ノーコードでクラウド上のデータとの連携を実現。
詳細はこちら →Apache Spark Driver の30日間無償トライアルをダウンロード
30日間の無償トライアルへこんにちは!ウェブ担当の加藤です。マーケ関連のデータ分析や整備もやっています。
CData JDBC Driver for SparkSQL は、JDBC をサポートするIDE にリアルタイムSpark データへの仮想DB 連携を実現します。JDBC 標準では、ビルトインのデータアクセスウィザードや、迅速な開発をサポートするその他のツールを使用できます。この記事では、NetBeans でSpark に接続する方法を説明します。接続を作成して[Table Editor]でSpark を編集および保存、 していきます。
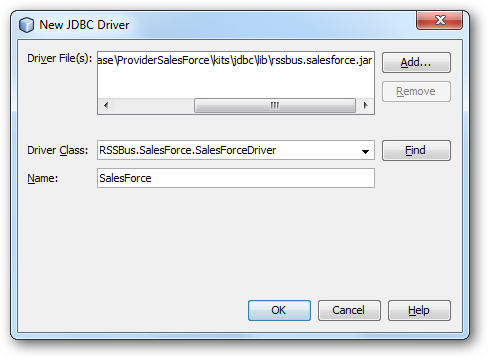
JDBC データソースを作成するには、[Service]ウィンドウの[Database]ノードを展開し、[Drivers]ノードを右クリックして[New Driver]を選択します。[New Driver]ウィザードが表示されたら、以下の情報を入力します:
下記の手順に従って、必要な接続プロパティを定義します:
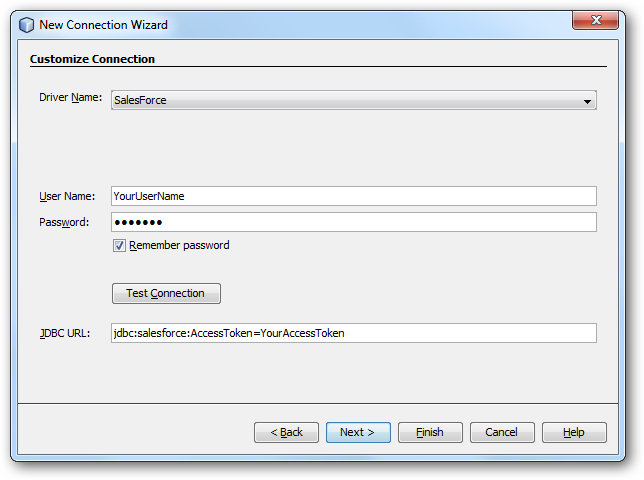
[Service]ウィンドウで、[Database]ノードを右クリックし[New Connection]をクリックします。
[New Connection]ウィザードで次の接続プロパティを入力します:
JDBC URL:JDBC URL を指定。
SparkSQL への接続を確立するには以下を指定します。
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。Note:必要な値は、「クラスター」に移動して目的のクラスターを選択し、 「Advanced Options」の下にある「JDBC/ODBC」タブを選択することで、Databricks インスタンスで見つけることができます。
jdbc:sparksql:Server=127.0.0.1;
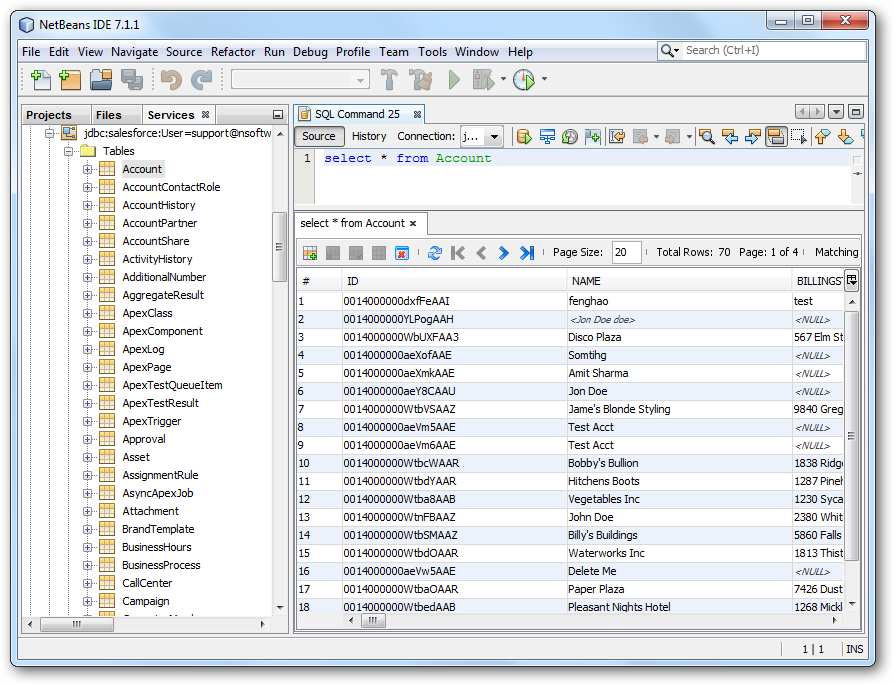
Spark に接続するには、[Database]ノードにある接続を右クリックし[Connect]をクリックします。接続が確立されたら、展開してスキーマ情報を見ることができます。
[Data Views]ウィンドウにテーブルをロードするには、テーブルを右クリックしてから[View Data]をクリックします。 [Data Views]ウィンドウではレコードの挿入、更新、および削除もできます。