ノーコードでクラウド上のデータとの連携を実現。
詳細はこちら →Amazon Redshift Driver の30日間無償トライアルをダウンロード
30日間の無償トライアルへCData


こんにちは!ウェブ担当の加藤です。マーケ関連のデータ分析や整備もやっています。
Oracle Data Integrator(ODI)はOracle エコシステムのハイパフォーマンスなデータ統合プラットフォームです。CData JDBC Driver for Redshift を使えば、OCI をはじめとするETL ツールからRedshift データにJDBC 経由で簡単に読み取りと書き込みを実現できます。リアルタイムRedshift データをデータウェアハウス、BI・帳票ツール、CRM、基幹システムなどに統合すれば、データ活用もぐっと楽に。
CData のコネクタを使えば、Redshift API にリアルタイムで直接接続して、ODI 上で通常のデータベースと同じようにRedshift データを操作できます。Redshift エンティティのデータモデルを構築、マッピングを作成し、データの読み込み方法を選択するだけの簡単なステップでRedshift データのETL が実現できます。
ドライバーをインストールするには、インストールフォルダにあるドライバーのJAR ファイルと.lic ファイルをODI の適切なディレクトリにコピーします。
ODI を再起動してインストールを完了します。
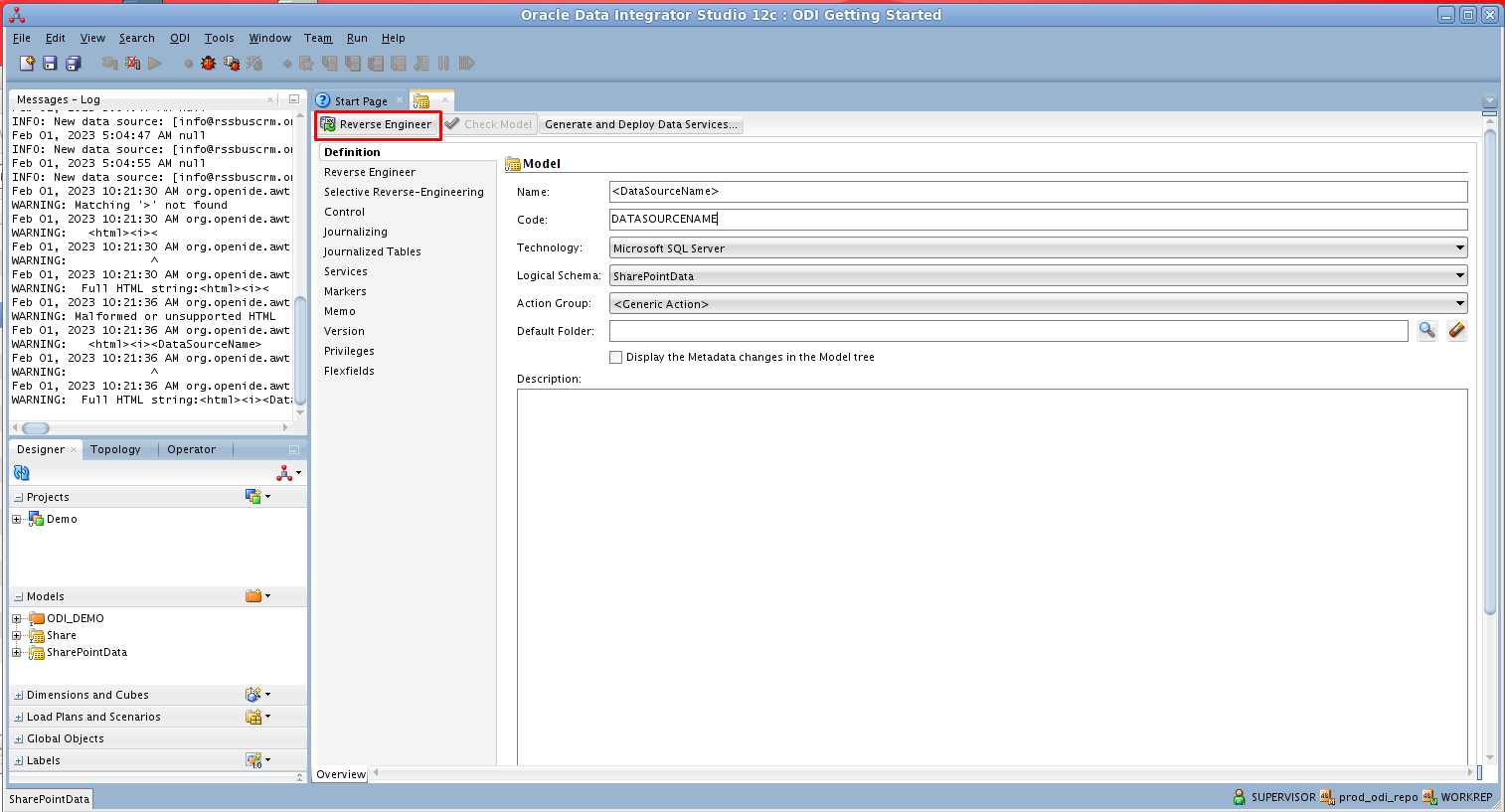
ODI の機能を使ってモデルをリバースエンジニアリングすることで、ドライバー側で取得したRedshift データのリレーショナルビューに関するメタデータが取得できます。リバースエンジニアリング後、リアルタイムRedshift データにクエリを実行してRedshift テーブルのマッピングを作成できます。
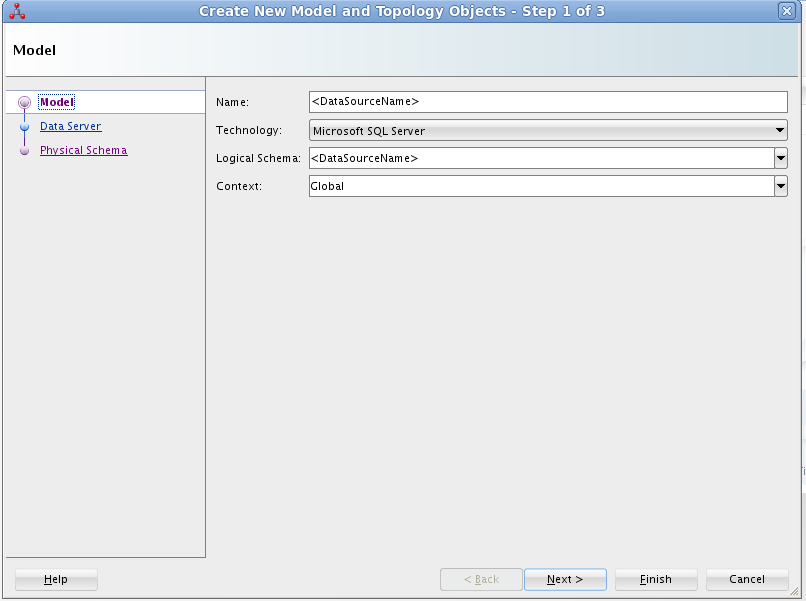
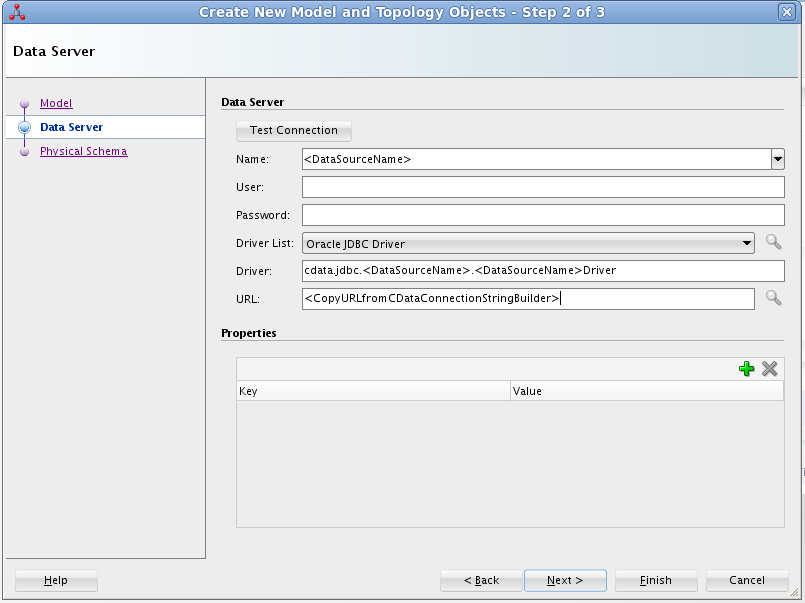
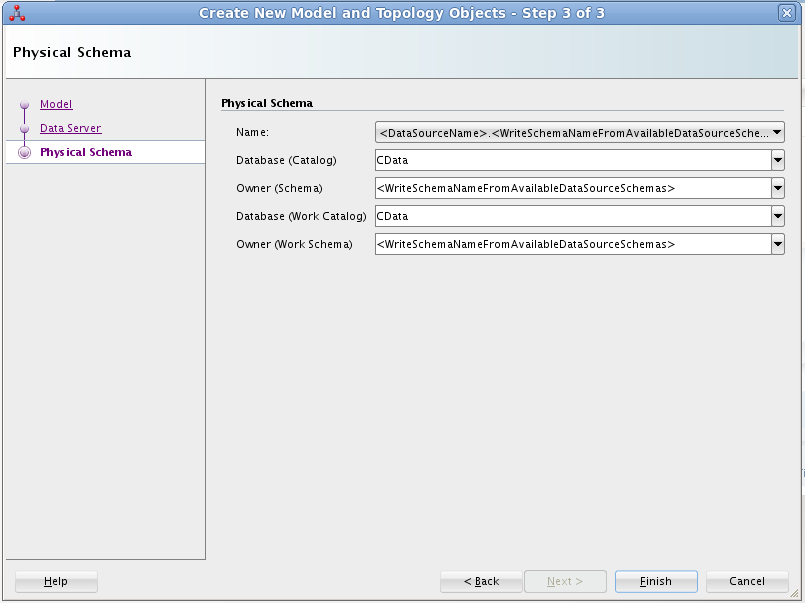
Redshift への接続には次を設定します:
Server およびPort の値はAWS の管理コンソールで取得可能です:
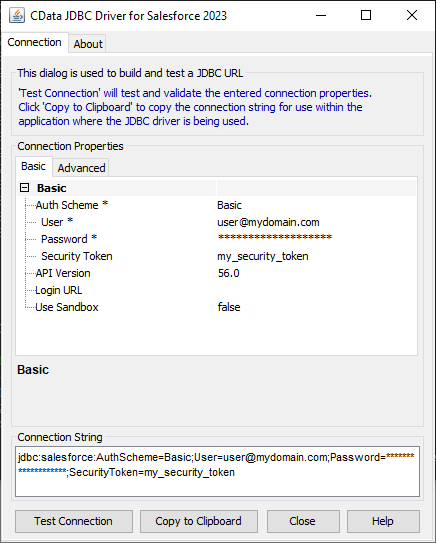
JDBC URL の作成の補助として、Redshift JDBC Driver に組み込まれている接続文字列デザイナーが使用できます。JAR ファイルをダブルクリックするか、コマンドラインからjar ファイルを実行します。
java -jar cdata.jdbc.redshift.jar
接続プロパティを入力し、接続文字列をクリップボードにコピーします。
一般的な接続文字列は次のとおりです。
jdbc:redshift:User=admin;Password=admin;Database=dev;Server=examplecluster.my.us-west-2.redshift.amazonaws.com;Port=5439;
リバースエンジニアリング後、ODI でRedshift データを操作できるようになります。
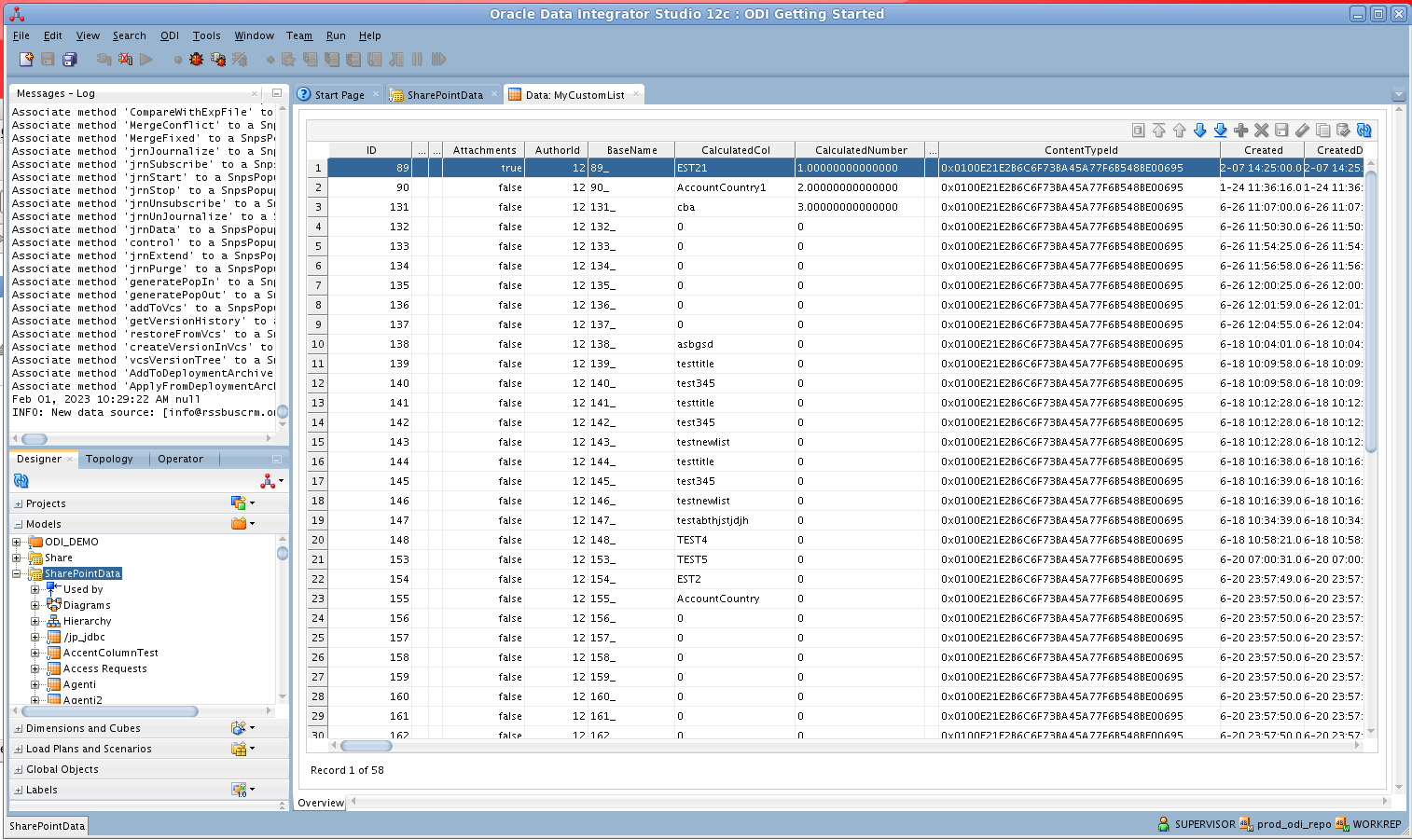
Redshift データを編集し保存するには、Designer ナビゲーターでモデルアコーディオンを展開し、テーブルを右クリックして「Data」をクリックします。「Refresh」をクリックしてデータの変更を取得します。変更が完了したら「Save Changes」をクリックします。
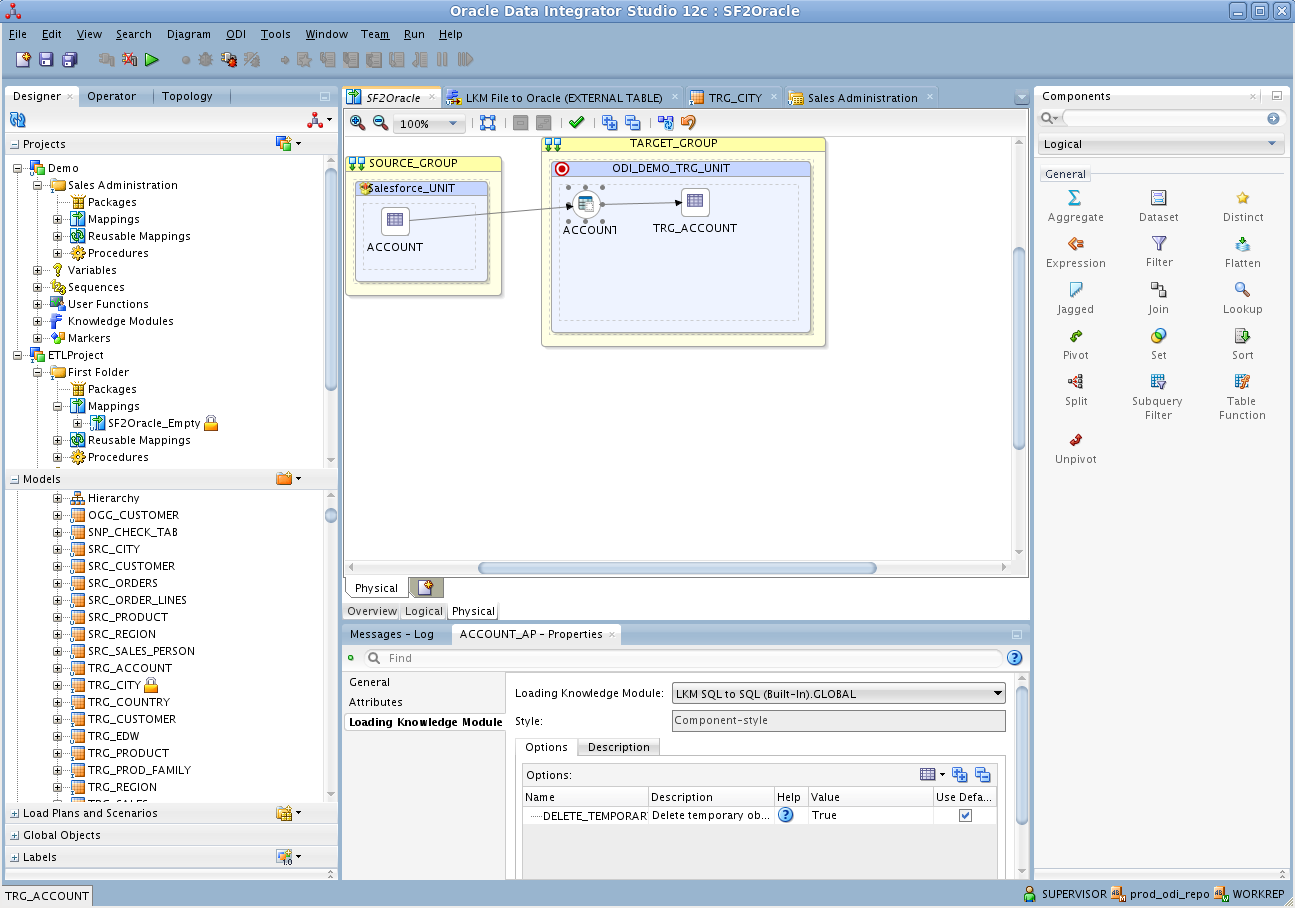
次の手順に従って、Redshift からETL を作成します。Orders エンティティをODI Getting Started VM に含まれているサンプルデータウェアハウスにロードします。
SQL Developer を開き、Oracle データベースに接続します。Connections ぺインでデータベースのノードを右クリックし、「New SQL Worksheet」をクリックします。
もしくは、SQLPlus を使用することもできます。コマンドプロンプトから、以下のように入力します。
sqlplus / as sysdba
CREATE TABLE ODI_DEMO.TRG_ORDERS (SHIPCITY NUMBER(20,0),ShipName VARCHAR2(255));
これで、マッピングを実行してRedshift データをOracle にロードできます。