ノーコードでクラウド上のデータとの連携を実現。
詳細はこちら →Apache Spark Driver の30日間無償トライアルをダウンロード
30日間の無償トライアルへこんにちは!ドライバー周りのヘルプドキュメントを担当している古川です。
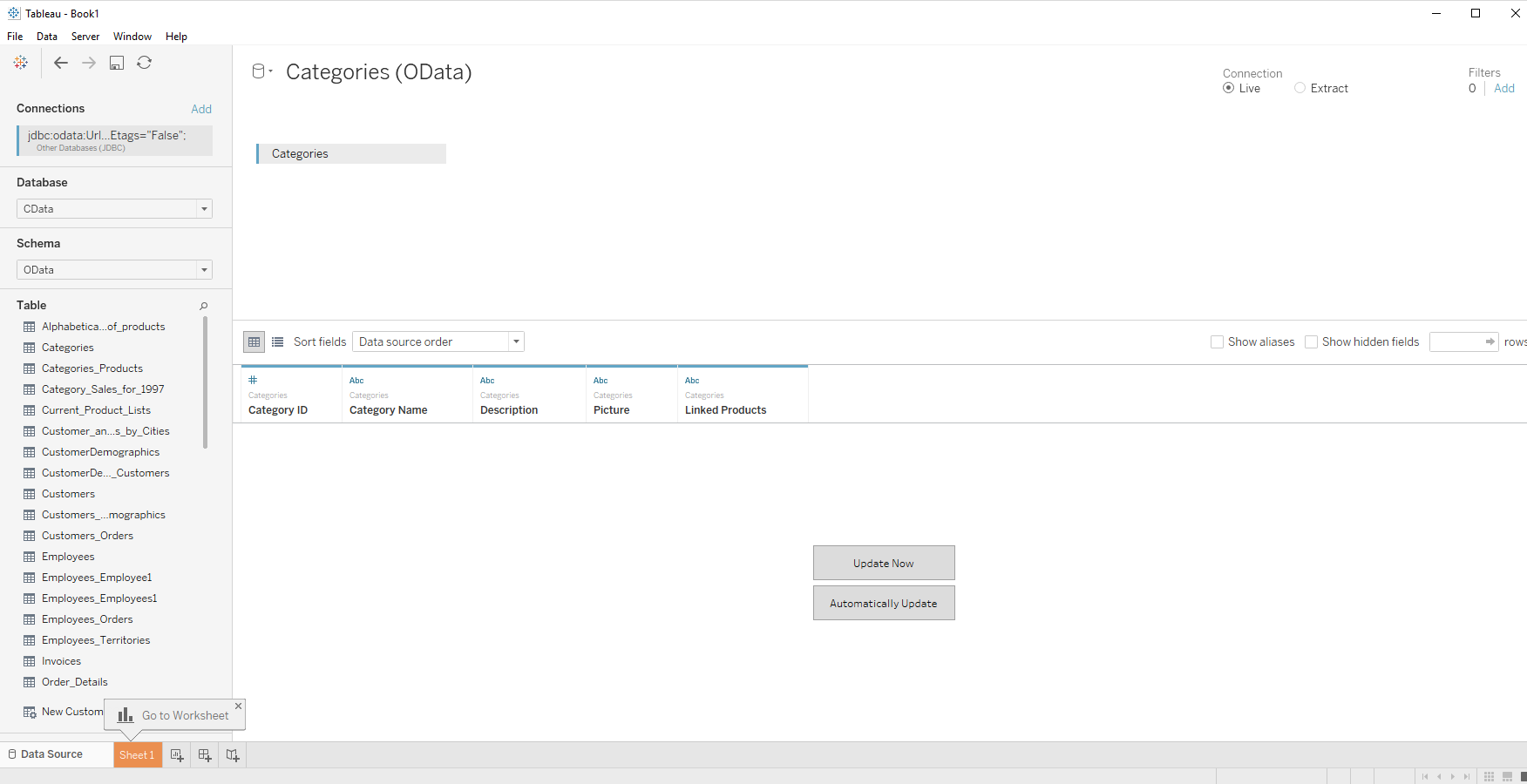
CData Driver for SparkSQL を使って、BI・ビジュアライズツールのTableau からSpark データをノーコードで連携して利用できます。この記事では、CData JDBC Driver for SparkSQL を使います。JDBC は、Windows 版のTabelau でもMac 版のTableau でも同じように利用できます。
Tableau での操作の前に.jar ファイルを以下のパスに格納します:
.jar ファイルを配置したら、Spark への接続を設定します。
SparkSQL への接続を確立するには以下を指定します。
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。Note:必要な値は、「クラスター」に移動して目的のクラスターを選択し、 「Advanced Options」の下にある「JDBC/ODBC」タブを選択することで、Databricks インスタンスで見つけることができます。
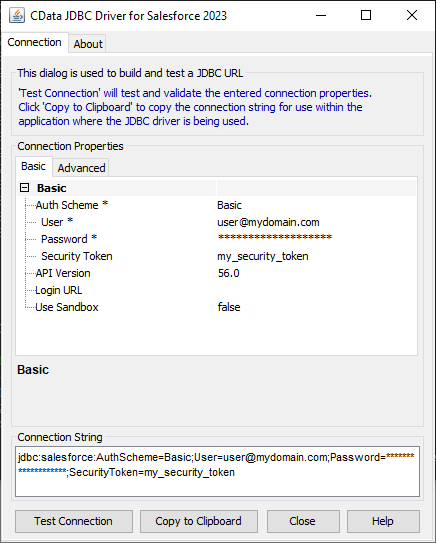
JDBC 接続文字列を作るには、Spark JDBC Driver のビルトイン接続文字列デザイナーを使う方法があります。ドライバーの.jar ファイルをダブルクリックするか、コマンドラインから.jar ファイルを実行します。
Windows:
java -jar 'C:\Program Files\CData\CData JDBC Driver for SparkSQL 2019\lib\cdata.jdbc.sparksql.jar'
MacOS:
java -jar cdata.jdbc.sparksql.jar
接続プロパティに値を入力して、生成される接続文字列をクリップボードにコピーします。
JDBC URLを設定する際には、Max Rows プロパティを設定することをお勧めします。これにより取得される行数が制限され、パフォーマンスを向上させます。
デザイナーで生成されるJDBC URL のサンプル:
jdbc:sparksql:Server=127.0.0.1;
CData JDBC Driver for SparkSQL をTabelau で使うことで、ノーコードでSpark データをビジュアライズできました。ぜひ、30日の無償評価版 をお試しください。