ノーコードでクラウド上のデータとの連携を実現。
詳細はこちら →Monday.com Driver の30日間無償トライアルをダウンロード
30日間の無償トライアルへCData


こんにちは!リードエンジニアの杉本です。
Databricks https://databricks.com/はオープンソースの ビッグデータ処理基盤である Apache Spark をクラウドベースで提供しているサービスです。
通常Databricks では、Azure Blob Storage や Data Lakeに存在しているCSV、JSON、Parquetなどのバイナリベースの構造データ、ないしSQL ServerやCosmos DBといったRDB・NoSQLサービスからデータを取り込んで、分析するというアプローチが多いかと思います。
しかしながら、今や分析対象となるデータソースはそういったバイナリデータやRDB・NoSQLのdataにとどまらず、SalesforceやDynamics 365といったクラウドサービス上にも数多く存在しています。そこで CData JDBC Driverを活用することにより、Databricks から シームレスにクラウドサービスのデータソースをロード、分析できるようになります。
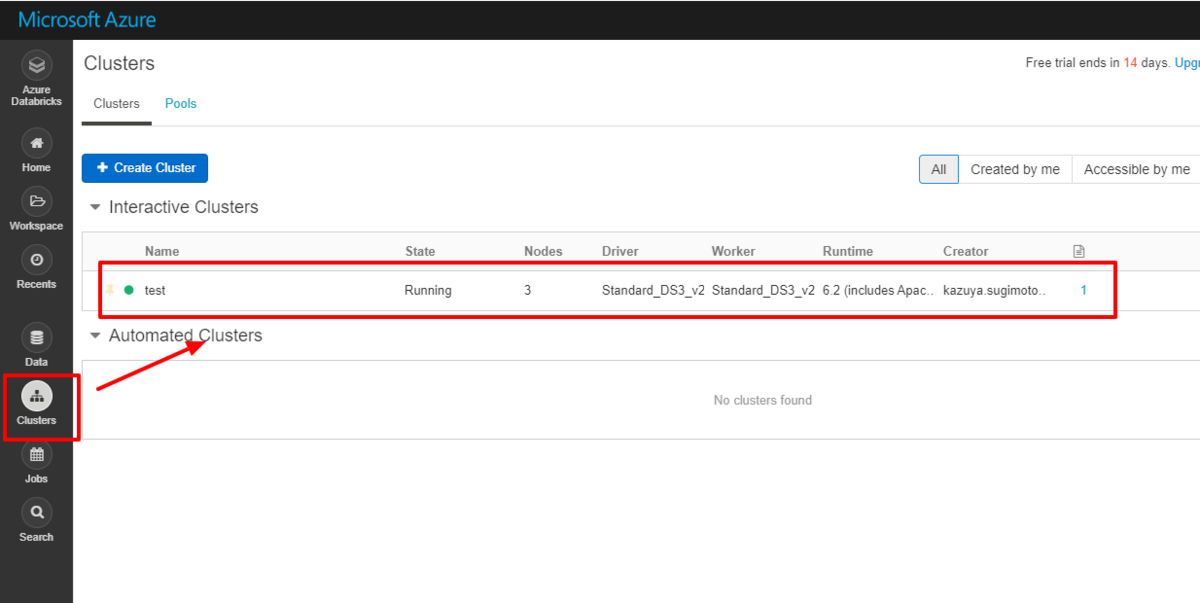
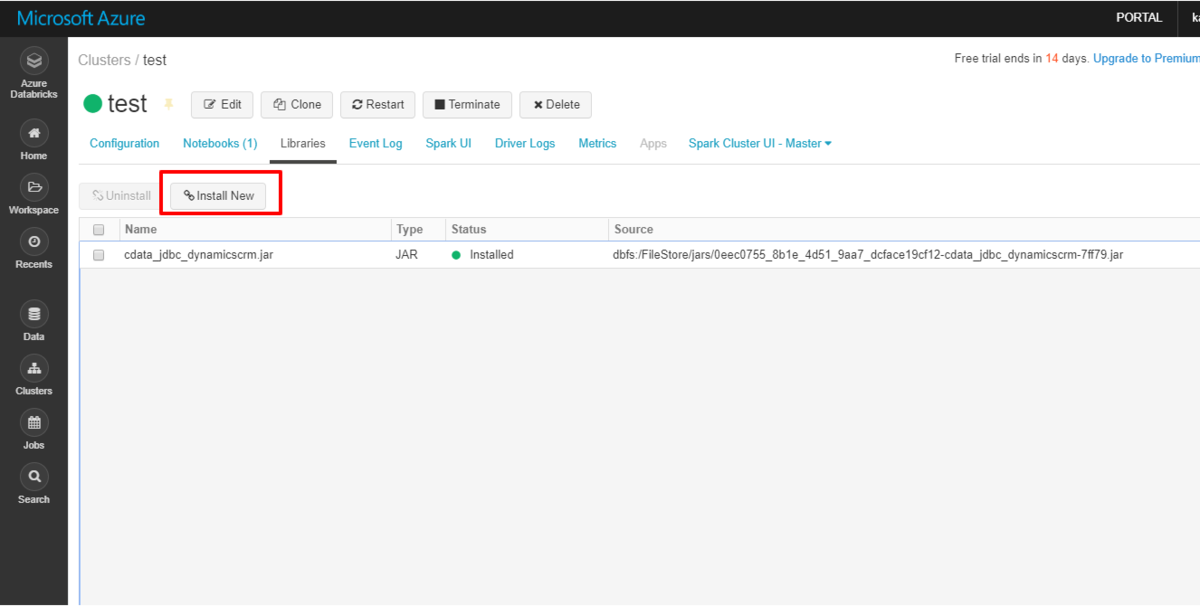
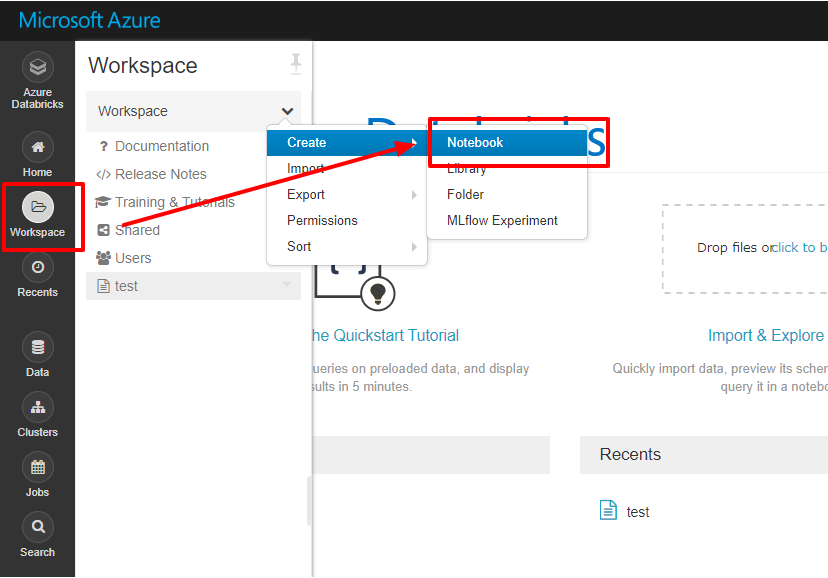
この記事では、クラウドサービスのビッグデータ処理サービスである Databricks で CData JDBC Driverを利用してMonday.com データを扱う方法を紹介します。
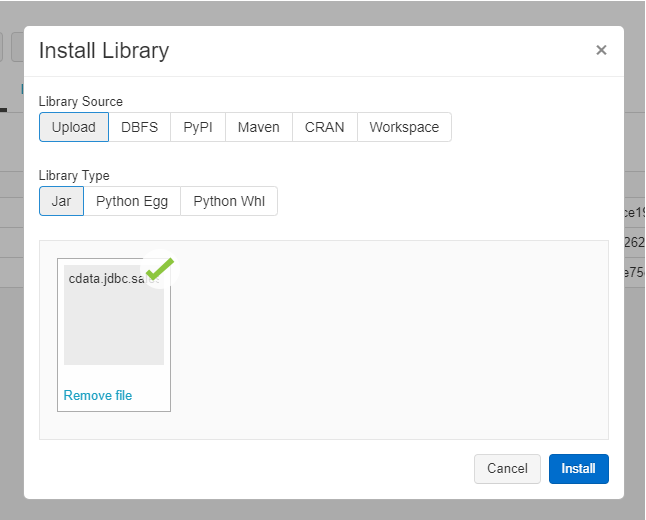
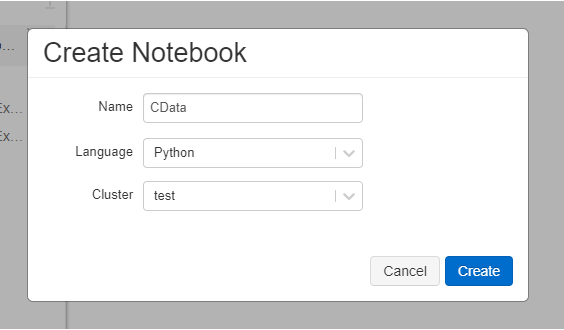
これでドライバーの配置などの準備は完了です。
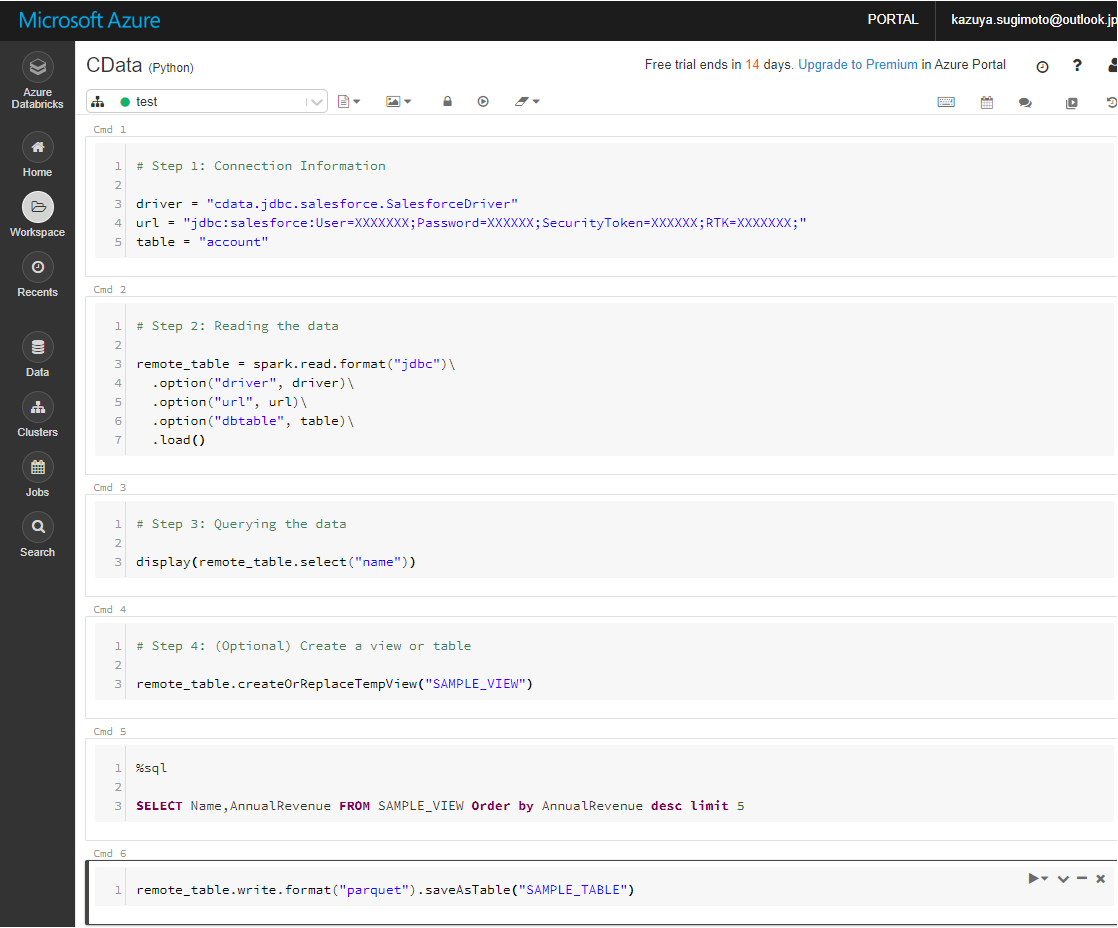
# Step 1: Connection Information
driver = "cdata.jdbc.monday.MondayDriver"
url = "jdbc:monday:APIToken=eyJhbGciOiJIUzI1NiJ9.yJ0aWQiOjE0MTc4NzIxMiwidWlkIjoyNzI3ODM3OSwiaWFkIjoiMjAyMi0wMS0yMFQxMDo0NjoxMy45NDFaIiwicGV;"
table = "Invoices"
# Step 2: Reading the data
remote_table = spark.read.format("jdbc")\
.option("driver", driver)\
.option("url", url)\
.option("dbtable", table)\
.load()
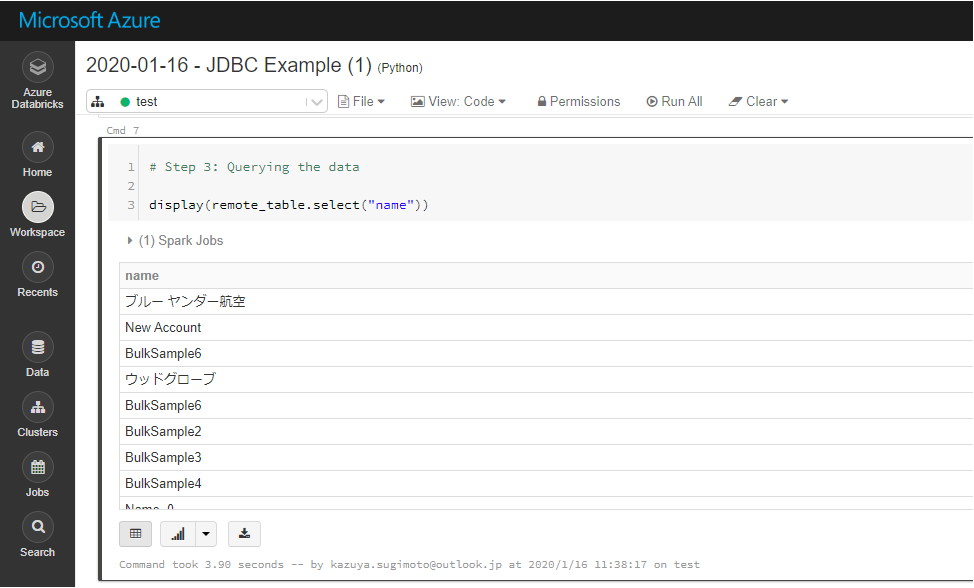
# Step 3: Querying the data
display(remote_table.select("name"))
# Step 4: (Optional) Create a view or table
remote_table.createOrReplaceTempView("SAMPLE_VIEW")
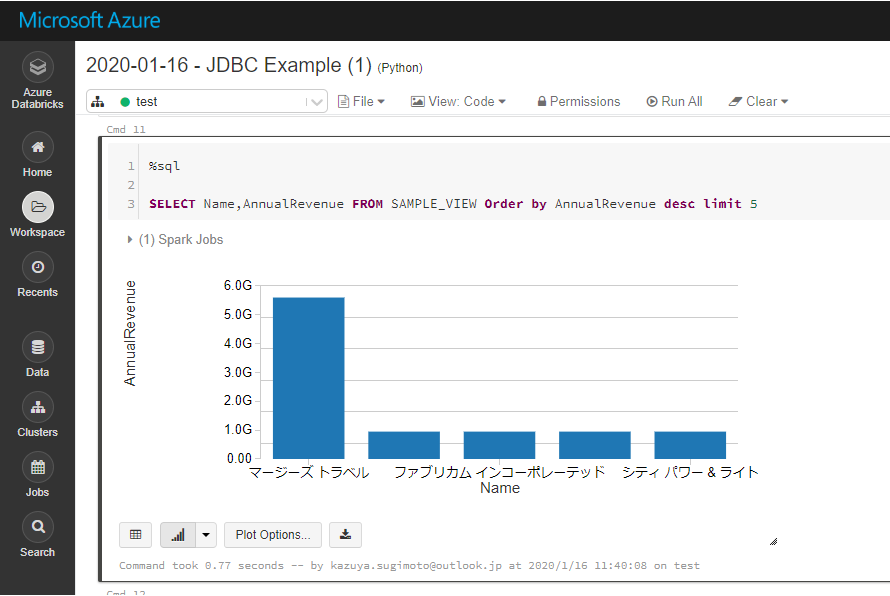
%sql
SELECT Name,AnnualRevenue FROM SAMPLE_VIEW Order by AnnualRevenue desc limit 5
なお、データフレームは対象のNotebook内だけのデータなので、他のユーザーと一緒に利用する場合はテーブルとして保存しておきましょう。
remote_table.write.format("parquet").saveAsTable("SAMPLE_TABLE")
このようにCData JDBC ドライバをアップロードすることで、簡単にDatabricks でMonday.com データ データをノーコードで連携し、分析に使うことが可能です。
是非、CData JDBC Driver for Monday 30日の無償評価版 をダウンロードして、お試しください。