ノーコードでクラウド上のデータとの連携を実現。
詳細はこちら →Apache Spark Driver の30日間無償トライアルをダウンロード
30日間の無償トライアルへCData


こんにちは!ドライバー周りのヘルプドキュメントを担当している古川です。
この記事では、CData JDBC Driver for SparkSQL をRapidMiner のプロセスと簡単に統合する方法を示します。この記事では、CData JDBC Driver for SparkSQL を使用してSpark をRapidMiner のプロセスに転送します。
以下のステップに従ってSpark へのJDBC 接続を確認できます。
jdbc:sparksql:
cdata.jdbc.sparksql.SparkSQLDriver
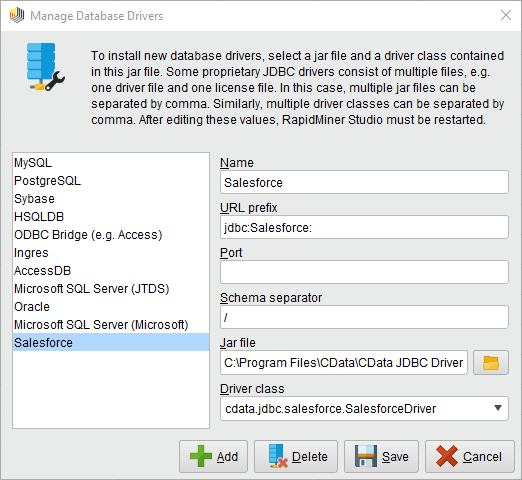
SparkSQL への接続を確立するには以下を指定します。
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。Note:必要な値は、「クラスター」に移動して目的のクラスターを選択し、 「Advanced Options」の下にある「JDBC/ODBC」タブを選択することで、Databricks インスタンスで見つけることができます。
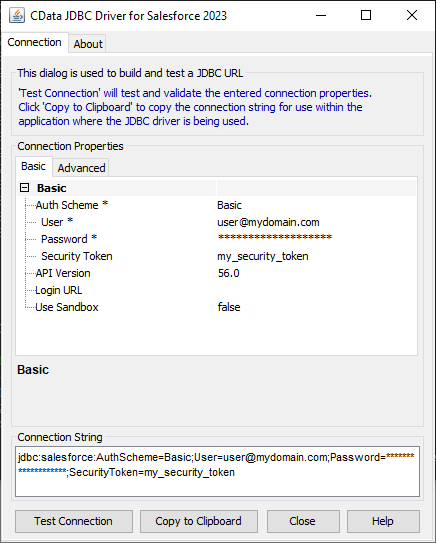
JDBC URL の構成については、Spark JDBC Driver に組み込まれている接続文字列デザイナを使用してください。JAR ファイルのダブルクリック、またはコマンドラインからJAR ファイルを実行します。
java -jar cdata.jdbc.sparksql.jar
接続プロパティを入力し、接続文字列をクリップボードにコピーします。
以下は一般的な接続文字列です。
Server=127.0.0.1;
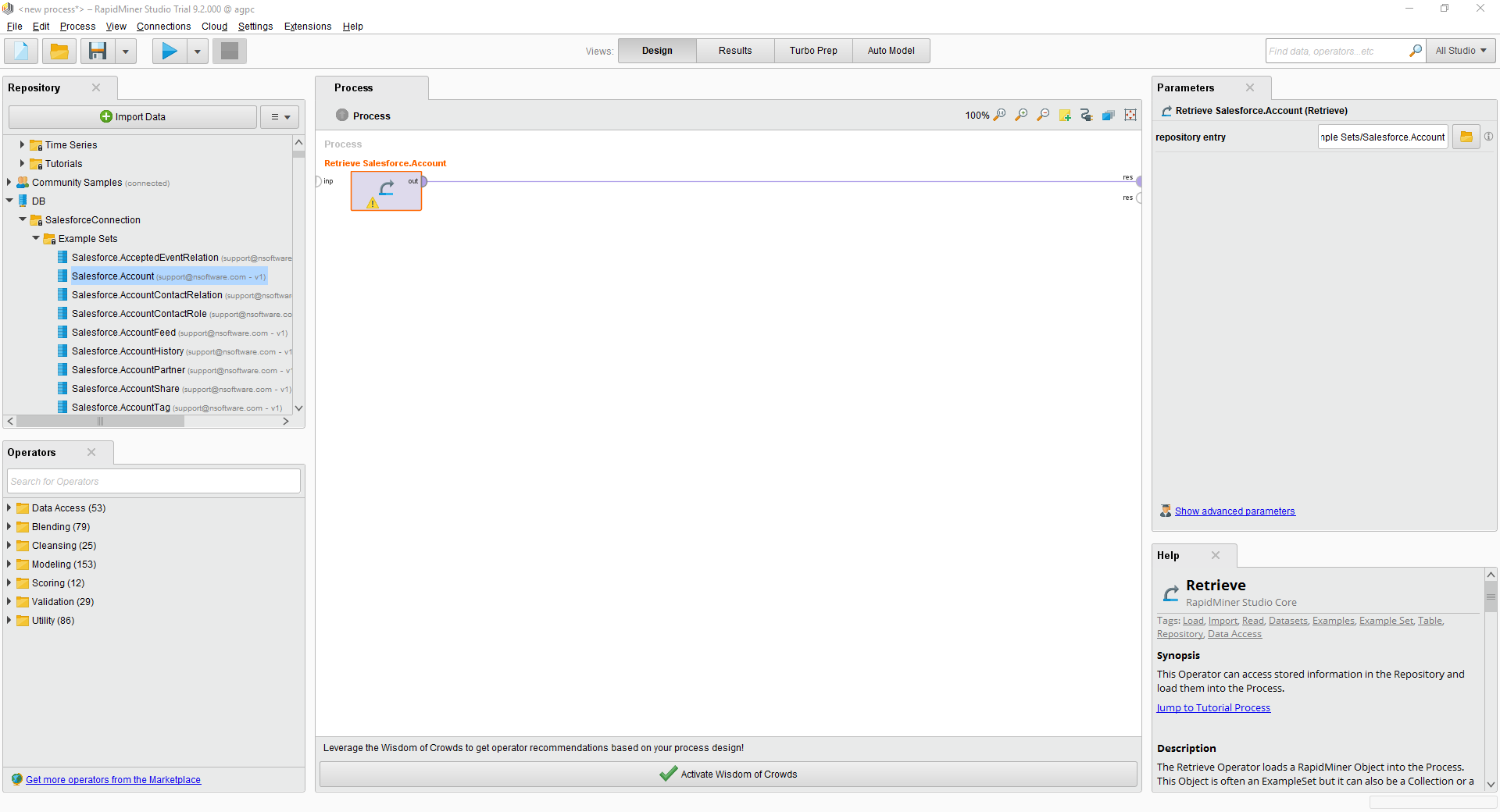
プロセス内の様々なRapidMiner オペレーターとのSpark 接続を使用できます。Spark を取得するには、[Operators]ビューから[Retrieve]をドラッグします。
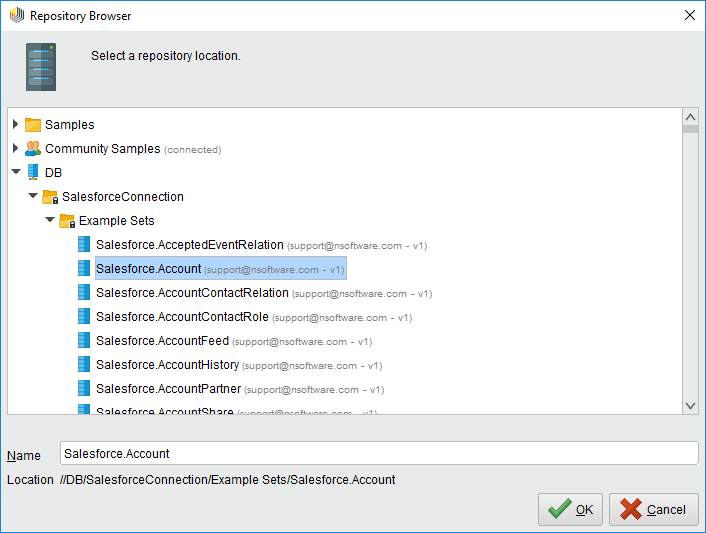 [Retrieve]オペレータを選択した状態で、[repository entry]の横にあるフォルダアイコンをクリックして[Parameters]ビューで取得するテーブルを定義できます。表示されるRepository ブラウザで接続ノードを展開し、目的のサンプルセットを選択できます。
[Retrieve]オペレータを選択した状態で、[repository entry]の横にあるフォルダアイコンをクリックして[Parameters]ビューで取得するテーブルを定義できます。表示されるRepository ブラウザで接続ノードを展開し、目的のサンプルセットを選択できます。
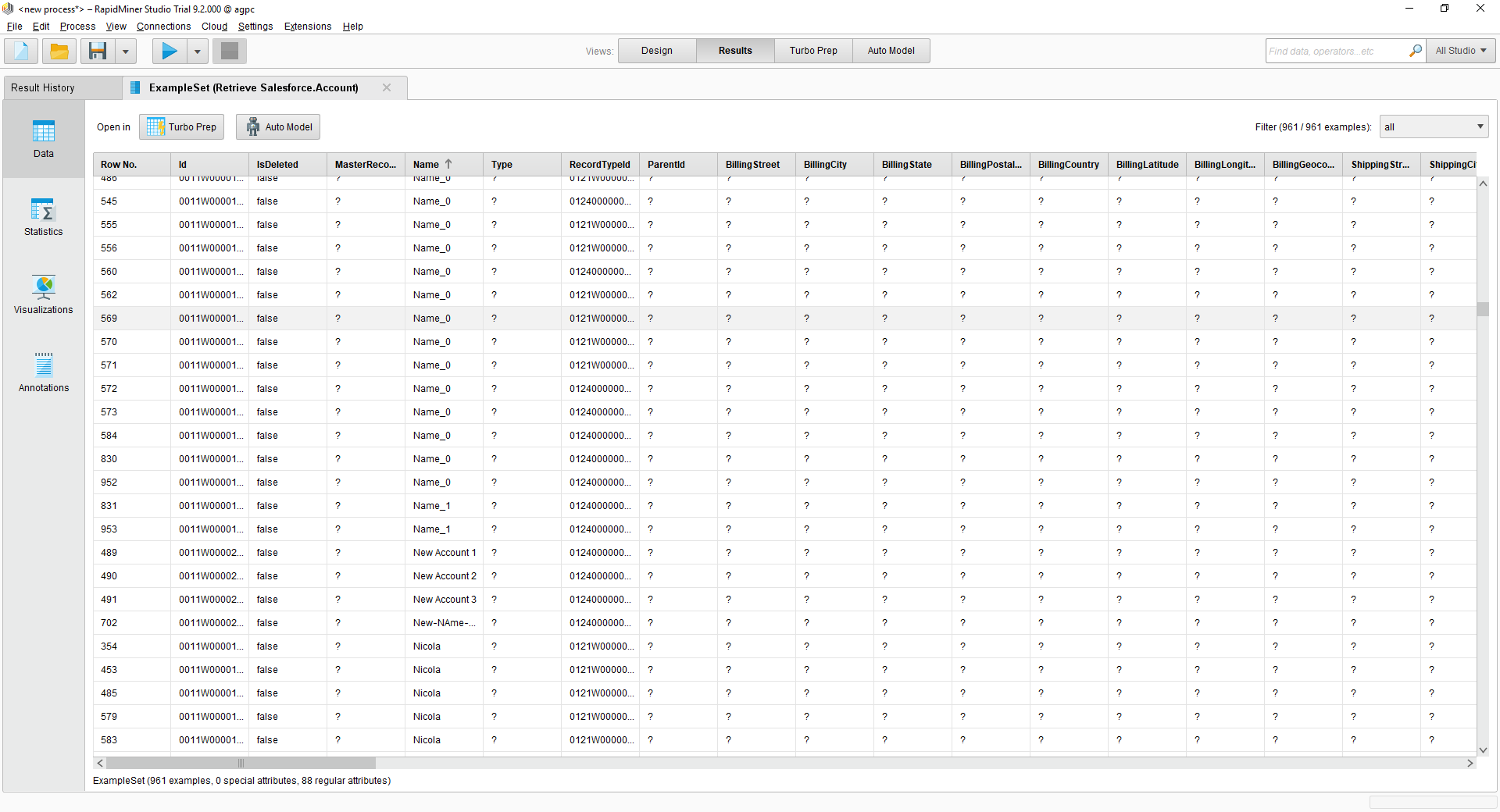
最後に、[Retrieve]プロセスから結果に出力をワイヤリングし、プロセスを実行してSpark を確認します。