ノーコードでクラウド上のデータとの連携を実現。
詳細はこちら →Apache Spark Power BI Connector の30日間無償トライアルをダウンロード
30日間の無償トライアルへ製品の詳細
Power BI からApache Spark データにリアルタイムアクセスする認定コネクタ。ハイパフォーマンス、リアルタイム連携、高度なスキーマ自動検出、SQL -92 をサポート。
CData


こんにちは!ウェブ担当の加藤です。マーケ関連のデータ分析や整備もやっています。
CData Power BI Connectors は、セルフサービスBI であるMicrosoft Power BI のデータソースをSpark を含む270種類以上のSaaS / DB に拡充、分析や可視化を実現します。もちろん、ダッシュボードでSpark のデータをモニタリングしたり、定期更新やリアルタイムでのデータ更新も自在に可能。この記事では、Power BI Connector を使用してPower BI Desktop からSpark の可視化を作成する方法について詳しく説明します。
クラウド提供のPowerBI.com へのSpark レポートの発行(パブリッシュ)方法については、こちらの記事をご参照ください。
CData Power BI Connectors は、以下の特徴を持つPower BI とのリアルタイムデータ連携ソリューションです。
CData Power BI Connectors では、1.データソースとしてSpark の接続を設定、2.Power BI 側でコネクタとの接続を設定、という2ステップだけでデータソースに接続できます。以下に具体的な設定手順を説明します。
まずは、本記事右側のサイドバーからSparkSQL Power BI Connector の無償トライアルをダウンロード・インストールしてください。30日間無料で製品版の全機能が使用できます。
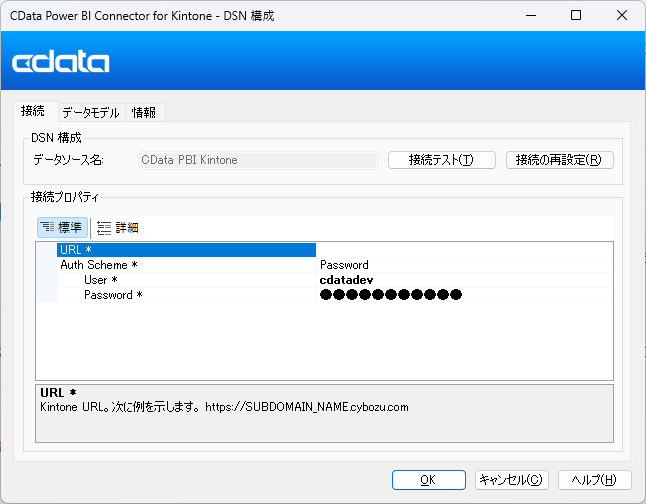
CData Power BI Connector をインストールすると完了後にDSN 設定画面が開きます。ここでSpark への接続を設定します。もしDSN 設定画面が開かない場合は、手動で「ODBC データソース アドミニストレータ(DSN)」プログラムを開いてください。
DSN 内の「CData PBI SparkSQL」を選択します。DSN 設定画面で必要な資格情報を入力してSpark データに接続します。入力後に接続のテストを行い、OK をクリックすれば接続は完了です。埋め込みOAuth に対応したデータソースであれば、「接続テスト」をクリックするとログイン画面が立ち上がり、ログインを完了するだけで接続設定が完了します。簡単ですね!
SparkSQL への接続を確立するには以下を指定します。
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。Note:必要な値は、「クラスター」に移動して目的のクラスターを選択し、 「Advanced Options」の下にある「JDBC/ODBC」タブを選択することで、Databricks インスタンスで見つけることができます。
これで、Spark データをPower BI に連携するための準備は完了です!いよいよPower BI からSpark データを取得していきます。
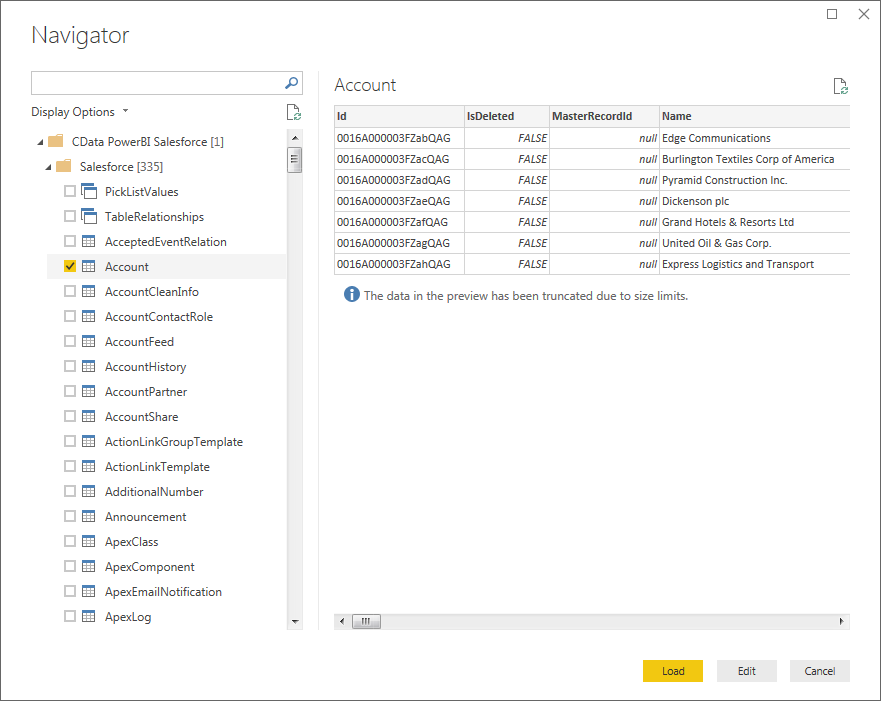
それでは、実際にPower BI からSpark データを取得してみましょう。
Power BI は、コネクタが取得・検出したSpark のカラム毎のデータ型をそのまま使えます。データ変換を取得して、指定した条件でクエリを発行し、Spark からデータを取得します。
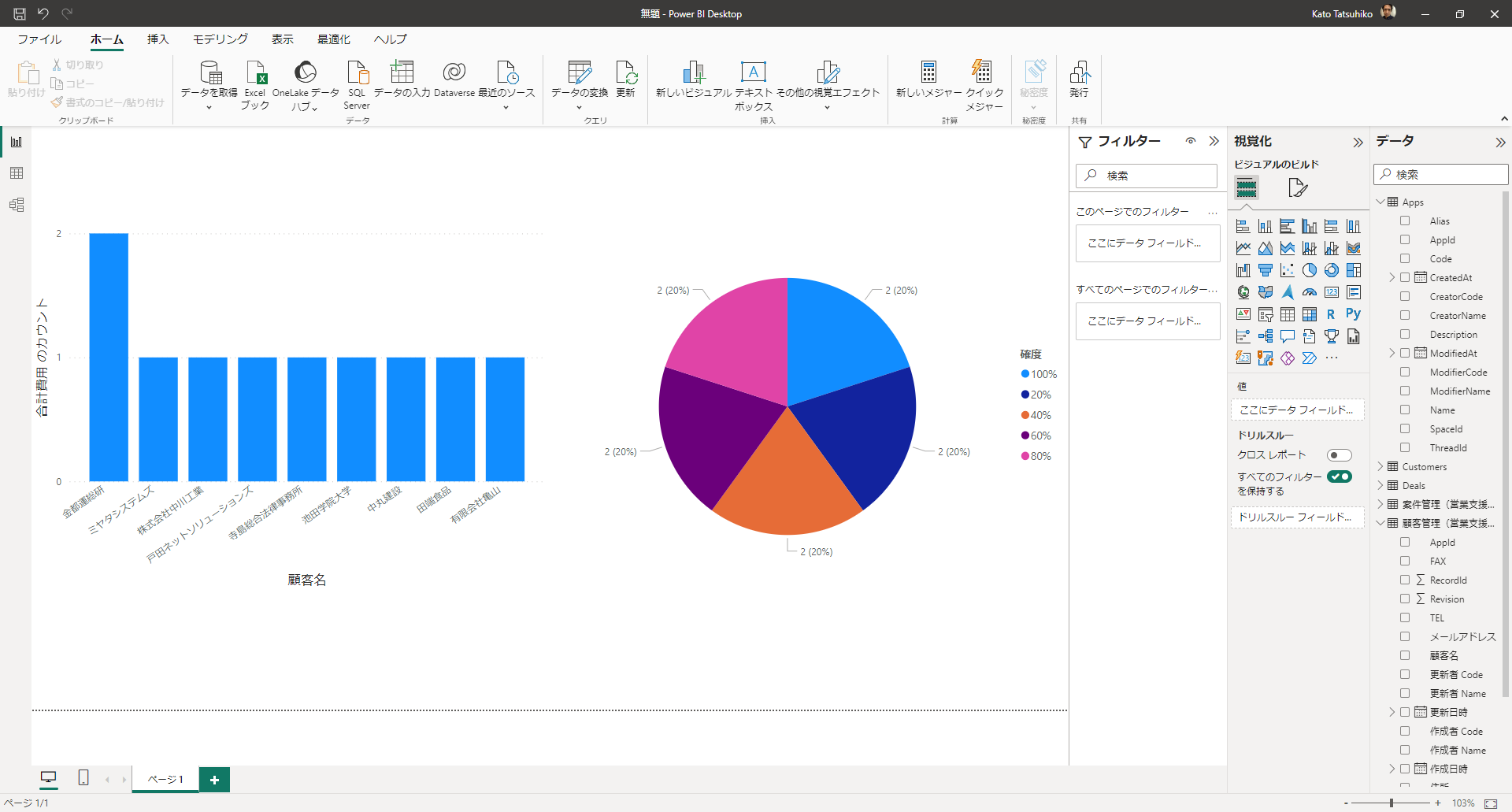
データをPower BI で取得したら、いよいよ可視化に活用できます!レポートビューで取得したSpark フィールドをドラッグ&ドロップして可視化を作成していきましょう。グラフの種類を可視化ペインから選択し、フィールドのカラムをドラッグして設定します。
「更新」をクリックすると、その時点でのリアルタイムデータをSpark から取得してレポートに反映させることができます。
これで、Spark データのPower BI での可視化ができました!あとは可視化を追加したり、フィルタリングや集計、データ変換などPower BI のパワフルな機能を活用して分析、レポーティング、ダッシュボード構築などさまざまな用途で利用できます。
本記事で紹介したようにCData Power BI Connectors と併用することで、270を超えるSaaS、NoSQL、DB のデータをコーディングなしで扱うことができます。30日の無償評価版が利用できますので、ぜひ自社で使っているクラウドサービスやNoSQL と合わせて活用してみてください。
CData Power BI Connector は日本のユーザー向けに、UI の日本語化、ドキュメントの日本語化、日本語でのテクニカルサポートを提供しています。製品の使用方法、購入方法などについてご質問がありました、お気軽にお問い合わせください。