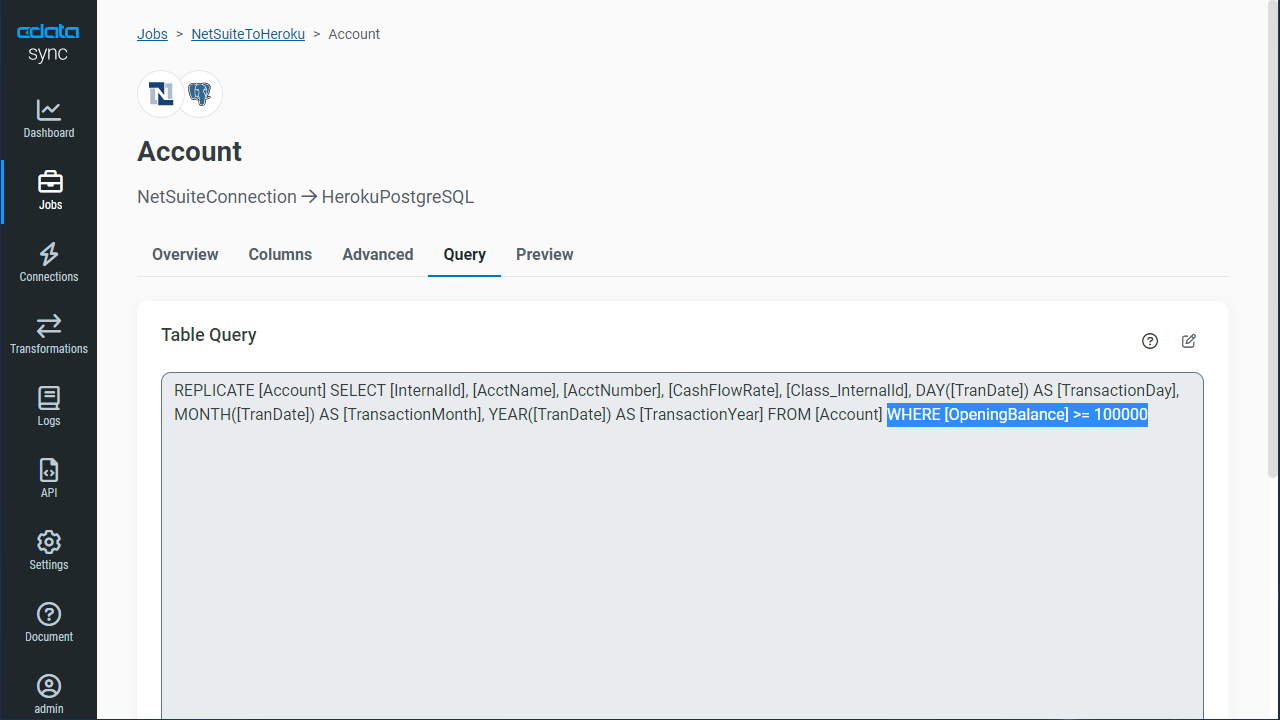
インターフェースを使って変更を行うと、レプリケーションのSQL クエリは以下のようなシンプルなものから:
REPLICATE [SampleTable_1]
次のような複雑なものになります:
REPLICATE [SampleTable_1] SELECT [Id], [Column1] FROM [SampleTable_1] WHERE [Column2] = 100
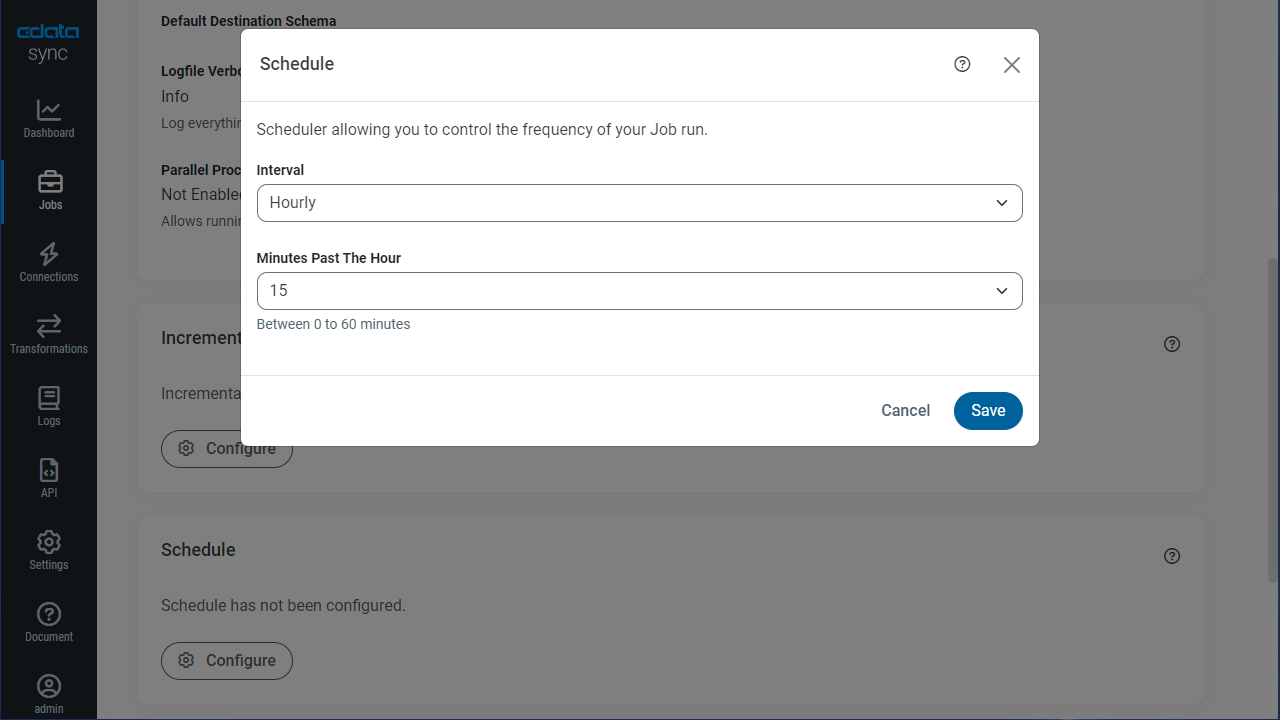
[スケジュール]セクションでは、レプリケーションジョブの自動起動スケジュール設定が可能です。反復同期間隔は、15分おきから毎月1回までの間で設定が可能です。
レプリケーションジョブを設定したら、[変更を保存]ボタンを押して保存します。複数のKafka データ のジョブを作成して、Salesforce の外部オブジェクトとして利用可能です。
Kafka データ がHeroku 上のPostgreSQL データベースとしてレプリケーションされたので、Heroku のOData インターフェースを設定し、Salesforce Connect から外部オブジェクトとしてデータ連携できるようにします。
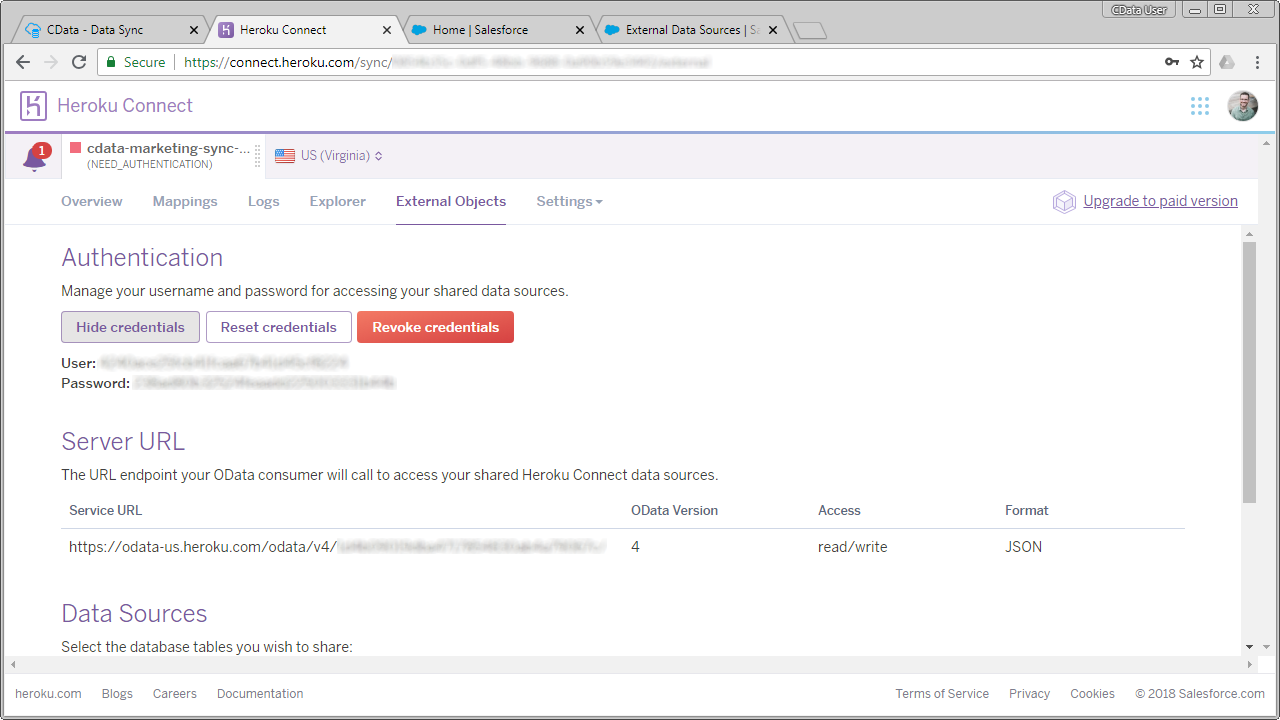
まずは、Heroku 上のPostgreSQL データベースに複製されたKafka データ への接続のために、データベースに対しHeroku External Object を設定します。
詳しくは、こちらのHeroku documentation を参照してください。
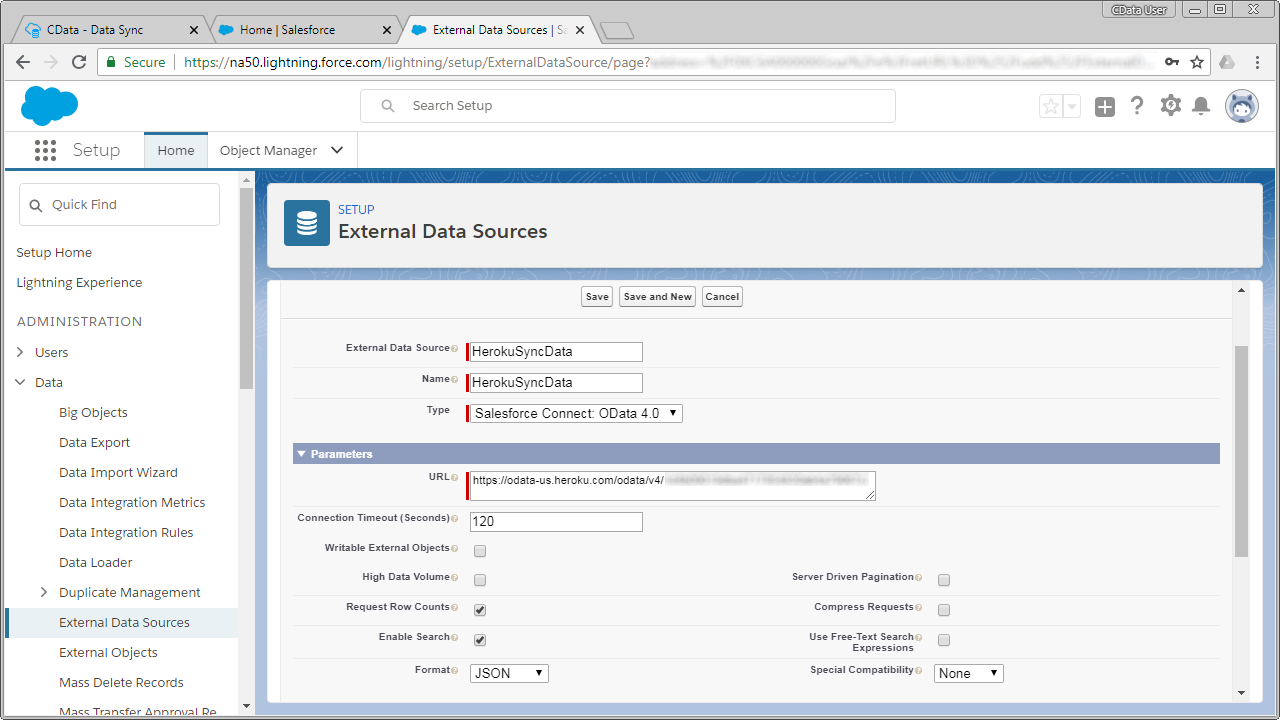
Heroku のOData サービスの設定が終わったら、Salesforce Connect を使って、複製されたKafka データ のデータに外部データソースとして連携します。
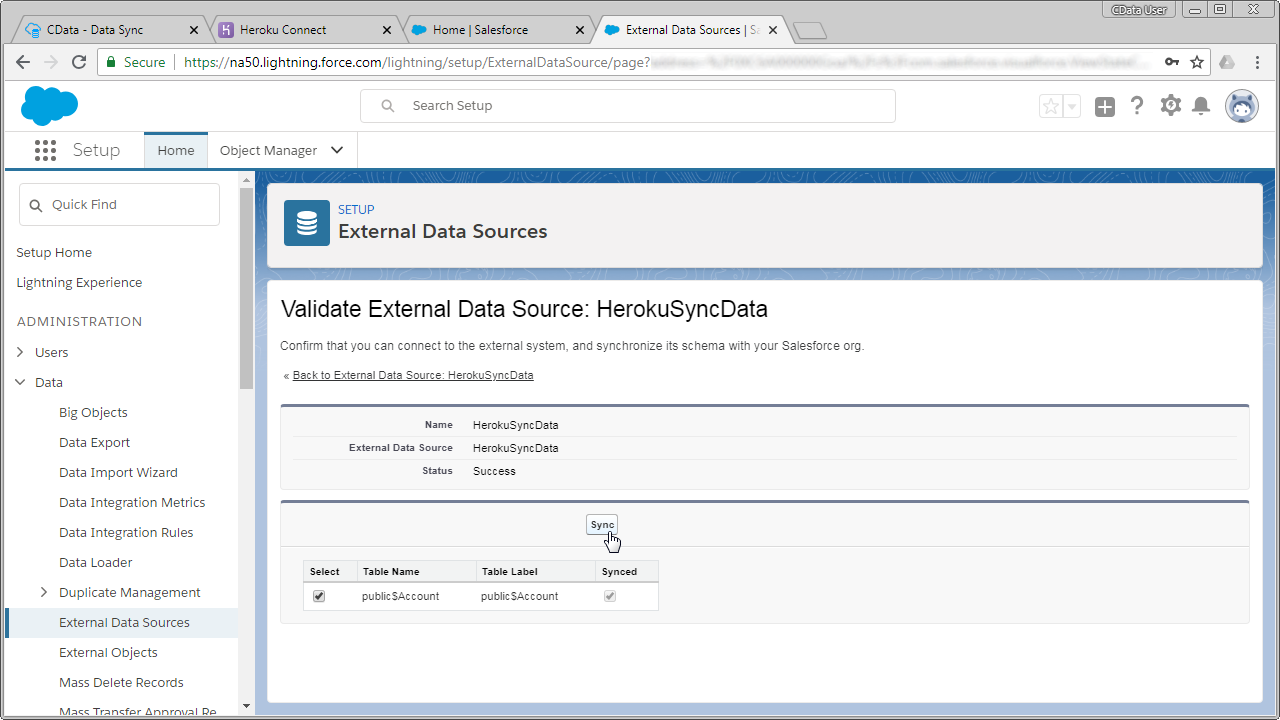
Salesforce の外部データソース登録が終わったら、次の方法でKafka 外部データソースに変更を反映させます。Kafka テーブルの定義とKafka 外部オブジェクトの定義を同期します。
これで、レプリケーションされたKafka エンティティに対して、Salesforce の通常オブジェクトと同じように外部オブジェクトとしてアクセスが可能になりました。
是非、CData Sync の30日の無償評価版 をダウンロードして、Salesforce との連携をお試しください!