ノーコードでクラウド上のデータとの連携を実現。
詳細はこちら →Amazon Redshift Driver の30日間無償トライアルをダウンロード
30日間の無償トライアルへCData


こんにちは!ウェブ担当の加藤です。マーケ関連のデータ分析や整備もやっています。
CData JDBC Driver for Redshift を使用すると、Redshift がリレーショナルデータベースであるかのようにダッシュボードやレポートからリアルタイムデータにアクセスでき、使い慣れたSQL クエリを使用してRedshift] をクエリできます。ここでは、JDBC データソースとしてRedshift に連携し、JReport Designer でRedshift のレポートを作成する方法を説明します。
... set ADDCLASSPATH=%JAVAHOME%\lib\tools.jar;C:\Program Files\CData\CData JDBC Driver for Redshift 2016\lib\cdata.jdbc.redshift.jar; ...
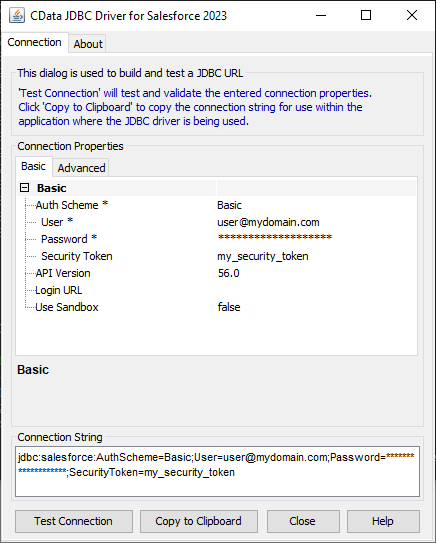
cdata.jdbc.redshift.RedshiftDriverRedshift への接続には次を設定します:
Server およびPort の値はAWS の管理コンソールで取得可能です:
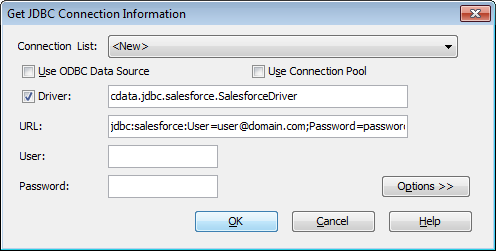
JDBC URL の構成については、Redshift JDBC Driver に組み込まれている接続文字列デザイナーを使用してください。JAR ファイルのダブルクリック、またはコマンドラインからJAR ファイルを実行します。
java -jar cdata.jdbc.redshift.jar
接続プロパティを入力し、接続文字列をクリップボードにコピーします。
JDBC URL を構成する際、Max Rows 接続プロパティを設定することもできます。これによって戻される行数を制限するため、可視化・レポートのデザイン設計時のパフォーマンスを向上させるのに役立ちます。
以下は一般的なJDBC URLです。
jdbc:redshift:User=admin;Password=admin;Database=dev;Server=examplecluster.my.us-west-2.redshift.amazonaws.com;Port=5439;
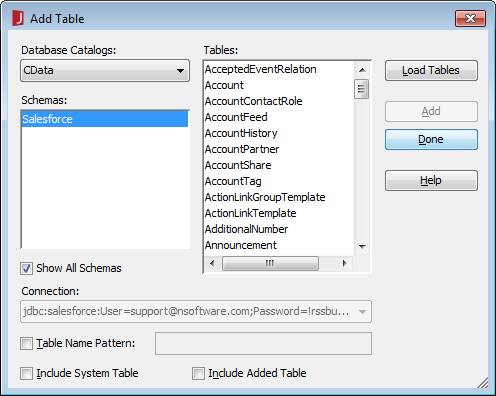
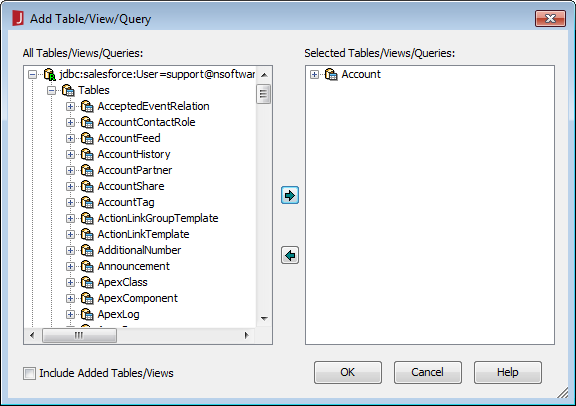
[Add Table]ダイアログで、レポート(またはこのデータソースを使用する予定のレポート)に含めるテーブルを選択し、[Add]をクリックします。
ダイアログがテーブルのロードを完了したら、[Done]をクリックします。
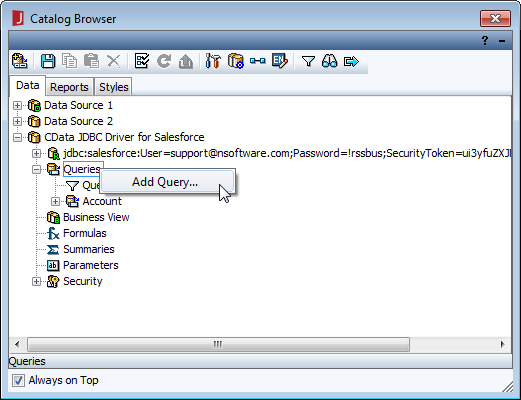
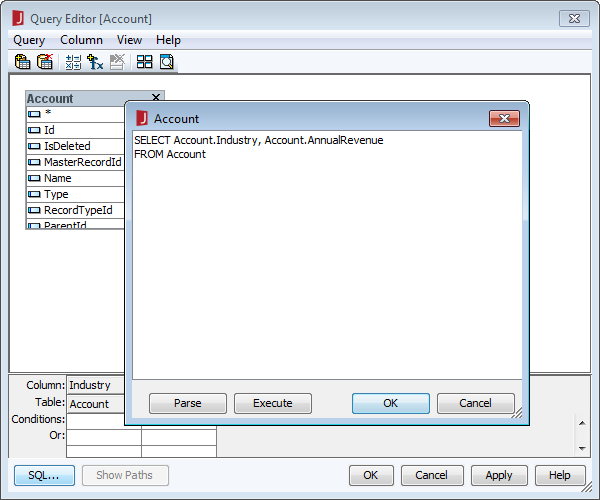
SELECT ShipName, ShipCity FROM Orders
クエリが作成されたら、[OK]をクリックして[Query Editor]ダイアログを閉じます。この時点で、Redshift を新規または既存のレポートに追加する準備が整いました。
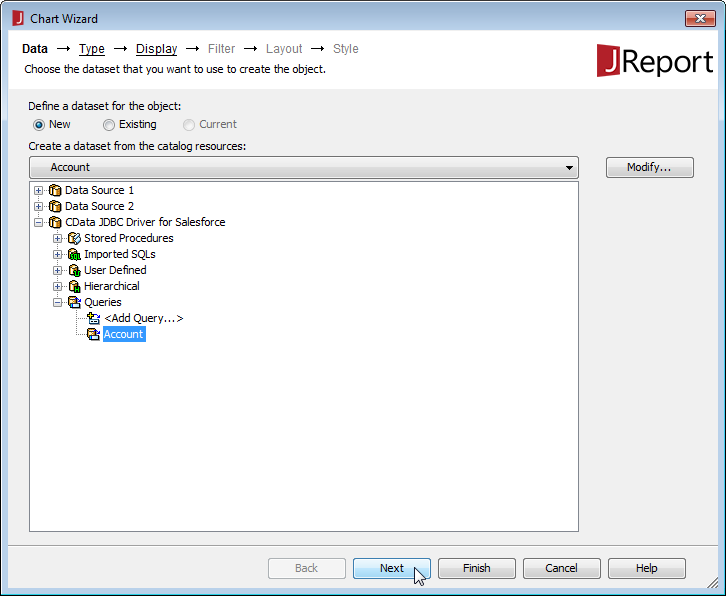
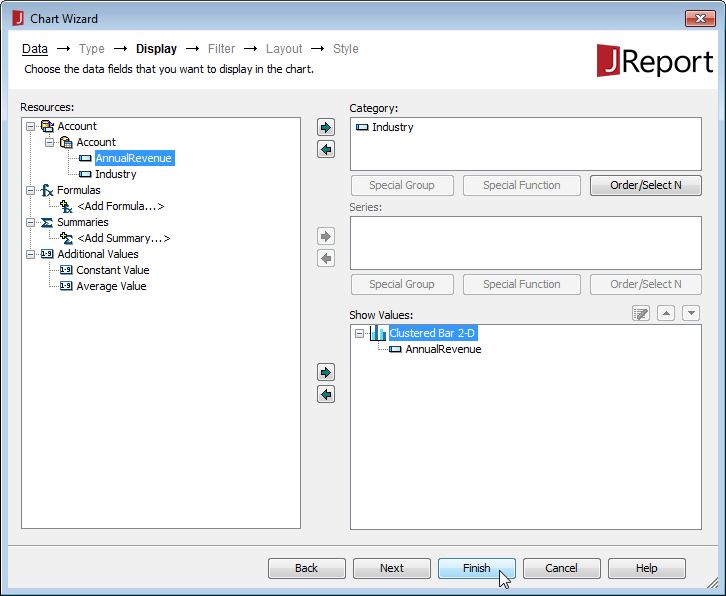
NOTE: クエリが作成されると、クエリに基づいて[Business View]を作成できます。[Business View]を使用すると、クエリに基づいてWeb レポートまたはライブラリコンポーネントを作成できます。これについてのより詳しい情報は、JReport のチュートリアルを参照してください。
Redshift を使用してレポートを作成することができるようになりました。