ノーコードでクラウド上のデータとの連携を実現。
詳細はこちら →Apache Spark Driver の30日間無償トライアルをダウンロード
30日間の無償トライアルへCData


こんにちは!ウェブ担当の加藤です。マーケ関連のデータ分析や整備もやっています。
CData JDBC Driver for SparkSQL は、Aqua Data Studio のようなIDE のウィザード・アナリティクスにSpark データを統合します。本記事では、Spark データをコネクションマネージャーに接続してクエリを実行する手順を説明します。
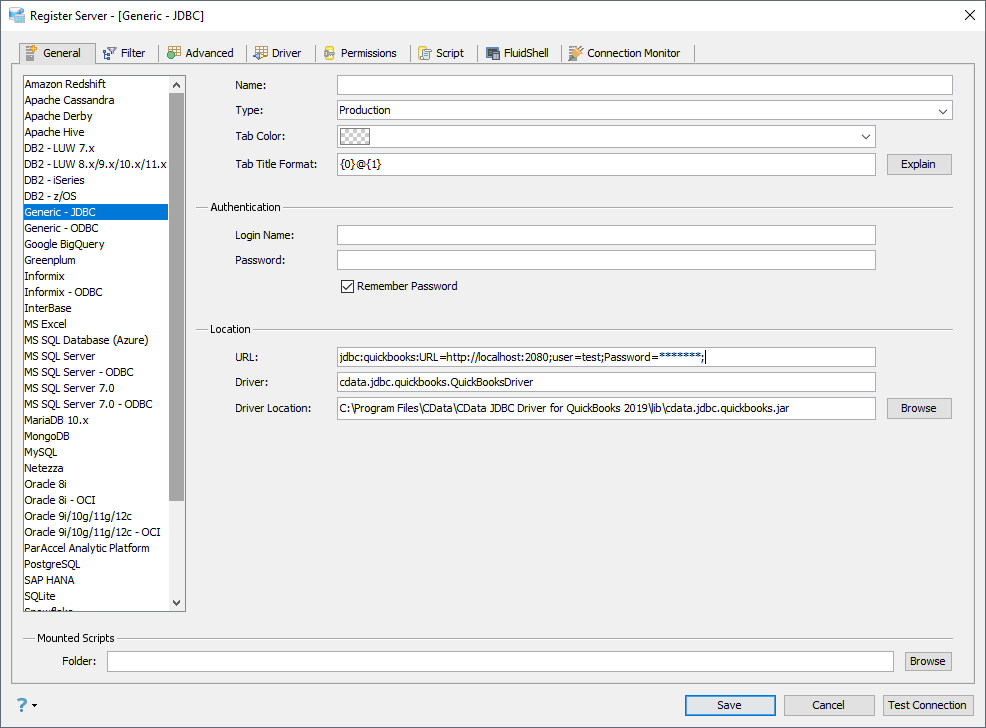
コネクションマネージャーで、新しいJDBC データソースとして、接続プロパティ設定を行い、保存します。Spark データがAqua Data Studio ツールから使えるようになります。
jdbc:sparksql:Server=127.0.0.1;
SparkSQL への接続を確立するには以下を指定します。
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。Note:必要な値は、「クラスター」に移動して目的のクラスターを選択し、 「Advanced Options」の下にある「JDBC/ODBC」タブを選択することで、Databricks インスタンスで見つけることができます。
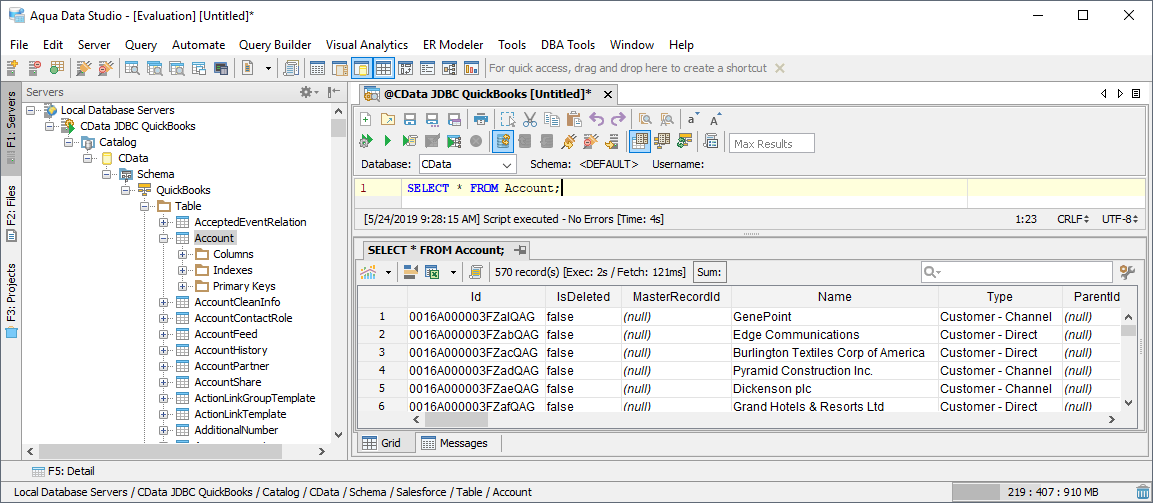
接続したテーブルにクエリを実行してみます。