ノーコードでクラウド上のデータとの連携を実現。
詳細はこちら →Amazon Redshift Driver の30日間無償トライアルをダウンロード
30日間の無償トライアルへこんにちは!ウェブ担当の加藤です。マーケ関連のデータ分析や整備もやっています。
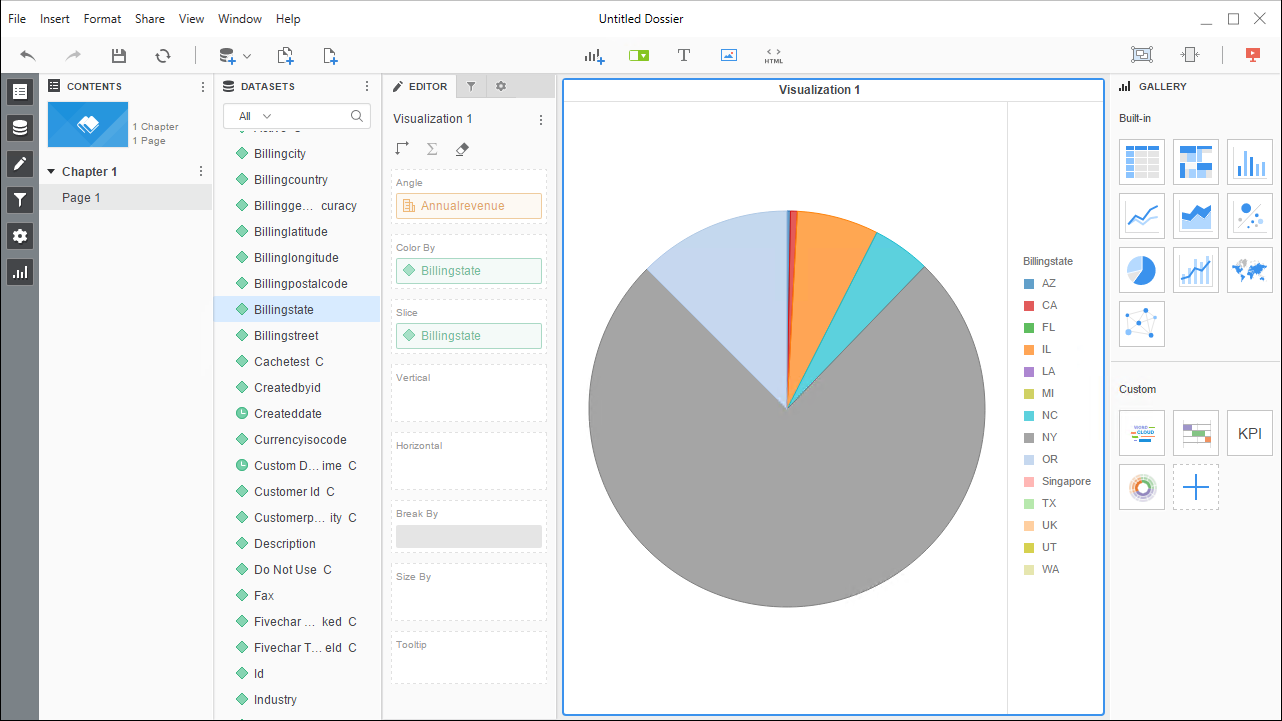
MicroStrategy は、データ主導のイノベーションを可能にする、モビリティプラットフォームです。MicroStrategy をCData JDBC Driver for Redshift とペアリングすると、MicroStrategy からリアルタイムRedshift へのデータベースのようなアクセスが得られ、レポート機能と分析機能が拡張されます。この記事では、MicroStrategy Desktop にデータソースとしてRedshift を追加し、Redshift の簡単なヴィジュアライゼーションを作成する方法について説明します。
CData JDBC ドライバーは、ドライバーに組み込まれた最適化されたデータ処理により、MicroStrategy でリアルタイムRedshift と対話するための比類のないパフォーマンスを提供します。MicroStrategy からRedshift に複雑なSQL クエリを発行すると、ドライバーはフィルタや集計などのサポートされているSQL 操作をRedshift に直接プッシュし、組み込みSQL エンジンを利用して、サポートされていない操作(一般的にはSQL 関数とJOIN 操作) をクライアント側で処理します。組み込みの動的メタデータクエリを使用すると、ネイティブのMicroStrategy データタイプを使用してRedshift を視覚化および分析できます。
MicroStrategy エンタープライズ製品のRedshift に接続するだけでなく、MicroStrategy Desktop のRedshift に接続することもできます。以下のステップに従って、JDBC を使用してRedshift をデータセットとして追加し、Redshift の視覚化とレポートを作成します。
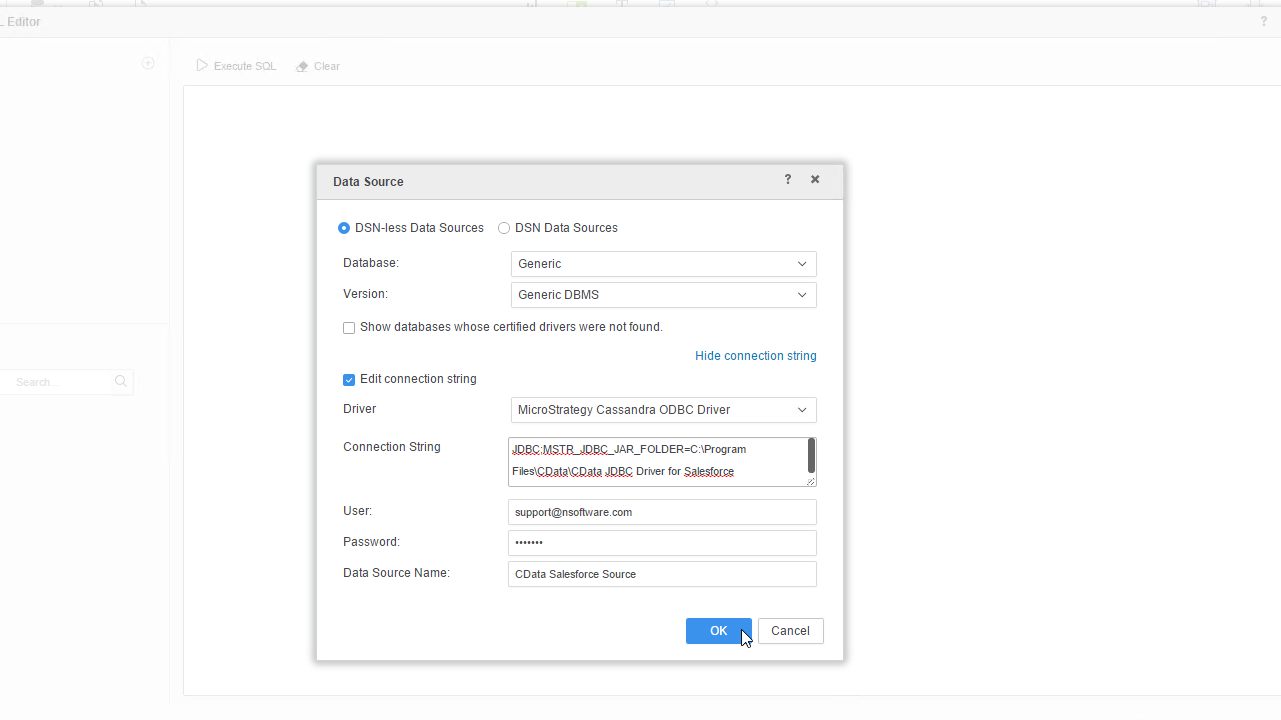
Redshift への接続には次を設定します:
Server およびPort の値はAWS の管理コンソールで取得可能です:
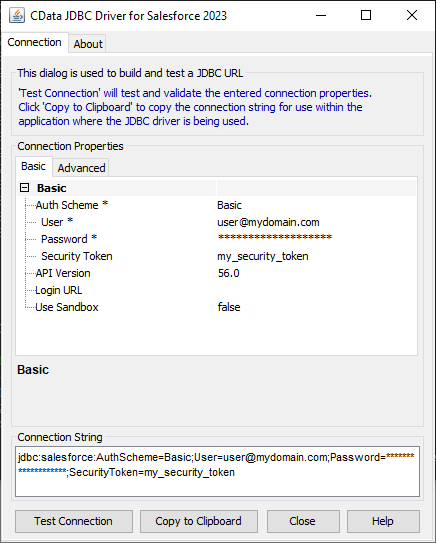
JDBC URL の構成については、Redshift JDBC Driver に組み込まれている接続文字列デザイナを使用してください。JAR ファイルのダブルクリック、またはコマンドラインからJAR ファイルを実行します。
java -jar cdata.jdbc.redshift.jar
接続プロパティを入力し、接続文字列をクリップボードにコピーします。
JDBC URL を構成する際に、Max Rows プロパティを定めることも可能です。これによって戻される行数を制限するため、可視化・レポートのデザイン設計時のパフォーマンスを向上させるのに役立ちます。
以下は一般的な接続文字列です。
JDBC;MSTR_JDBC_JAR_FOLDER=PATH\TO\JAR\;DRIVER=cdata.jdbc.redshift.RedshiftDriver;URL={jdbc:redshift:User=admin;Password=admin;Database=dev;Server=examplecluster.my.us-west-2.redshift.amazonaws.com;Port=5439;};
MicroStrategy Desktop のCData JDBC Driver for Redshift を使用すると、Redshift で安定したビジュアライゼーションとレポートを簡単に作成できます。その他の例については、MicroStrategy Developer のRedshift に接続 やMicroStrategy Web のRedshift に接続 などの記事をお読みください。






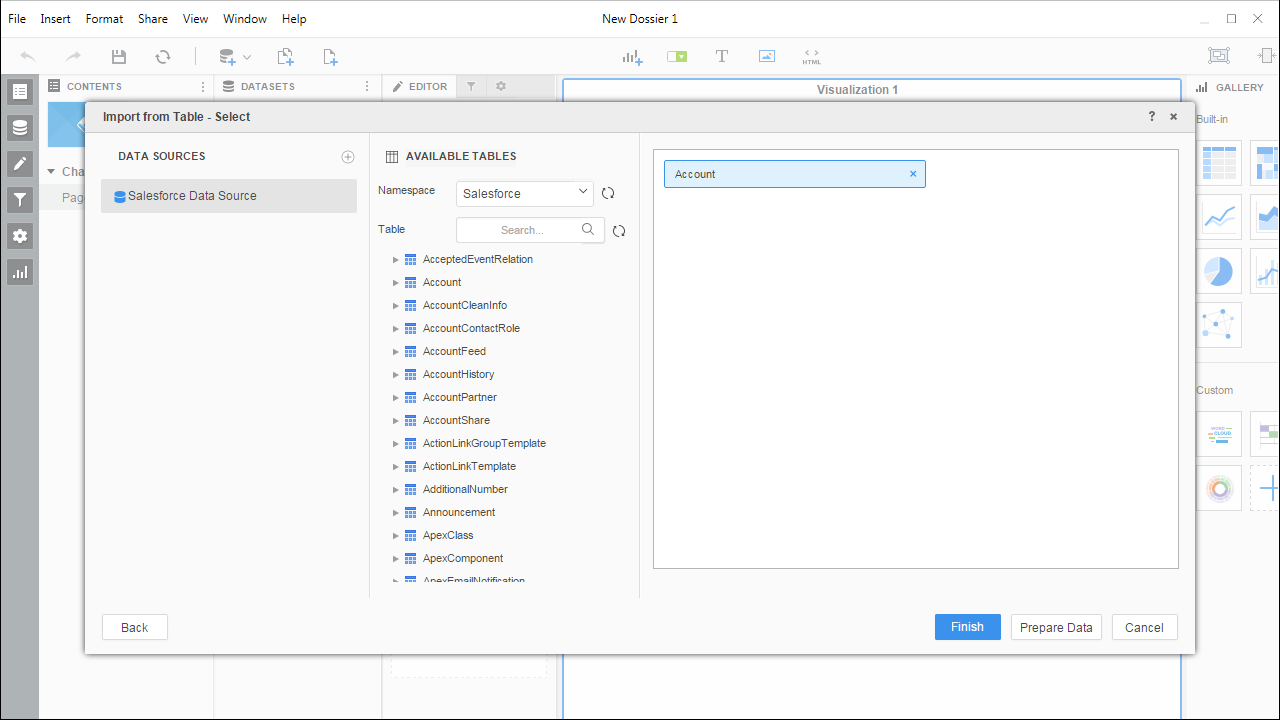 Noteライブ接続を作成するため、テーブル全体をインポートしてMicroStrategy 製品に固有のフィルタリングおよび集計機能を利用できます。
Noteライブ接続を作成するため、テーブル全体をインポートしてMicroStrategy 製品に固有のフィルタリングおよび集計機能を利用できます。