BizTalk でSpark にストアドプロシージャを実行する
CData BizTalk Adapter が提供するストアドプロシージャを使用して、BizTalk のSpark を自動化できます。ストアドプロシージャは、基盤となるAPI で使用できるアクションを実装しています。
加藤龍彦
デジタルマーケティング
最終更新日:2021-07-17
こんにちは!ウェブ担当の加藤です。マーケ関連のデータ分析や整備もやっています。
ストアドプロシージャは、SELECT 、INSERT 、UPDATE 、DELETE としては表すことができないSpark アクションを実装します。この記事では、ストアドプロシージャ用のスキーマを作成する方法を説明します。このスキーマを使用して、送信ポートからストアドプロシージャを実行できます。
プロジェクトにアダプターを追加する
[Add Adapter] ウィザードから、アダプターをVisual Studio のBizTalk サーバープロジェクトに追加します。このアダプターは、ストアドプロシージャへの入力とその結果に関するメタデータを返します。このメタデータを使用してスキーマを作成します。
- [Solution Explorer] の[project] で右クリックし、[Add] -> [Add Generated Items] と進みます。
- [resulting dialog box] の[Add Adapter Metadata] を選択します。
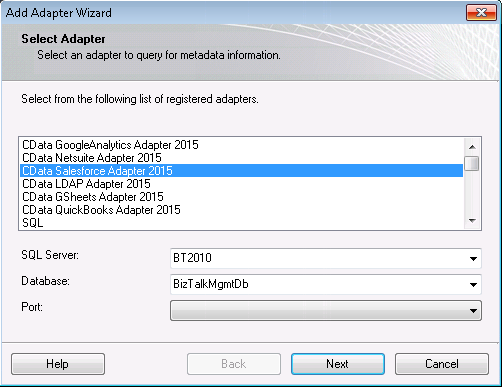
- 表示される[Add Adapter] ウィザードで、リストからアダプターを選択します。
- [Port menu] では、選択を空白のままにします。もしくは、Spark アダプターを使用するように構成されている受信場所や送信ポートを選択します。
![CData Adapters in the Select Adapter wizard.(Salesforce is shown.)]()
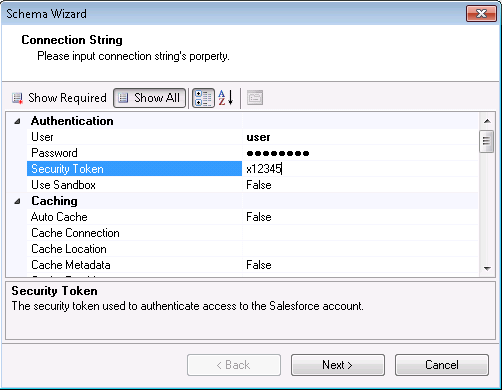
送信ポートまたは受信場所に、認証資格情報と他の接続プロパティが構成されていない場合、[Connection String] ページで、それらを入力します。下は一般的な接続文字列です。
Server=127.0.0.1;
SparkSQL への接続
SparkSQL への接続を確立するには以下を指定します。
- Server:SparkSQL をホストするサーバーのホスト名またはIP アドレスに設定。
- Port:SparkSQL インスタンスへの接続用のポートに設定。
- TransportMode:SparkSQL サーバーとの通信に使用するトランスポートモード。有効な入力値は、BINARY およびHTTP です。デフォルトではBINARY が選択されます。
- AuthScheme:使用される認証スキーム。有効な入力値はPLAIN、LDAP、NOSASL、およびKERBEROS です。デフォルトではPLAIN が選択されます。
Databricks への接続
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。Note:必要な値は、「クラスター」に移動して目的のクラスターを選択し、
「Advanced Options」の下にある「JDBC/ODBC」タブを選択することで、Databricks インスタンスで見つけることができます。
- Server:Databricks クラスターのサーバーのホスト名に設定。
- Port:443
- TransportMode:HTTP
- HTTPPath:Databricks クラスターのHTTP パスに設定。
- UseSSL:True
- AuthScheme:PLAIN
- User:'token' に設定。
- Password:パーソナルアクセストークンに設定(値は、Databricks インスタンスの「ユーザー設定」ページに移動して「アクセストークン」タブを選択することで取得できます)。
![The connection string properties used by the Spark Adapter.(Salesforce is shown.)]()
スキーマを作成する
[Add Adapter] ウィザードで接続プロパティを入力すると、[Schema] ウィザードが表示されます。
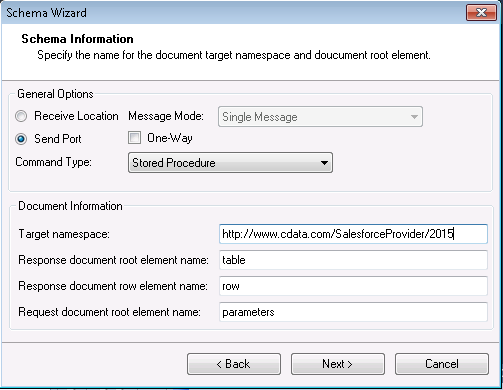
- 次の[Schema Information] のページでは、Spark アダプターを使用するために構成した送信ポートを選択します。
- CData Spark アダプターが要請応答送信ポートで構成されている場合、[One-Way] オプションを無効にします。
- [Command Type] メニューで、ストアドプロシージャを選択します。
![Schema options for a stored procedure.(Salesforce is shown.)]()
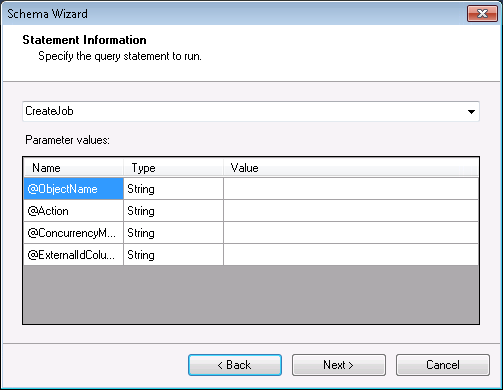
- メニューからストアドプロシージャを選択し、インプットパラメータの値を入力します。
![Input parameters and values.(Salesforce is shown.)]()
- ウィザードで表示される概要の設定を確認して[Finish] をクリックし、schema.xsd ファイルを作成します。
スキーマを処理する
BizTalk アプリでスキーマを使用する際は、こちらのチュートリアルをご覧ください。