ノーコードでクラウド上のデータとの連携を実現。
詳細はこちら →Amazon Redshift Driver の30日間無償トライアルをダウンロード
30日間の無償トライアルへCData


こんにちは!ウェブ担当の加藤です。マーケ関連のデータ分析や整備もやっています。
CData JDBC Driver for Redshift は、JDBC 標準に準拠し、BI ツールからIDE まで幅広いアプリケーションでRedshift データへの接続を提供します。この記事では、DbVisualizer からRedshift データに接続する方法、およびtable エディタを使ってRedshift を編集、および保存する方法を説明します。
CData JDBC ドライバは、以下の特徴を持ったリアルタイムデータ接続ツールです。
CData JDBC ドライバでは、1.データソースとしてRedshift の接続を設定、2.DBeaver 側でJDBC Driver との接続を設定、という2つのステップだけでデータソースに接続できます。以下に具体的な設定手順を説明します。
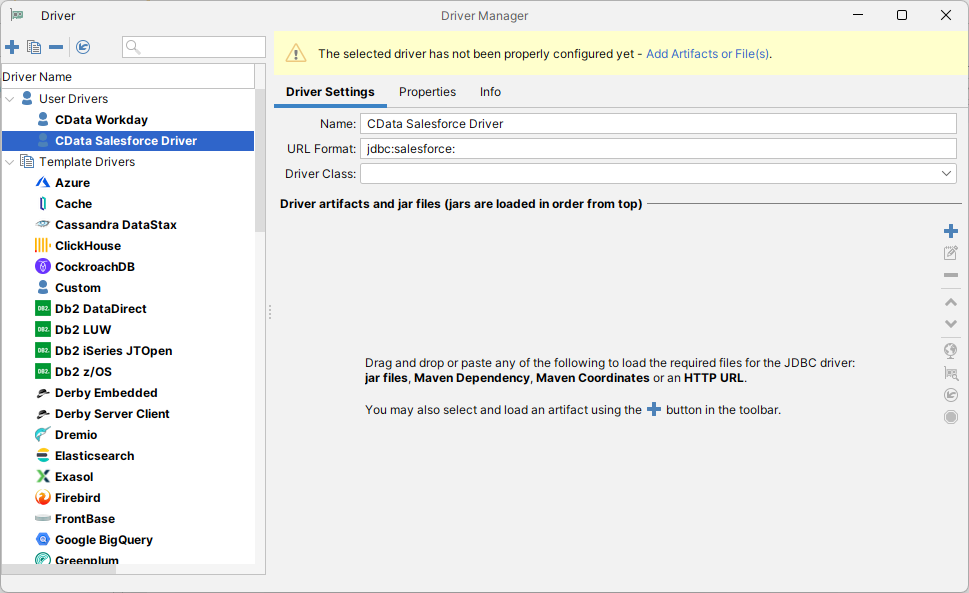
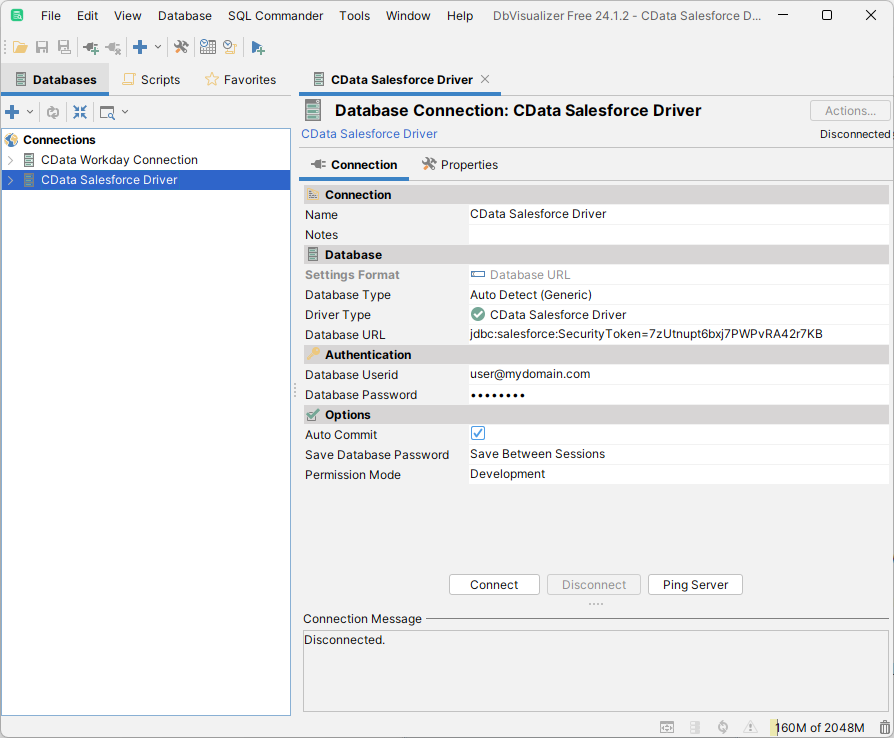
下記の手順に従い、Driver Manager を使ってDbVisualizer ツールからRedshift データに接続します。
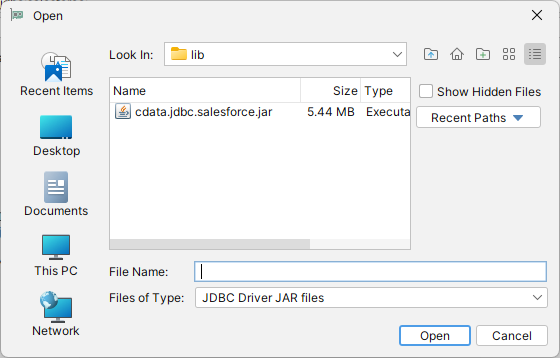
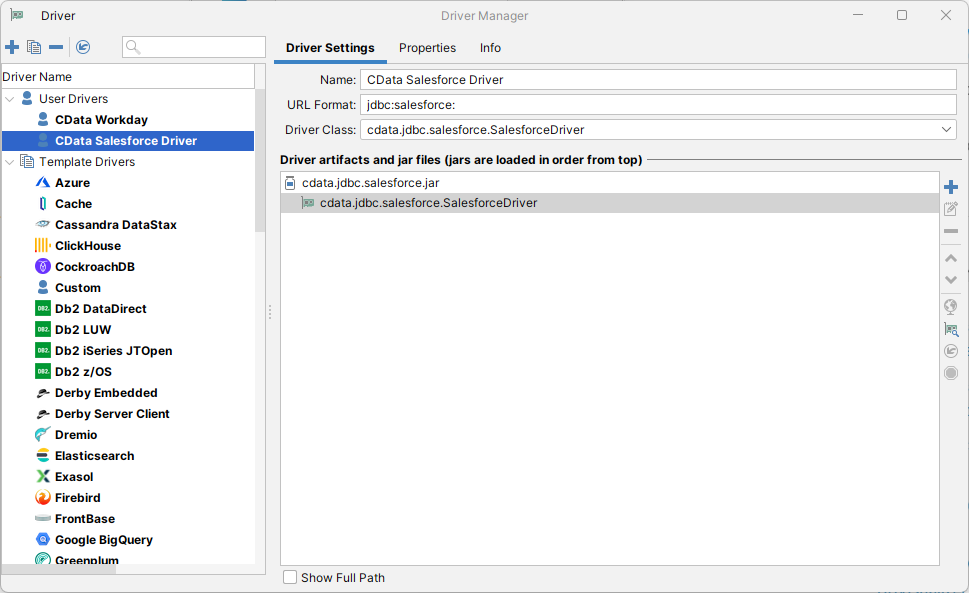
「Driver Manager」を終了し、下記の手順に従ってJDBC URL に接続プロパティを入力します。
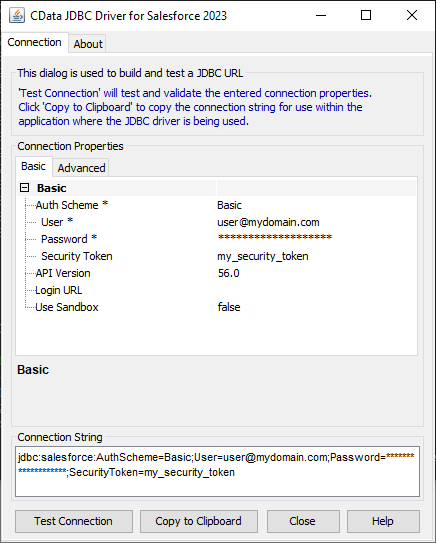
「Connection」セクションで以下のオプションを設定します。
Database URL:完全なJDBC URL を入力します。JDBC URL 構文は、jdbc:redshift: に続けてセミコロン区切りでname-value ペアの接続プロパティを入力します。
Redshift への接続には次を設定します:
Server およびPort の値はAWS の管理コンソールで取得可能です:
JDBC URL の作成の補助として、Redshift JDBC Driver に組み込まれている接続文字列デザイナーが使用できます。JAR ファイルをダブルクリックするか、コマンドラインからjar ファイルを実行します。
java -jar cdata.jdbc.redshift.jar
接続プロパティを入力し、接続文字列をクリップボードにコピーします。
JDBC URL を構成する際に、Max Rows 接続プロパティを設定することもできます。この設定は返される行数を制限するため、レポートやビジュアライゼーションを作成する際のパフォーマンスが向上します。
一般的な接続文字列は次のとおりです。
jdbc:redshift:User=admin;Password=admin;Database=dev;Server=examplecluster.my.us-west-2.redshift.amazonaws.com;Port=5439;
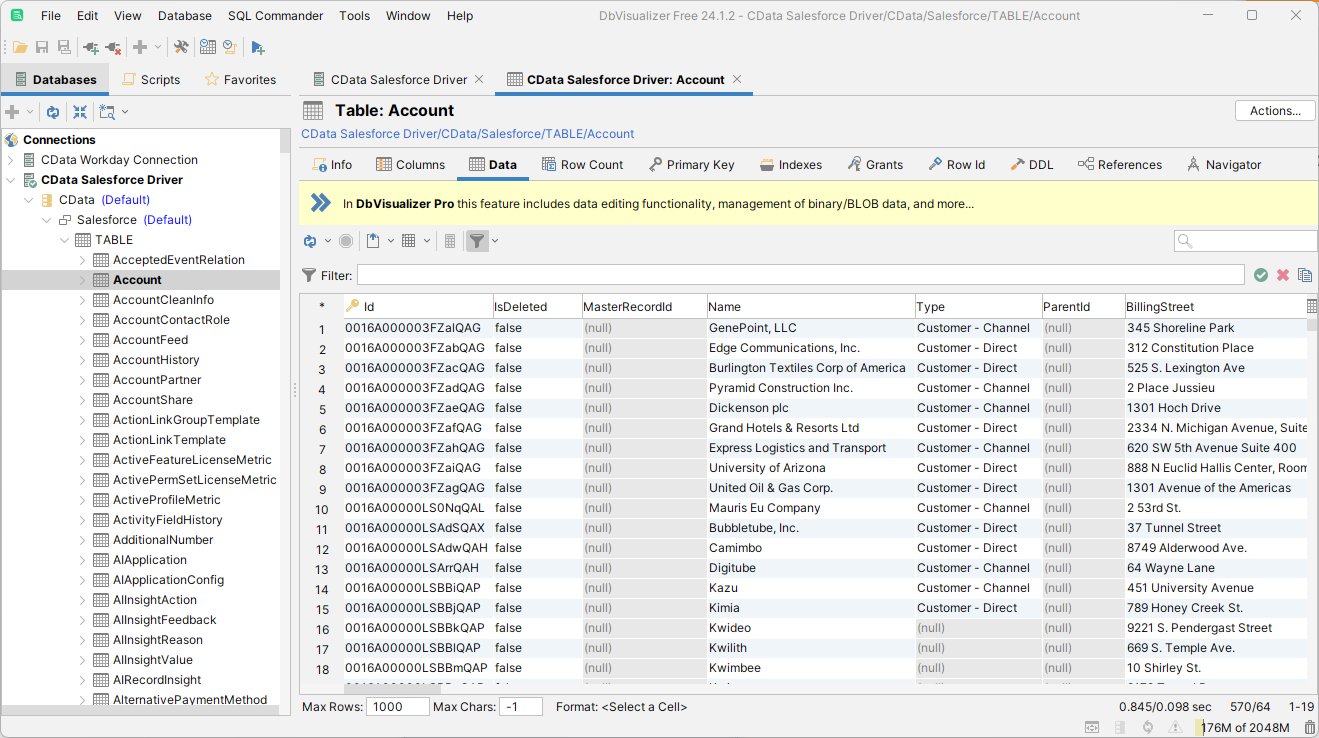
Redshift JDBC Driver が表示するテーブルをブラウズするには、テーブルを右クリックして「Open In New Tab」をクリックします。
SQL クエリの実行には、SQL Commander ツールを使用します。「SQL Commander」->「New SQL Commander」をクリックします。利用可能なメニューから「Database Connection」、「Database」、「Schema」を選択します。
サポートされるSQL についての詳細は、ヘルプドキュメントの「サポートされるSQL」をご覧ください。テーブルに関する情報は「データモデル」をご覧ください。