ノーコードでクラウド上のデータとの連携を実現。
詳細はこちら →Apache Spark Driver の30日間無償トライアルをダウンロード
30日間の無償トライアルへCData


こんにちは!テクニカルディレクターの桑島です。
CData Driver for SparkSQL を使って、国産BIツールのActionista!(https://www.justsystems.com/jp/products/actionista/) からSpark データをノーコードで連携して利用できます。この記事では、間にETL/EAI ツールをはさむ方法ではなく、CData JDBC Driver for SparkSQL をActionista! 側に組み込むだけで連携を実現できます。
# SparkSQL
loader.jdbc.displayName.SparkSQL = SparkSQL
loader.jdbc.initJdbcUrl.SparkSQL = jdbc:sparksql:
loader.jdbc.url.SparkSQL = jdbc:sparksql:
loader.jdbc.driver.SparkSQL = cdata.jdbc.sparksql.SparkSQLDriver
loader.jdbc.dbmsInfo.SparkSQL = cdata.jdbc.sparksql.SparkSQLDriver
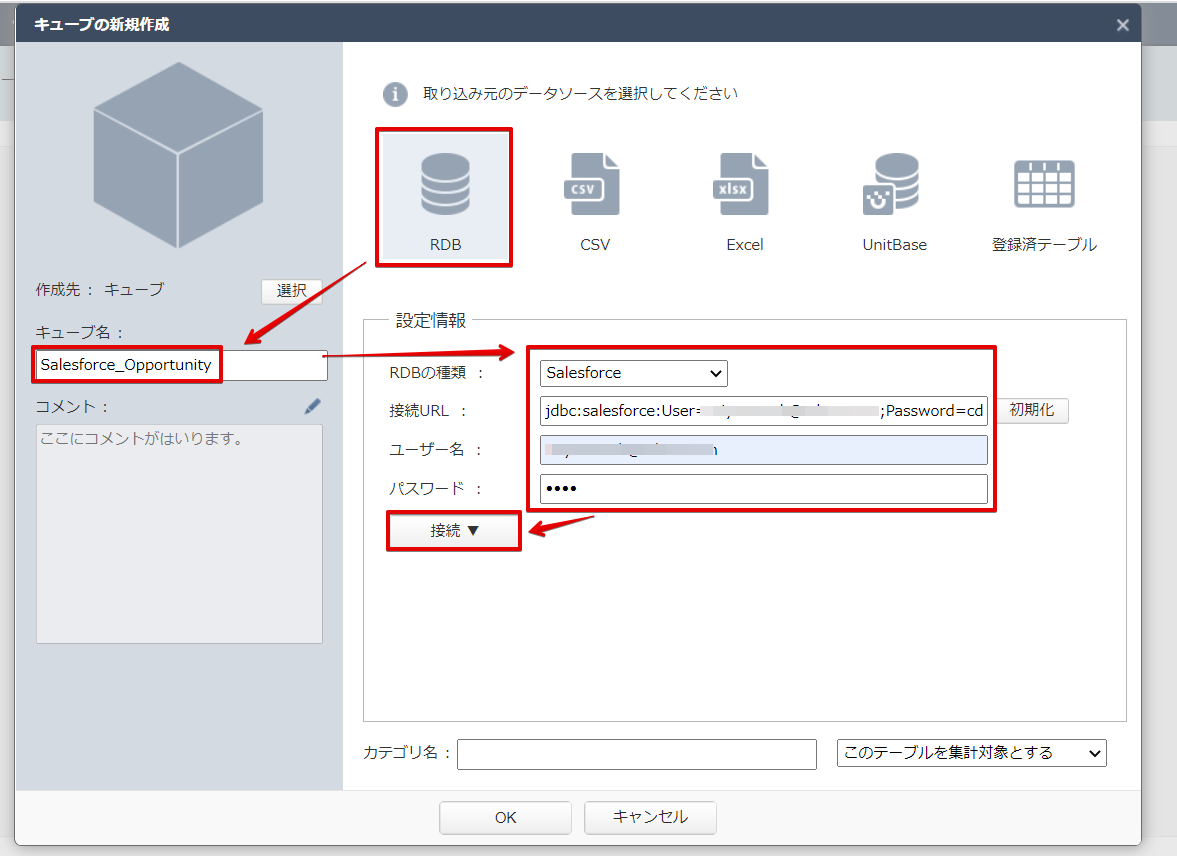
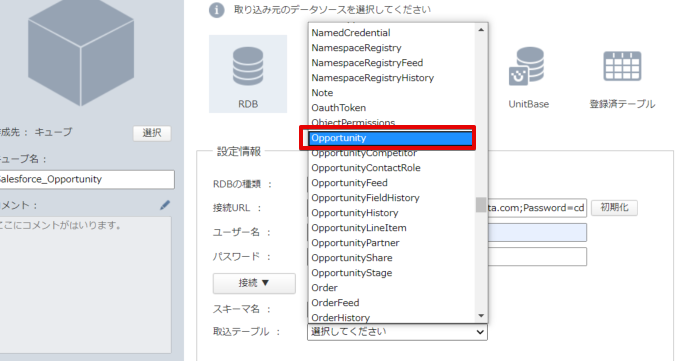
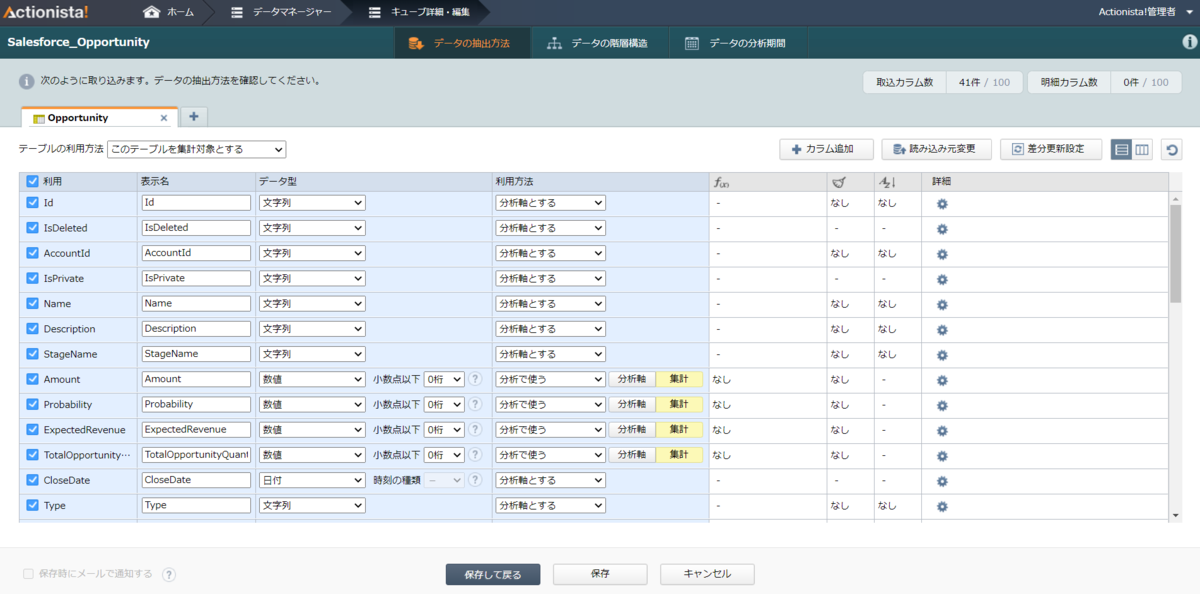
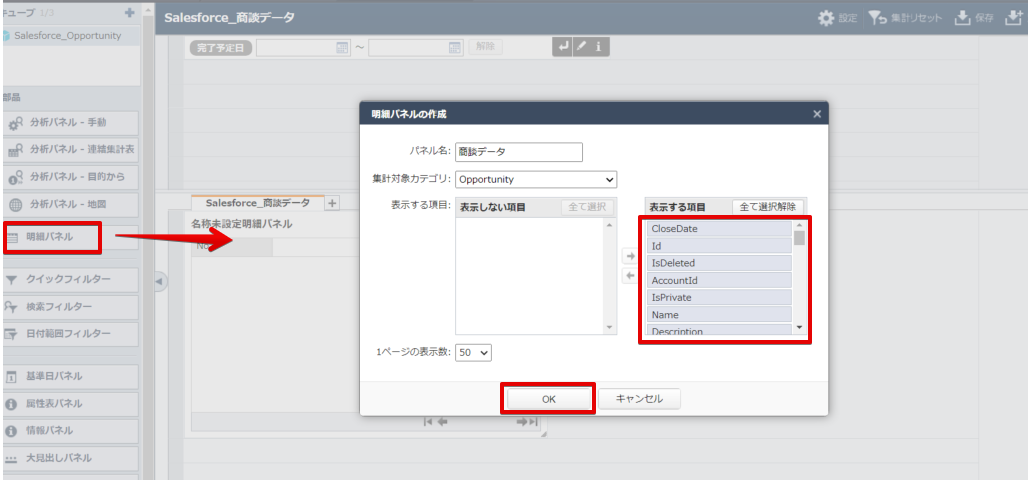
Actionista! ではデータの保持をキューブという単位で保存します。また、クエリでデータソースからデータを取得するのではなく、キューブに対してクエリを行います。このステップでは、Spark データをキューブに取り込み、分析で使えるようにします。
SparkSQL への接続を確立するには以下を指定します。
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。Note:必要な値は、「クラスター」に移動して目的のクラスターを選択し、 「Advanced Options」の下にある「JDBC/ODBC」タブを選択することで、Databricks インスタンスで見つけることができます。
jdbc:sparksql:Server=127.0.0.1;
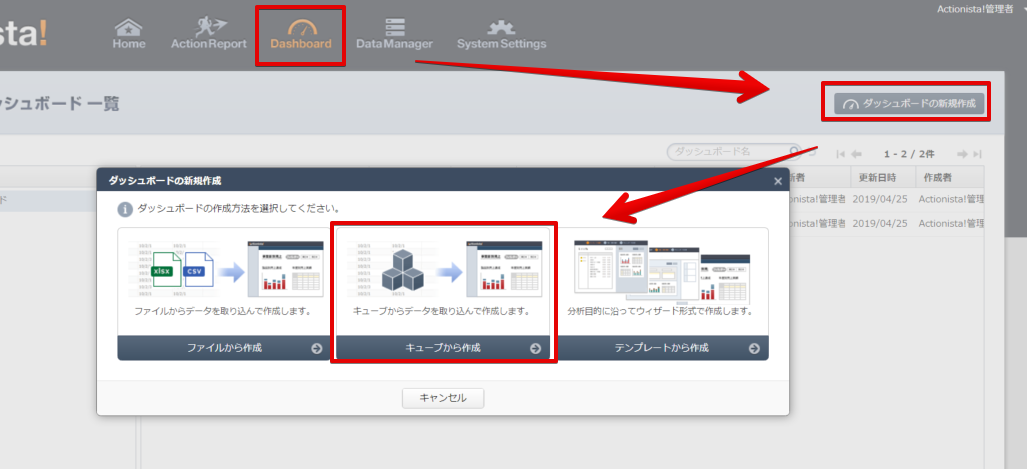
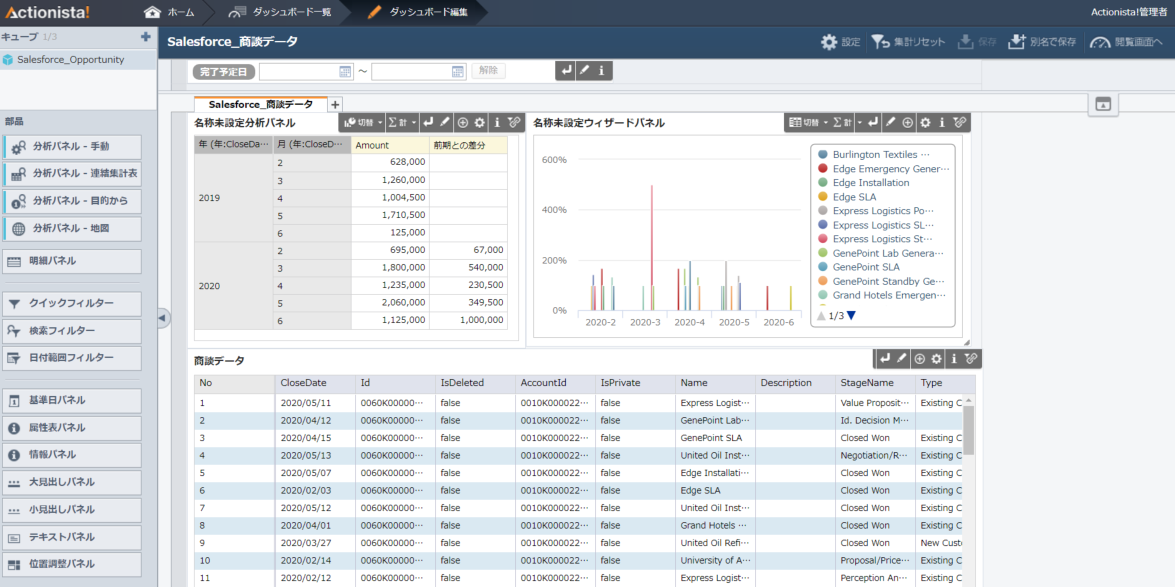
それでは簡単なダッシュボードを作成していきます。
CData JDBC Driver for SparkSQL をActionista! で使うことで、ノーコードでSpark データをビジュアライズできました。ぜひ、30日の無償評価版をお試しください。