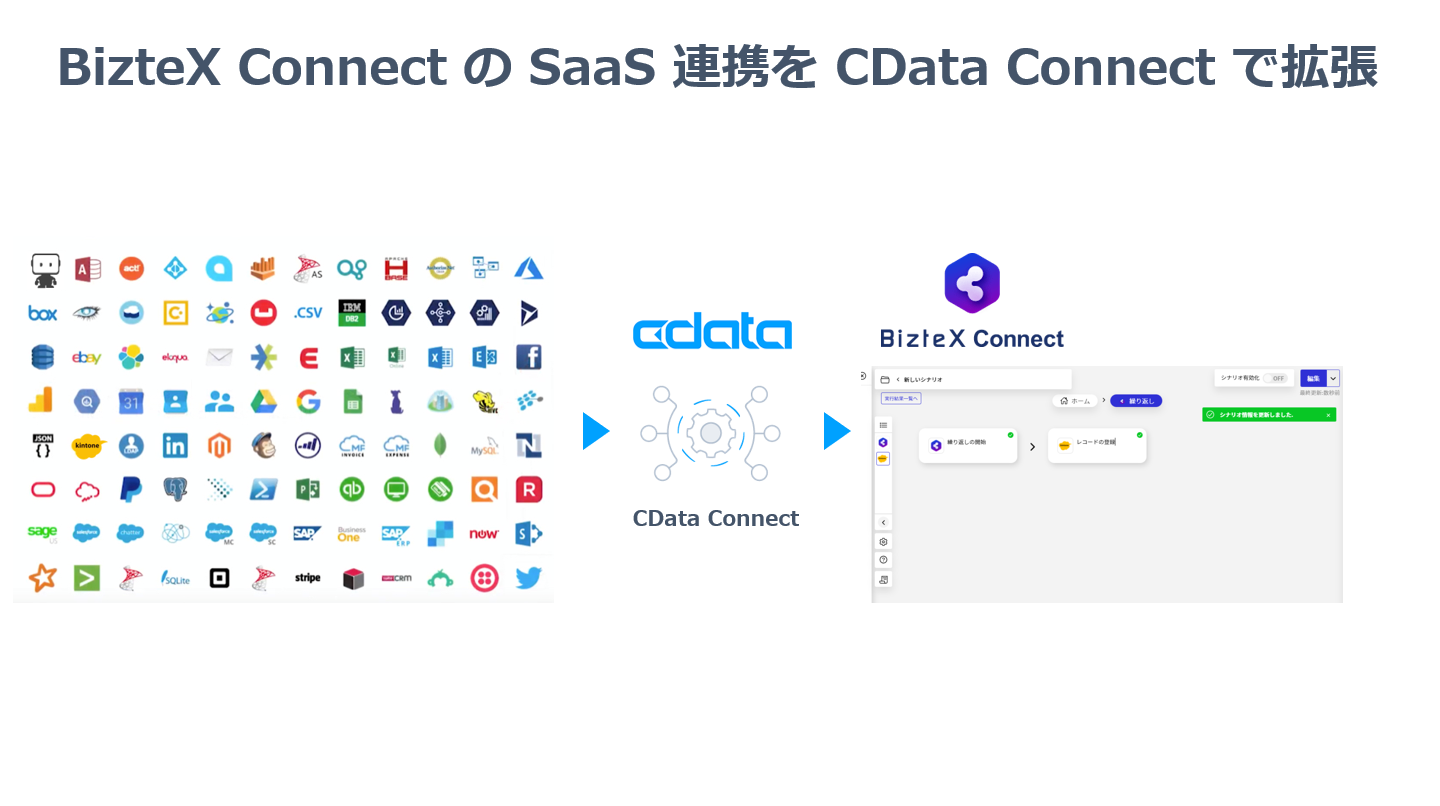
ノーコードでクラウド上のデータとの連携を実現。
詳細はこちら →こんにちは!リードエンジニアの杉本です。
BizteX Connect は BizteX 社が提供する国産iPaaS です。ノーコードでkintone やChatwork などさまざまなクラウドサービスと連携したフローを作成し、業務の自動化・効率化を実現することができます。この記事では、CData Connect Server を経由して BizteX Connect からSpark データを取得し活用する方法を説明します。
CData Connect Server は、Spark データのクラウド to クラウドの仮想OData インターフェースを提供し、BizteX Connect からリアルタイムにSpark データへ連携することができます。
まずCData Connect Server でデータソースへの接続およびOData API エンドポイント作成を行います。
SparkSQL への接続を確立するには以下を指定します。
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。Note:必要な値は、「クラスター」に移動して目的のクラスターを選択し、 「Advanced Options」の下にある「JDBC/ODBC」タブを選択することで、Databricks インスタンスで見つけることができます。
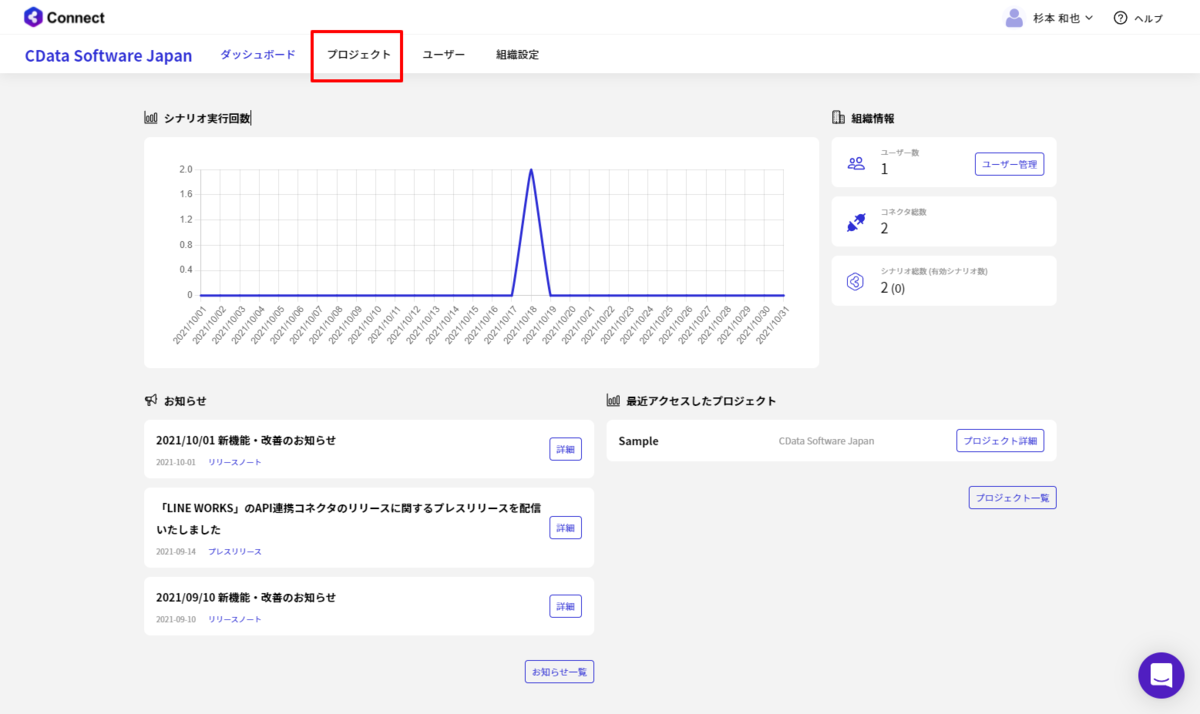
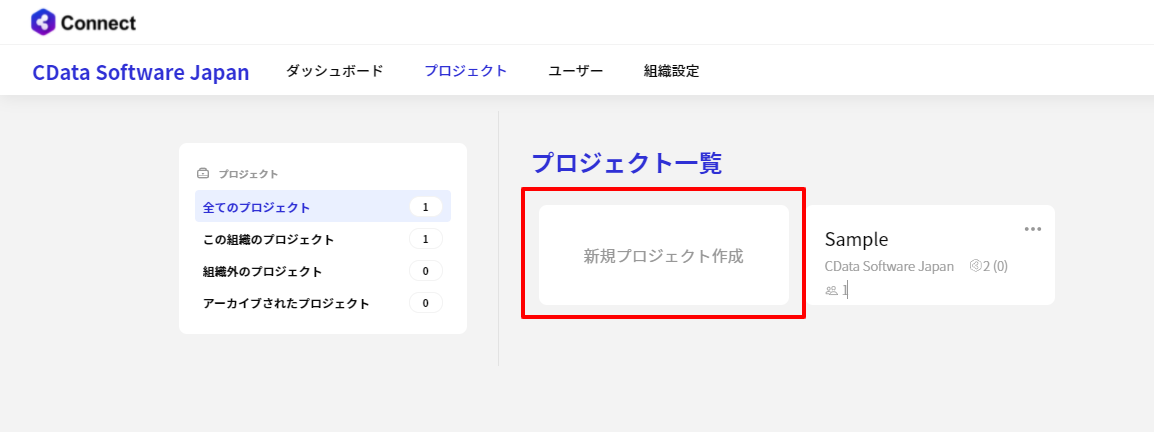
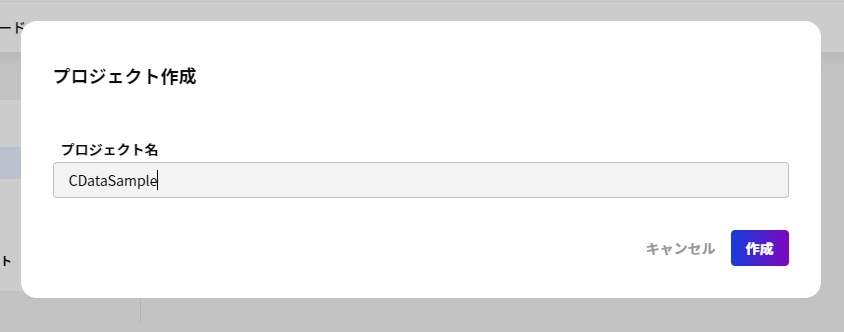
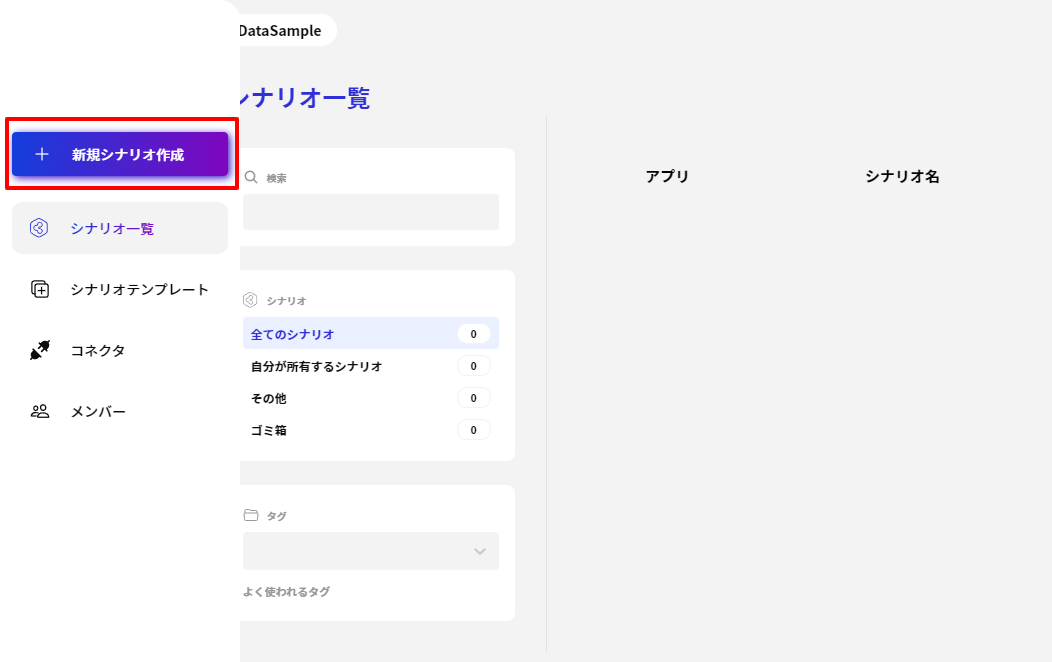
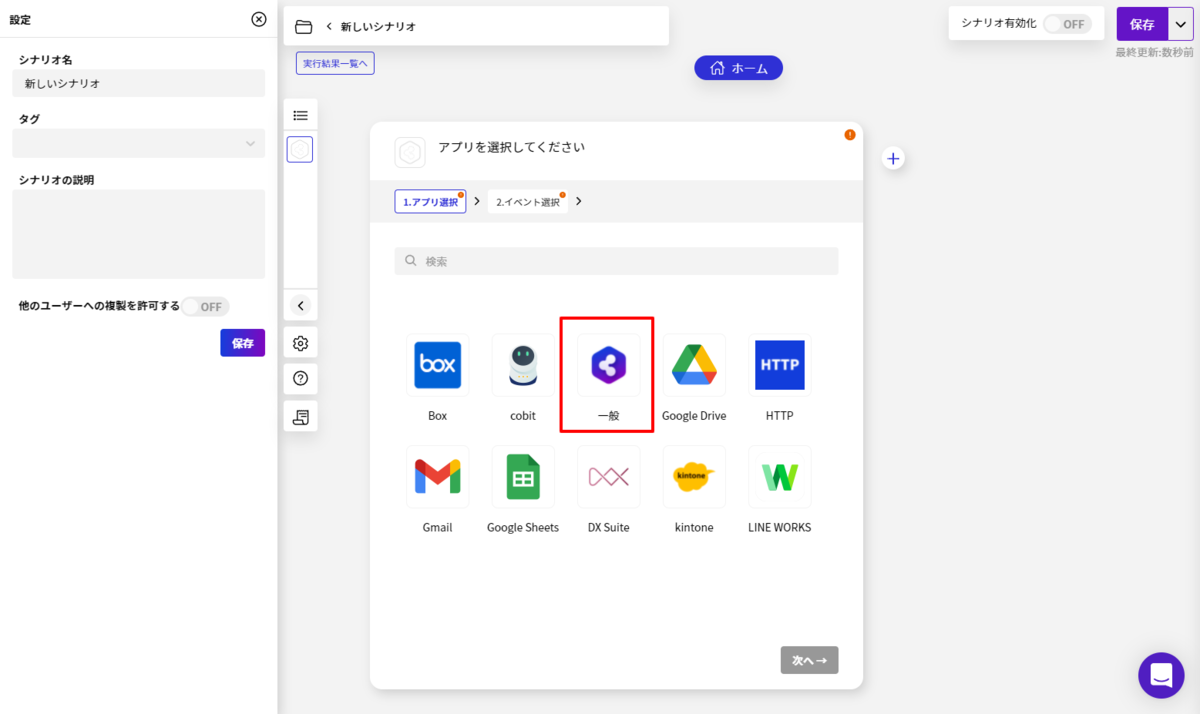
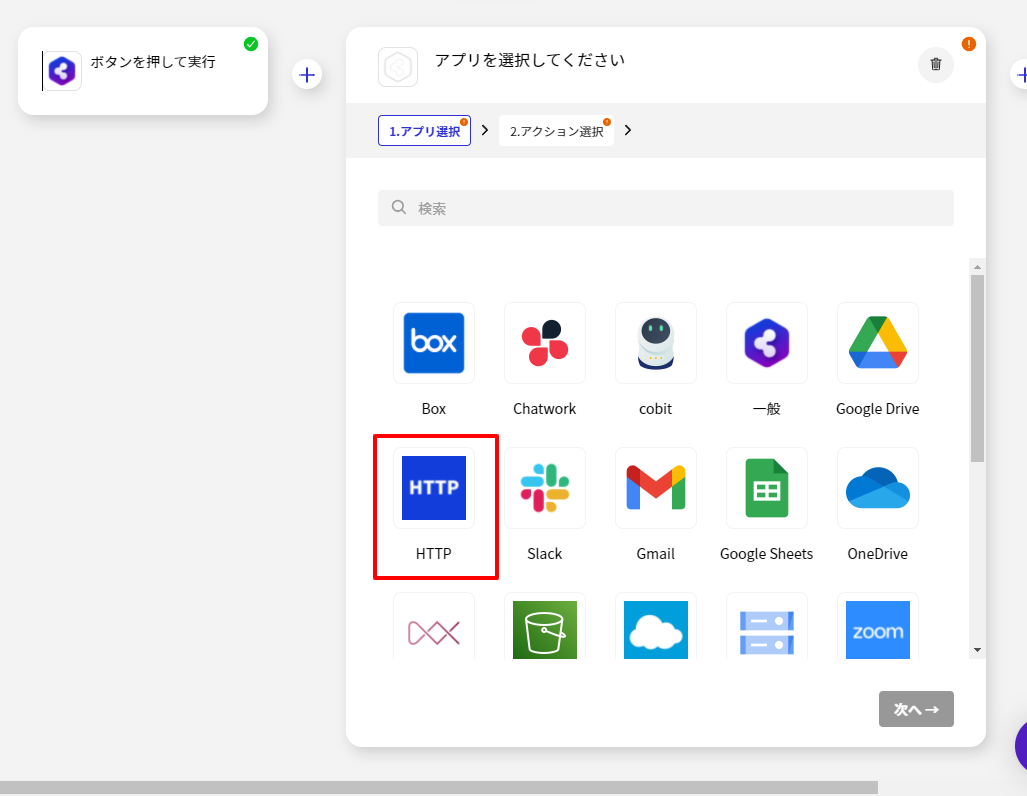
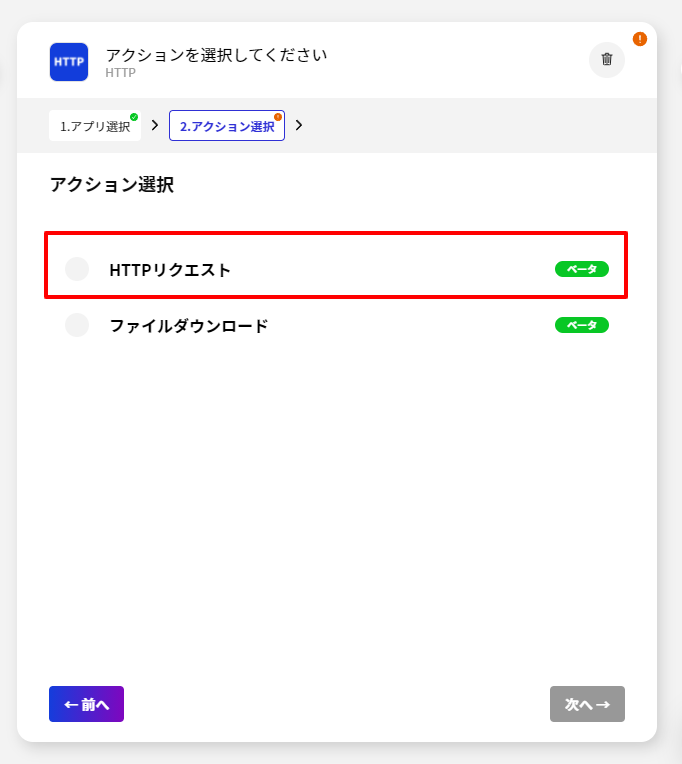
CData Connect Server 側の準備が完了したら、早速BizteX Connect 側でプロジェクト・シナリオの作成を開始します。
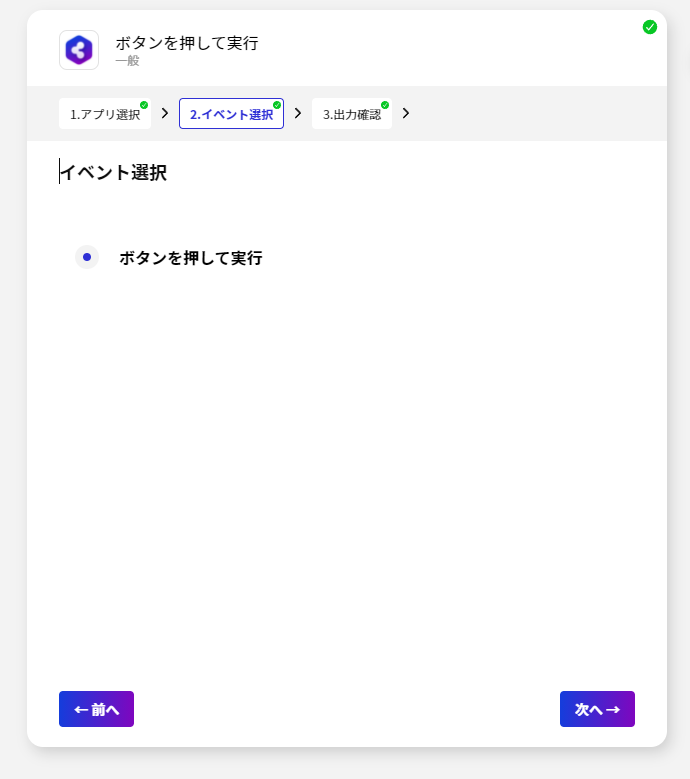
シナリオの作成で一番最初に設定することが、起動イベントの構成です。BizteX Connect ではさまざまな起動イベントが存在しますが、今回は検証用途として「手動」実行にしてみました。
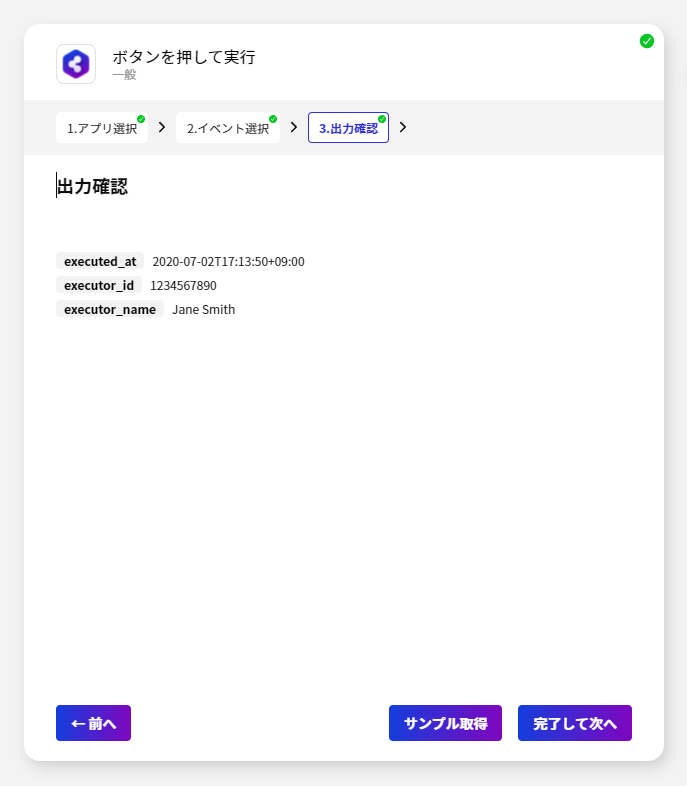
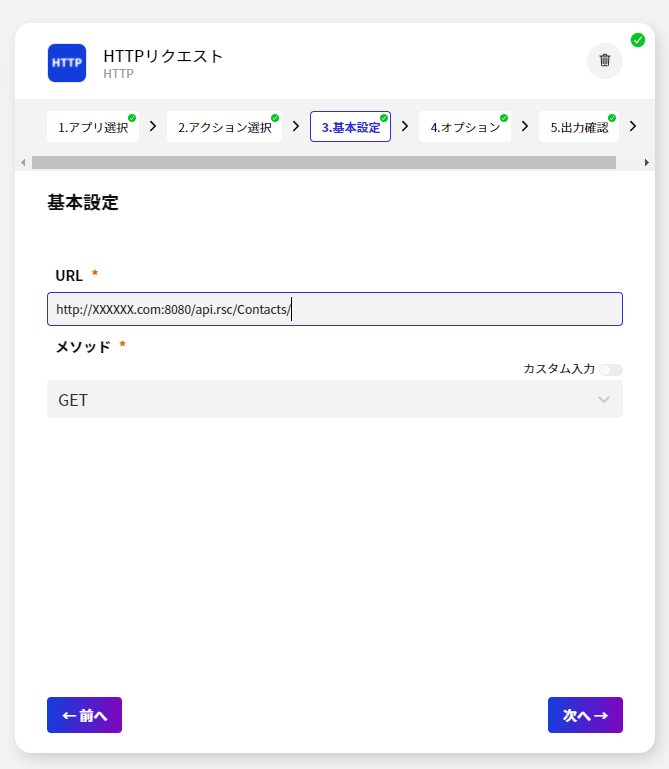
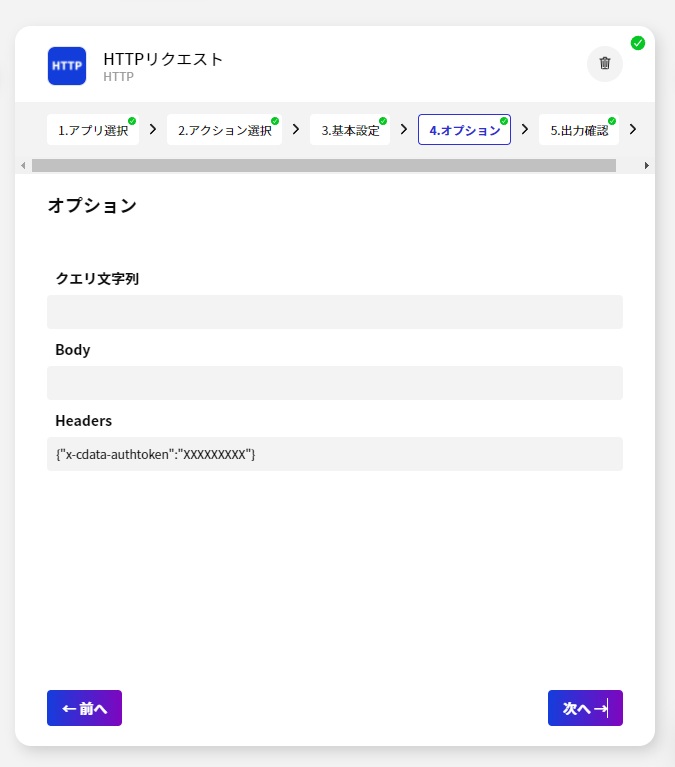
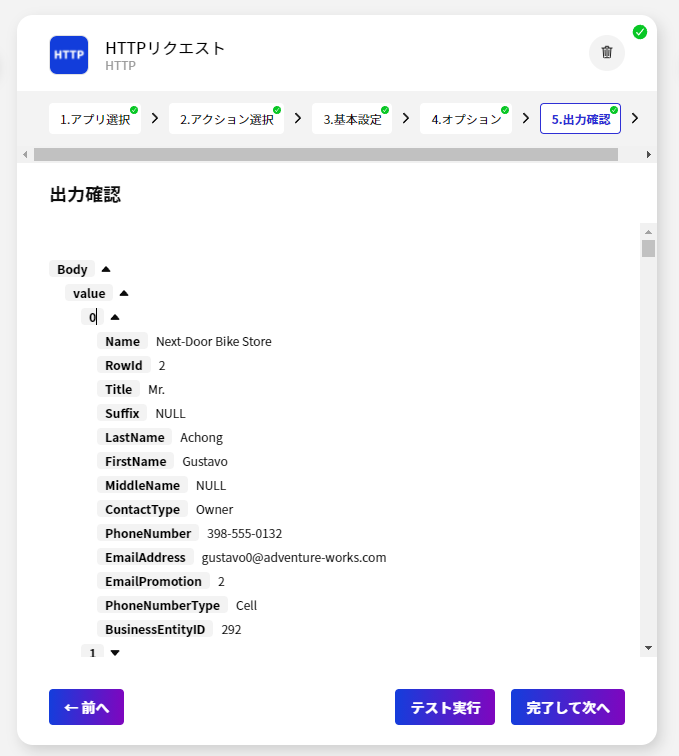
今回のシナリオでは、Spark のデータを取得して BizteX Connect で扱えるようにします。
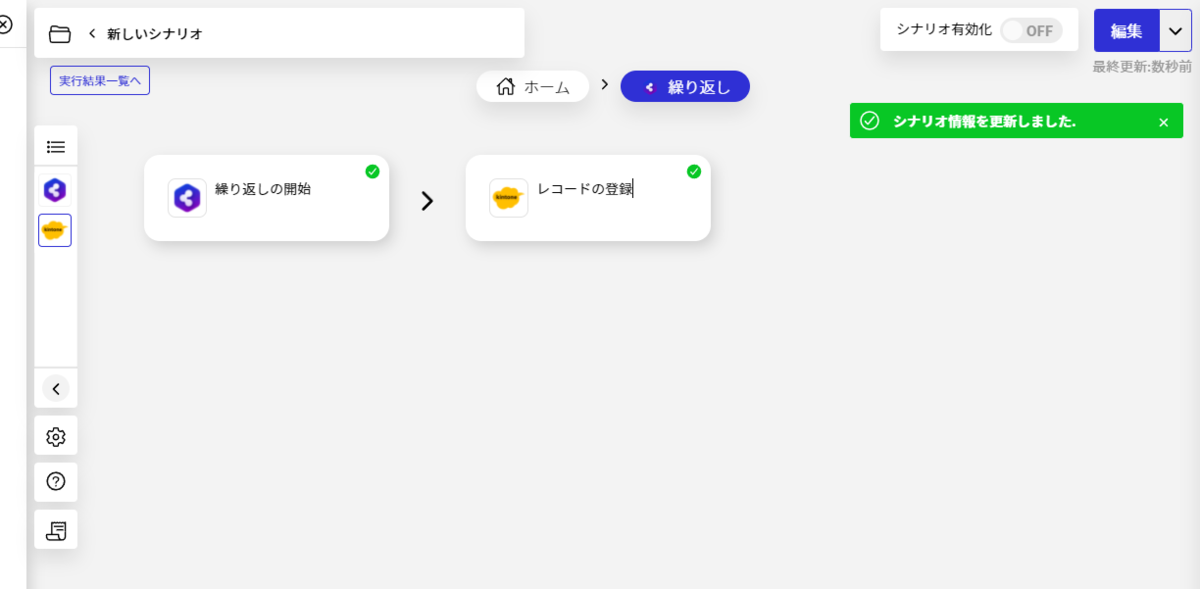
このように、CData Connect Server を経由することで、API 側の複雑な仕様を意識せずにSpark と連携をしたシナリオをBizteX Connect で作成できます。他にも多くのデータソースに対応するCData Connect Server の詳細をこちらからご覧ください。