ノーコードでクラウド上のデータとの連携を実現。
詳細はこちら →こんにちは!リードエンジニアの杉本です。
CData Mule Connector for SparkSQL は、Spark をMule アプリケーションから標準SQL でのread 、write。update、およびdelete 機能を可能にします。コネクタを使うことで、Mule アプリケーションでSpark のバックアップ、変換、レポートおよび分析を簡単に行えます。
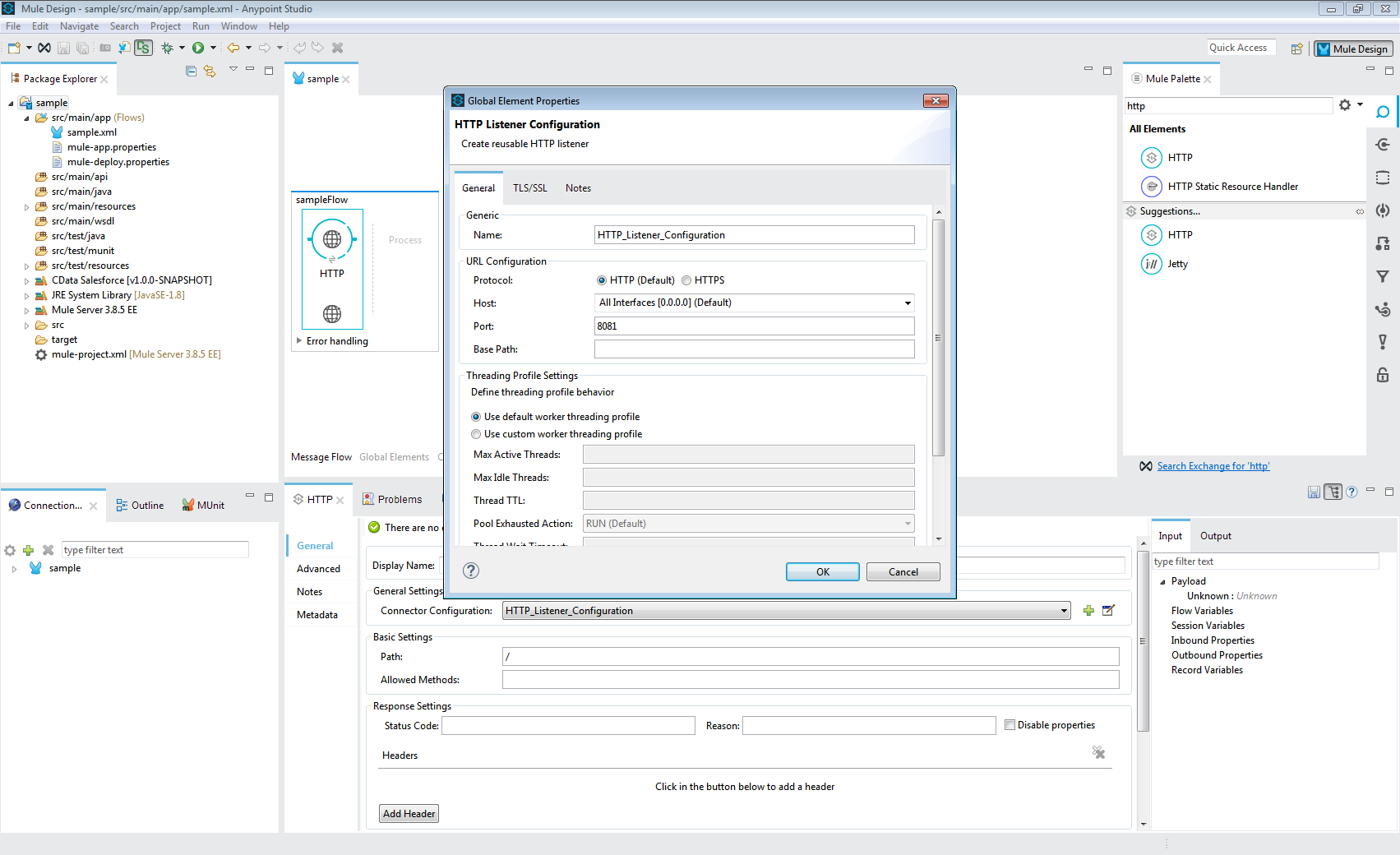
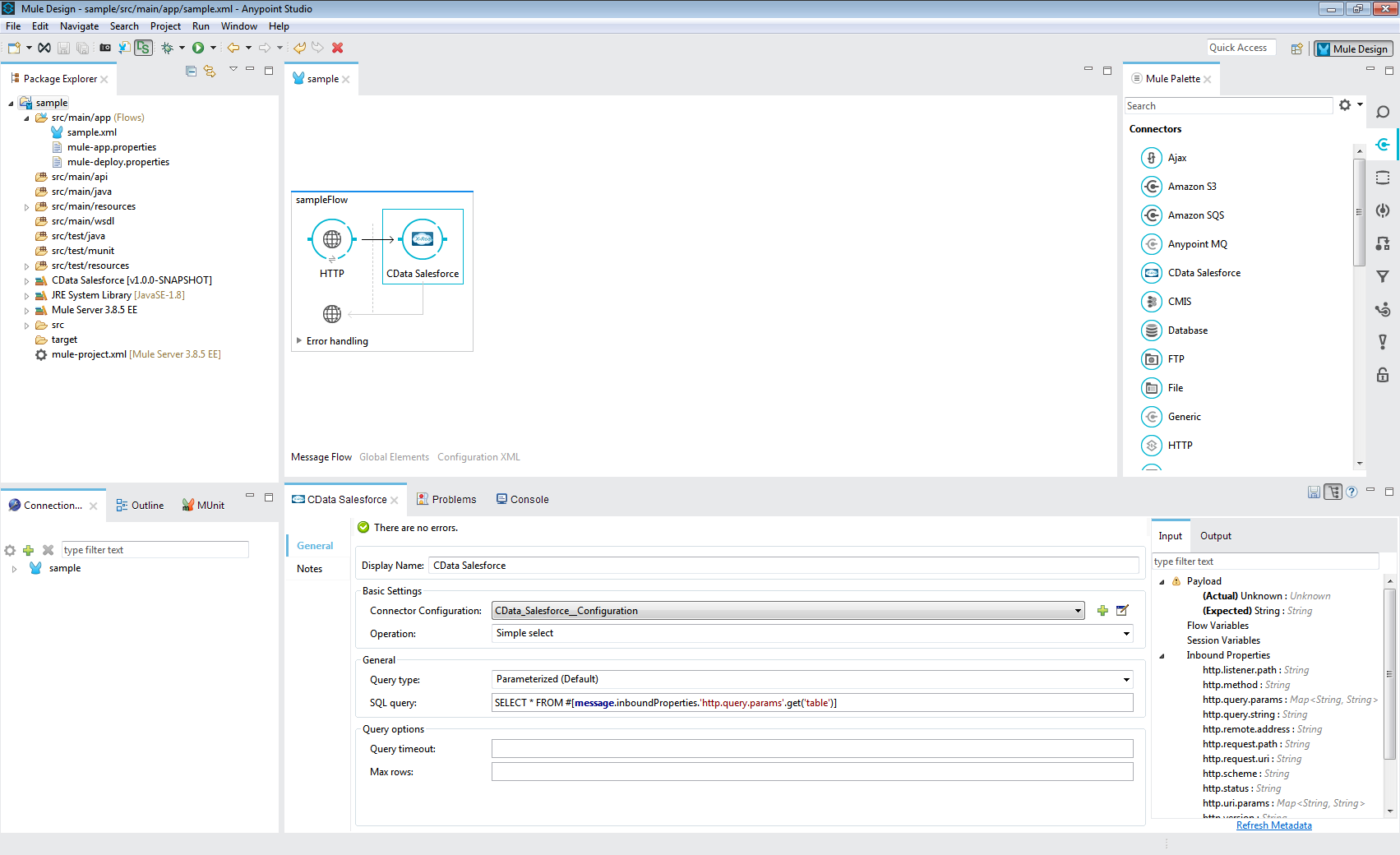
この記事では、Mule プロジェクト内のCData Mule Connector for SparkSQL を使用してSpark 用のWeb インターフェースを作成する方法を説明します。作成されたアプリケーションを使用すると、HTTP リクエストを使用してSpark をリクエストし、結果をJSON として返すことができます。以下のアウトラインと同じ手順を、CData Mule Connector で使用し、250+ の使用可能なWeb インターフェースを作成できます。
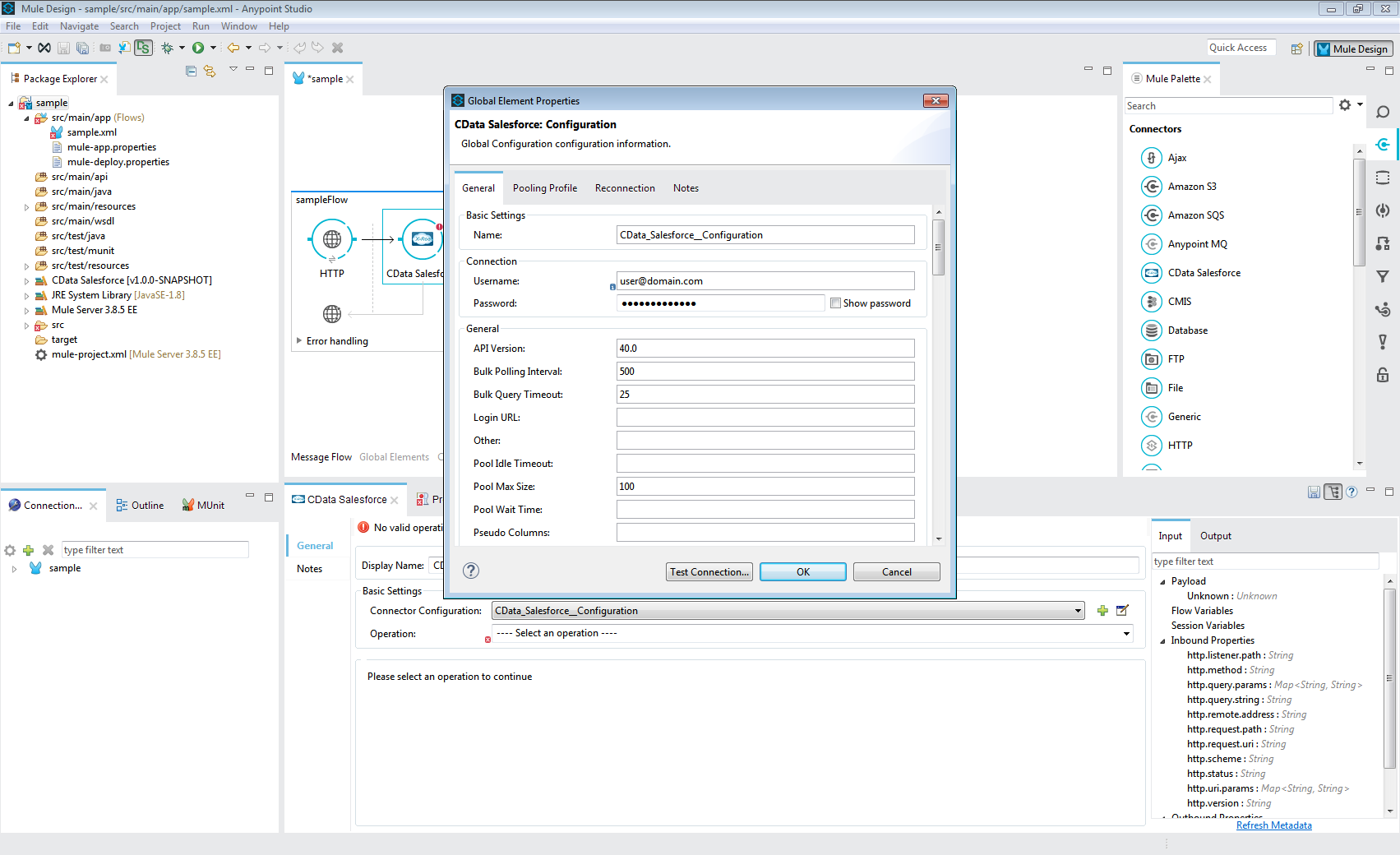
SparkSQL への接続を確立するには以下を指定します。
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。Note:必要な値は、「クラスター」に移動して目的のクラスターを選択し、 「Advanced Options」の下にある「JDBC/ODBC」タブを選択することで、Databricks インスタンスで見つけることができます。
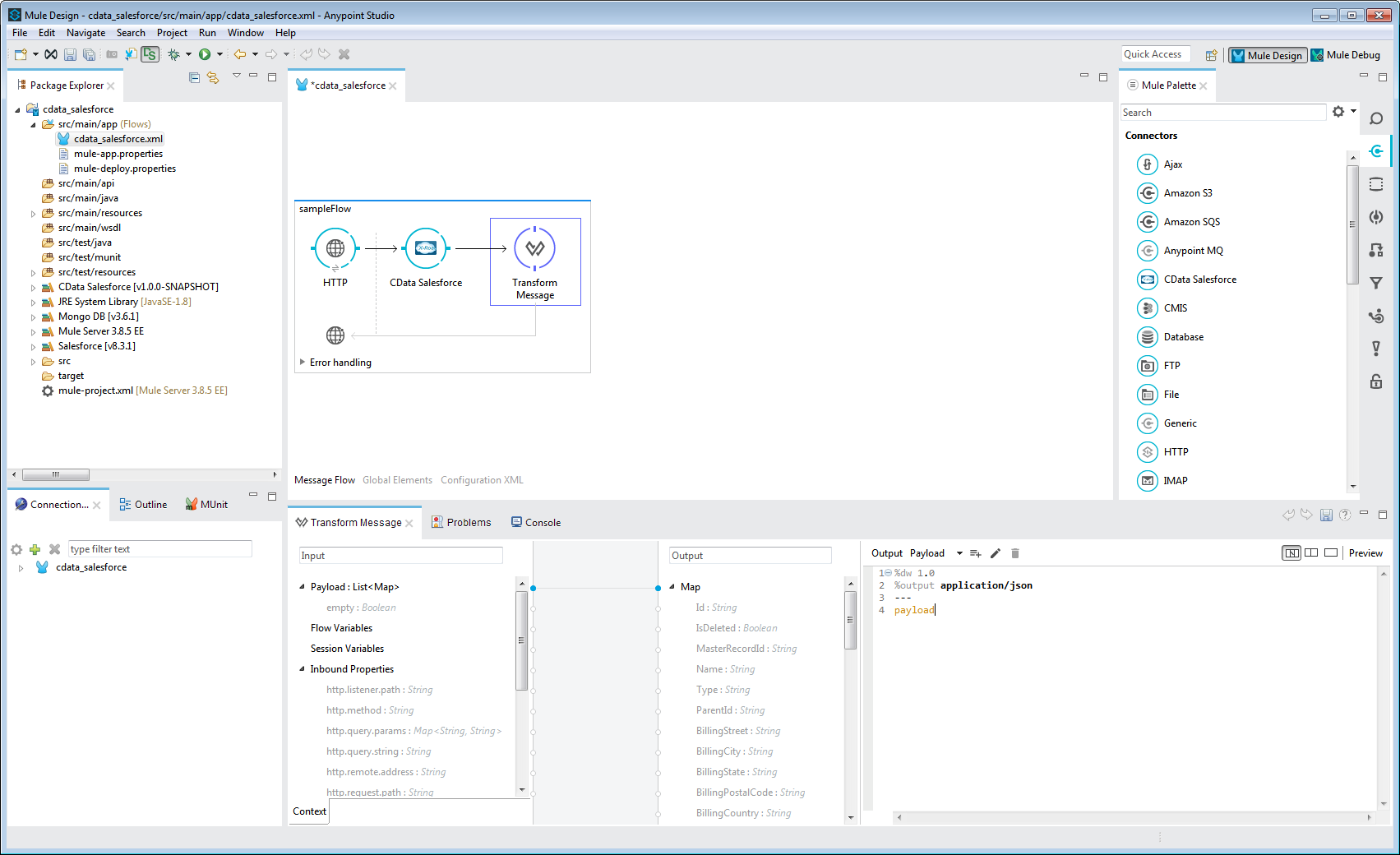
%dw 1.0
%output application/json
---
payload
カスタムアプリでSpark をJSON データとして操作するためのシンプルなWeb インターフェースと、様々なBI、レポート、およびETL ツールが完成しました。Mule Connector for SparkSQL の30日間無料トライアルをダウンロードして今すぐMule Applications でCData の違いを確認してみてください。