ノーコードでクラウド上のデータとの連携を実現。
詳細はこちら →Apache Spark Data Provider の30日間無償トライアルをダウンロード
30日間の無償トライアルへこんにちは!ウェブ担当の加藤です。マーケ関連のデータ分析や整備もやっています。
Spark 用のCData ADO.NET プロバイダーはSpark をバックアップ、レポート、フルテキスト検索、分析などを行うアプリケーションに接続します。
ここでは、SQL サーバー SSIS ワークフロー内でSpark 用のプロバイダーを使用して、Spark をMicrosoft SQL サーバーデータベースに直接転送する方法を説明します。 以下のアウトラインと同じ手順を、CData ADO.NET データプロバイダーにて使用することで、SSIS 経由でSQL サーバーを直接リモートデータに接続できます。
Data Flow 画面で、ツールボックスから[ADO.NET Source] と[OLE DB Destination] を追加します。
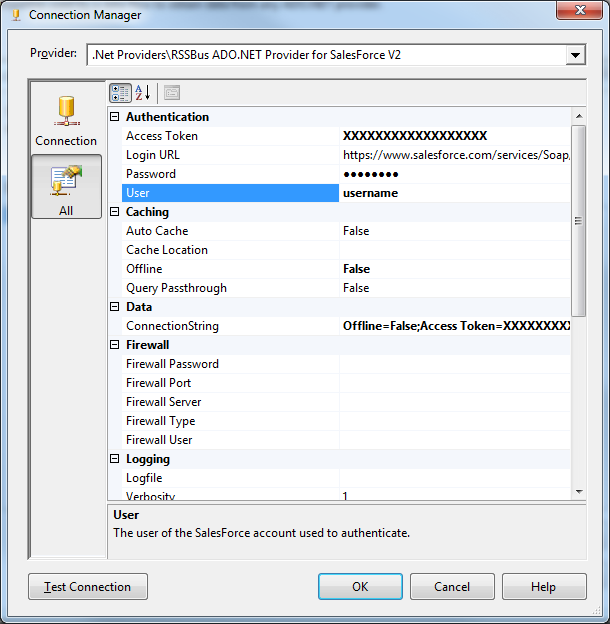
Connection Manager で、Spark 用に接続の詳細を入力します。下は一般的な接続文字列です。
Server=127.0.0.1;
SparkSQL への接続を確立するには以下を指定します。
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。Note:必要な値は、「クラスター」に移動して目的のクラスターを選択し、 「Advanced Options」の下にある「JDBC/ODBC」タブを選択することで、Databricks インスタンスで見つけることができます。
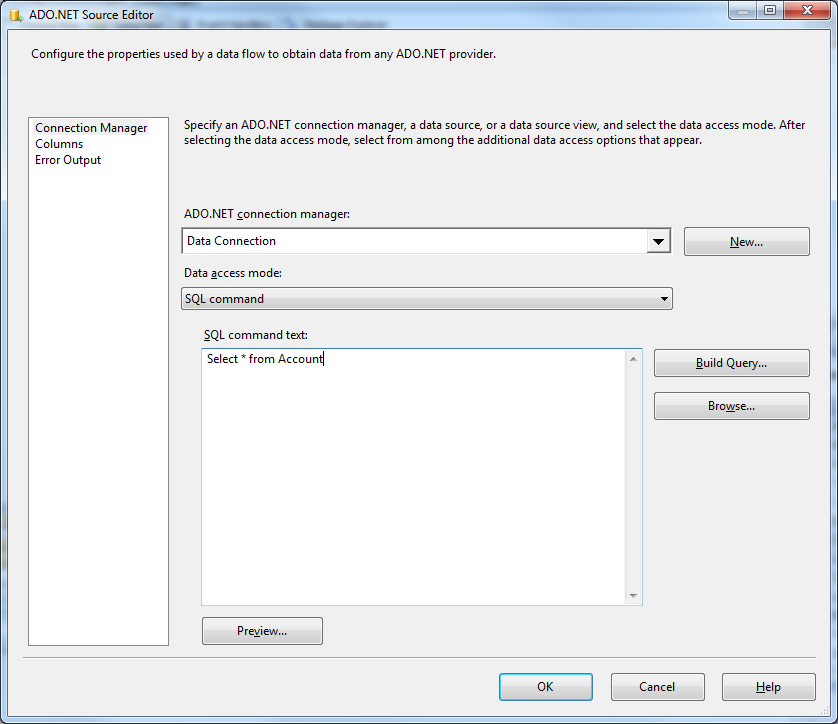
DataReader editor を開き、次のインフォメーションを設定します。
SELECT City, Balance FROM Customers
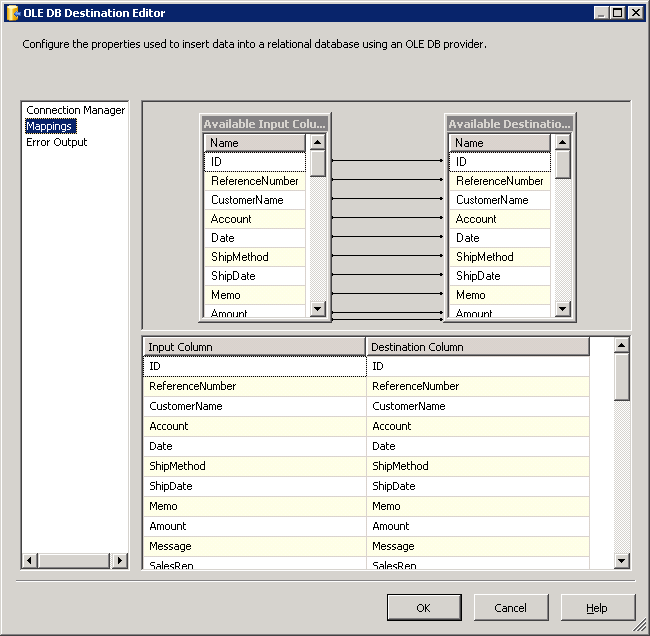
OLE DB Destination を開き、Destination Component Editor で次のインフォメーションを入力します。
Mappings 画面で必要なプロパティを設定します。