ノーコードでクラウド上のデータとの連携を実現。
詳細はこちら →Apache Spark Driver の30日間無償トライアルをダウンロード
30日間の無償トライアルへCData


こんにちは!ウェブ担当の加藤です。マーケ関連のデータ分析や整備もやっています。
CData JDBC Driver for SparkSQL は、Spark へのリアルタイムアクセスをJava ベースのレポートサーバーに統合できる標準のデータベースドライバーです。この記事では、ドライバーをOracle Business Intelligence Enterprise Edition (OBIEE) にデプロイし、変更を反映するSpark に関する方法を示します。
以下のステップに従って、WebLogic のクラスパスにJDBC ドライバーを追加します。
WebLogic 12.2.1 の場合、ドライバーJAR と.lic ファイルをORACLE_HOME\user_projects\domains\MY_DOMAIN\lib のようにDOMAIN_HOME\lib に配置します。これらのファイルは、起動時にサーバーのクラスパスに追加されます。
ドライバーをクラスパスに手動で追加することもできます。これは、以前のバージョンで必要です。setDomainEnv.cmd (Windows) または setDomainEnv.sh (Unix) のPRE_CLASSPATH の前に以下を追加します。このスクリプトは、そのドメインのフォルダーのbin サブフォルダーにあります。例:ORACLE_HOME\user_projects\domains\MY_DOMAIN\bin.
set PRE_CLASSPATH=your-installation-directory\lib\cdata.jdbc.sparksql.jar;%PRE_CLASSPATH%
DOMAIN_HOME\bitools\bin でstop コマンドとstart コマンドを実行するなど、すべてのサーバーを再起動します。
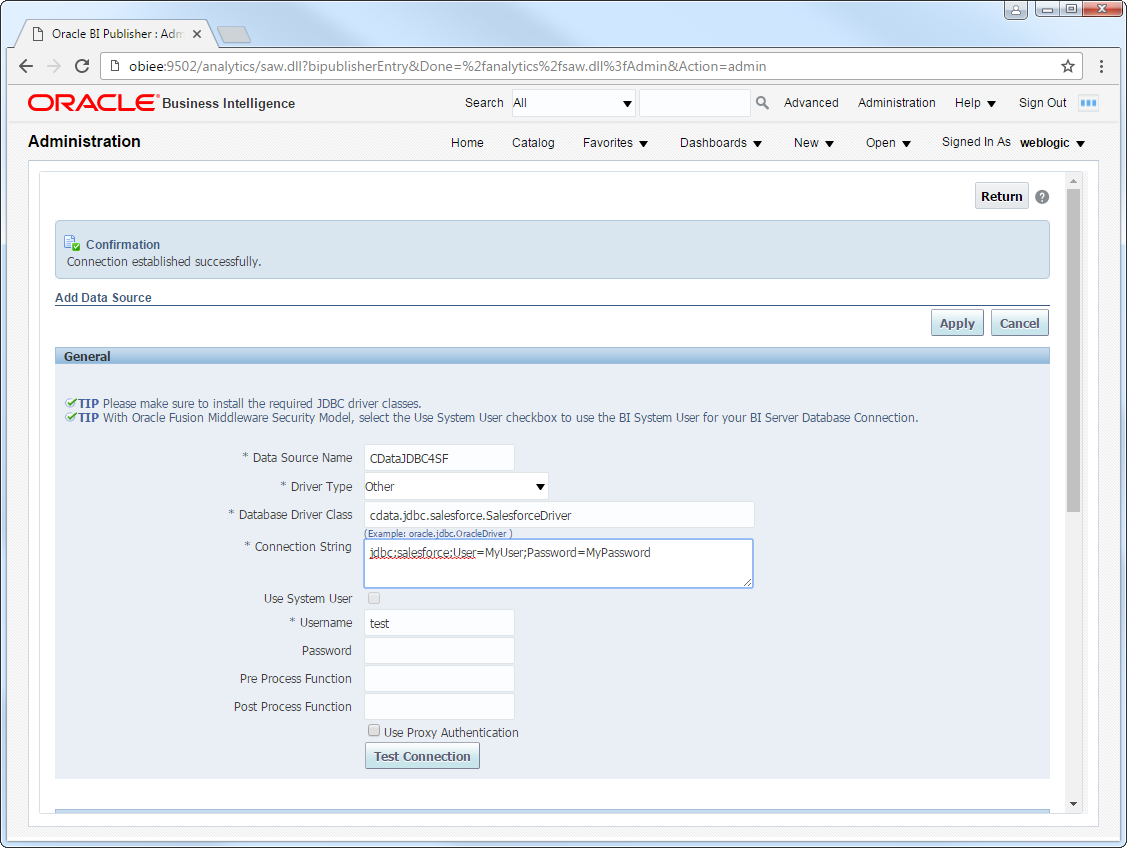
JDBC ドライバーをデプロイした後、BI Publisher からJDBC データソースを作成できます。
SparkSQL への接続を確立するには以下を指定します。
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。Note:必要な値は、「クラスター」に移動して目的のクラスターを選択し、 「Advanced Options」の下にある「JDBC/ODBC」タブを選択することで、Databricks インスタンスで見つけることができます。
JDBC URL の構成については、Spark JDBC Driver に組み込まれている接続文字列デザイナを使用してください。JAR ファイルのダブルクリック、またはコマンドラインからJAR ファイルを実行します。
java -jar cdata.jdbc.sparksql.jar
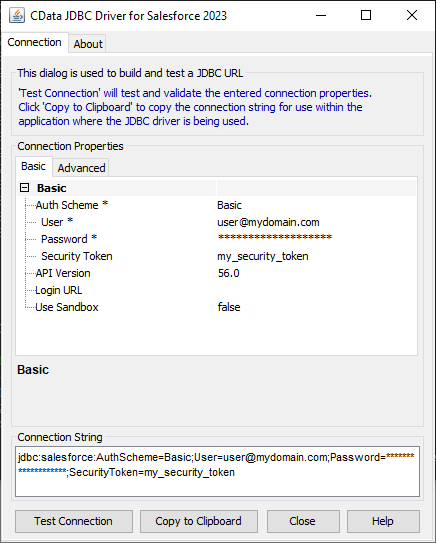
接続プロパティを入力し、接続文字列をクリップボードにコピーします。
JDBC URL を構成する際に、Max Rows プロパティを定めることも可能です。これによって戻される行数を制限するため、可視化・レポートのデザイン設計時のパフォーマンスを向上させるのに役立ちます。
以下は一般的なJDBC URL です。
jdbc:sparksql:Server=127.0.0.1;
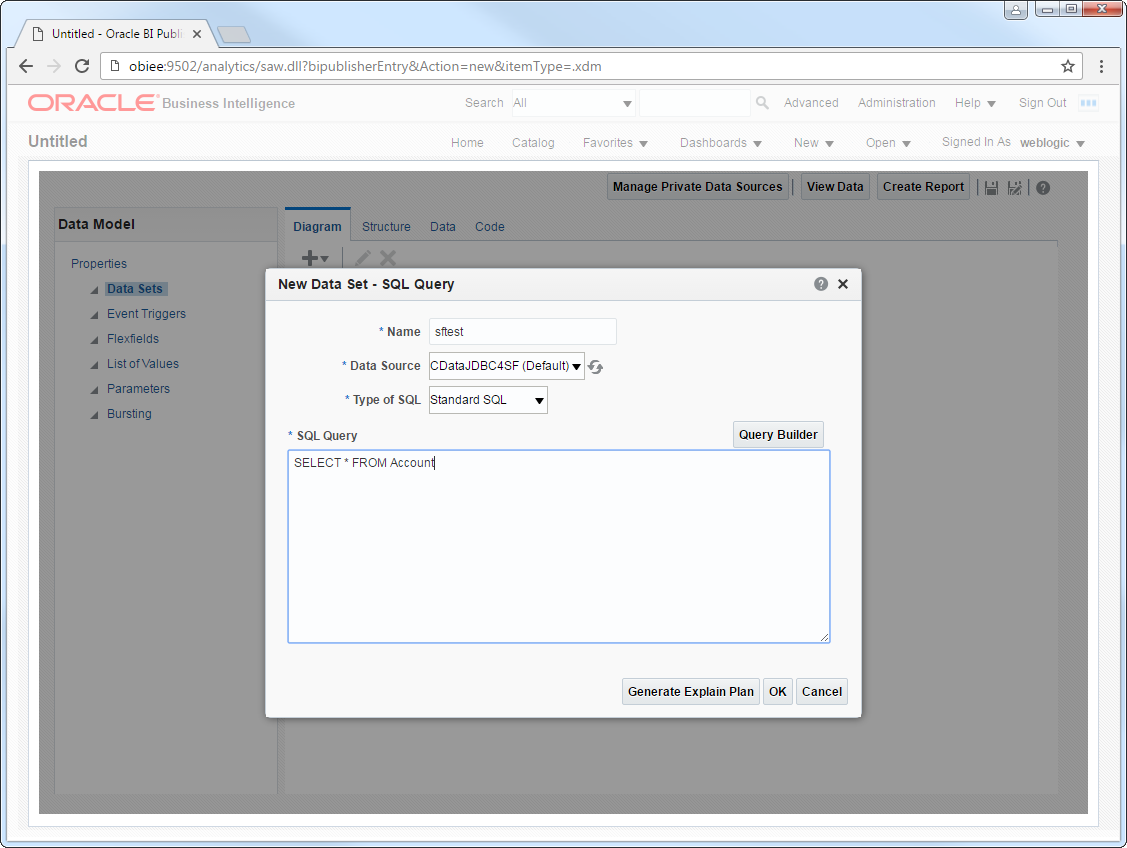
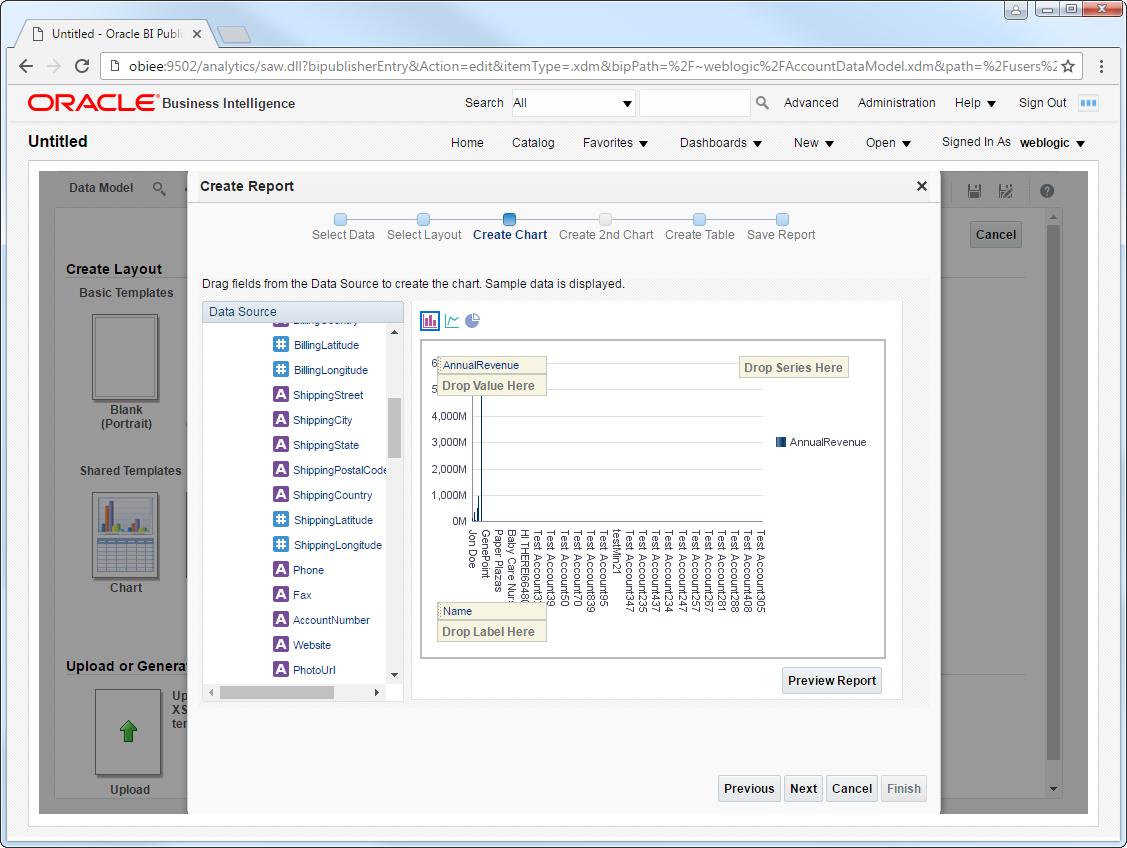
リアルタイムのSpark に基づいてレポートと分析を作成できるようになります。以下のステップに従って、標準のレポートウィザードを使用してSpark への変更を反映するインタラクティブなレポートを作成します。
SELECT City, Balance FROM Customers