ノーコードでクラウド上のデータとの連携を実現。
詳細はこちら →Apache Spark ODBC Driver の30日間無償トライアルをダウンロード
30日間の無償トライアルへ製品の詳細
Apache Spark ODBC Driver は、ODBC 接続をサポートするさまざまなアプリケーションからApache Spark データへの接続を実現するパワフルなツールです。
標準SQL とSpark SQL をマッピングして、SQL-92 で直接Apache Spark にアクセス。
CData


こんにちは!ドライバー周りのヘルプドキュメントを担当している兵藤です。
本記事では、SQL Server のTDS Remoting 機能を使ってSpark のリンクサーバーをセットアップする方法をご紹介します。リンクサーバーの利用には、CData ODBC ドライバに同梱されているSQL Gateway を使用します。 SQL Server のインターフェースでSpark への読み書き双方向のアクセスが可能になります。
まずは、本記事右側のサイドバーからSparkSQL ODBC Driver の無償トライアルをダウンロード・インストールしてください。ODBC ドライバーのインストール完了時にODBC DSN 設定画面が立ち上がります。または、Microsoft ODBC データソースアドミニストレーターを使ってDSN を作成および設定できます。
SparkSQL への接続を確立するには以下を指定します。
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。Note:必要な値は、「クラスター」に移動して目的のクラスターを選択し、 「Advanced Options」の下にある「JDBC/ODBC」タブを選択することで、Databricks インスタンスで見つけることができます。
CData ODBC ドライバにはSQL Gateway が同梱されています。このSQL Gateway に、Spark ODBC Driver をサービスとして設定します。
SQL Gateway 側でサービスの設定が終わったら、SQL Server 側でSpark サービスをリンクサーバーとして使う設定をしましょう。
これで、リンクサーバーの設定は終わりなので、「OK」を押して設定を保存します。
SSMS のオブジェクトエクスプローラーのリンクサーバー下にSpark のリンクサーバーが作成され、「テーブル」下にSpark のデータがアプリ単位でテーブルが生成されます。
新しいクエリを選択し、Spark データを取得してみます。
SELECT * from リンクサーバー名.CData Spark Source Sys(ODBC DSN 名).Spark.テーブル名
このように、API のリクエストではなく通常のSQL 構文でデータを扱うことが可能になっています
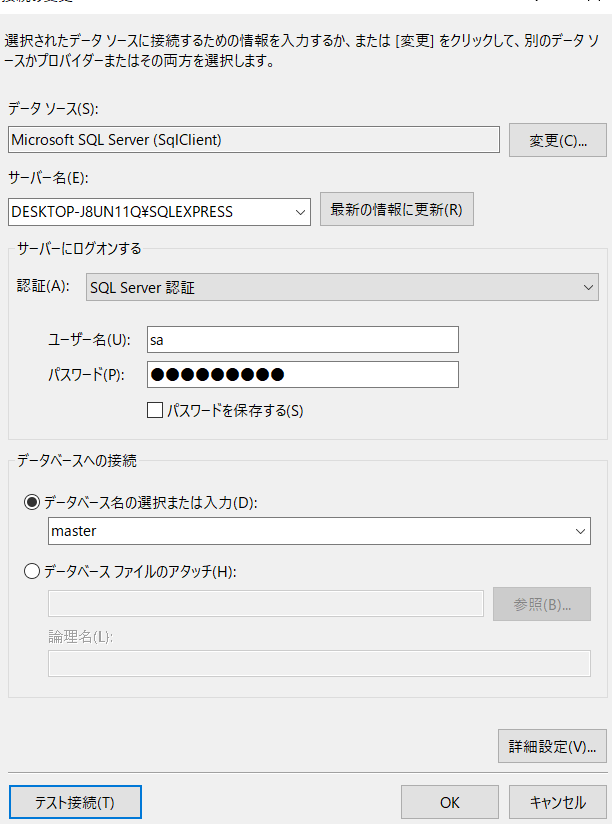
Visual Studio のサーバーエクスプローラーの「データ接続」を右クリックし、「接続の追加」をクリックして、データソースの選択画面を開きます。 データソースの選択画面でデータソースを「Microsoft SQL Server 」に選択して、「続行」を押します。
「接続の追加」画面で、以下を入力します。
サーバー名:SQL Server のサーバー名
認証:任意の認証方式
データベース名の選択または入力:※master など
※リンクサーバーを直接データベース名として入力することはできないようです。なので上位のデータベース名で設定しておきます。
「テスト接続」をして大丈夫であれば、「OK」を押して設定を完了させます。
「新しいクエリ」で、SQL でSELECT 文を書いてデータを取得してみます。
SELECT * from リンクサーバー名.CData Spark Source Sys(ODBC DSN 名).Spark.テーブル名
このように、通常のSQL Server のリンクサーバーと同じようにVisual Studio 内Spark データを扱うことが可能になります。
他のIDE でもSQL Server にアクセスする方法でSpark データにSQL でアクセスが可能になります。
複数データソースのJOIN などを行う場合には大変便利です。
このようにCData ODBC ドライバと併用することで、270を超えるSaaS、NoSQL データをSQL Server に連携できます。30日の無償評価版が利用できますので、ぜひ自社で使っているクラウドサービスやNoSQL と合わせて活用してみてください。