ノーコードでクラウド上のデータとの連携を実現。
詳細はこちら →Apache Spark ODBC Driver の30日間無償トライアルをダウンロード
30日間の無償トライアルへ製品の詳細
Apache Spark ODBC Driver は、ODBC 接続をサポートするさまざまなアプリケーションからApache Spark データへの接続を実現するパワフルなツールです。
標準SQL とSpark SQL をマッピングして、SQL-92 で直接Apache Spark にアクセス。
CData


こんにちは!ドライバー周りのヘルプドキュメントを担当している古川です。
SAS は、高度なアナリティクス、多変量解析、BI、データ管理、予測分析のためのソフトウェアです。SAS とCData ODBC Driver for SparkSQL を合わせて使うことで、SAS からリアルタイムSpark データへデータベースライクにアクセスできるようになり、レポーティング、分析能力を向上できます。本記事では、SAS でSpark のライブラリを作成し、リアルタイムSpark に基づいたシンプルなレポートを作成します。
CData ODBC ドライバーは、ドライバーに組み込まれた最適化されたデータ処理により、SAS でリアルタイムSpark データを送受信する場合に圧倒的なパフォーマンスを提供します。SAS からSpark に複雑なSQL クエリを発行すると、ドライバーはフィルタや集計などのサポートされているSQL 操作をSpark に直接プッシュし、組み込みSQL エンジンを利用して、サポートされていない操作(一般的にはSQL 関数とJOIN 操作)をクライアント側で処理します。組み込みの動的メタデータクエリを使用すると、SAS でSpark を簡単にビジュアライズおよび分析できます。
CData ODBC ドライバは、以下のような特徴を持ったリアルタイムデータ連携ソリューションです。
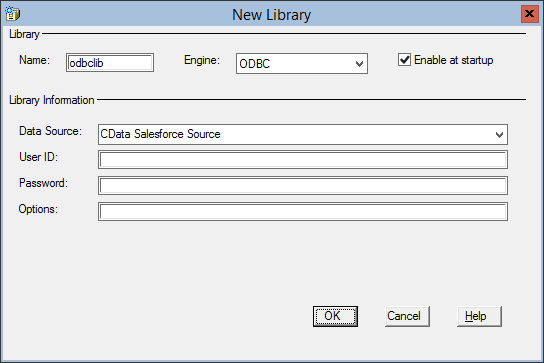
CData ODBC ドライバでは、1.データソースとしてSpark の接続を設定、2.SAS 側でODBC Driver との接続を設定、という2つのステップだけでデータソースに接続できます。以下に具体的な設定手順を説明します。
まずは、本記事右側のサイドバーからSparkSQL ODBC Driver の無償トライアルをダウンロード・インストールしてください。30日間無償で、製品版の全機能が使用できます。
以下は、Spark に接続するための情報と、Windows およびLinux 環境でDSN を構成するためのステップです。
SparkSQL への接続を確立するには以下を指定します。
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。Note:必要な値は、「クラスター」に移動して目的のクラスターを選択し、 「Advanced Options」の下にある「JDBC/ODBC」タブを選択することで、Databricks インスタンスで見つけることができます。
DSN を構成する際に、Max Rows プロパティを定めることも可能です。これによって返される行数を制限するため、ビジュアライゼーション・レポートのデザイン時のパフォーマンスを向上させるのに役立ちます。
未指定の場合は、初めにODBC DSN(data source name)で接続プロパティを指定します。ドライバーのインストールの最後にアドミニストレーターが開きます。Microsoft ODBC Data Source Administrator を使用して、ODBC DSN を作成および構成できます。
Linux 環境にCData ODBC Driver for SparkSQL をインストールする場合、ドライバーのインストールによりシステムDSN が事前定義されます。システムデータソースファイル(/etc/odbc.ini) を編集し、必要な接続プロパティを定義することで、DSN を変更できます。
[CData SparkSQL Sys]
Driver = CData ODBC Driver for SparkSQL
Description = My Description
Server = 127.0.0.1
これらの構成ファイルの使用に関する具体的な情報については、ヘルプドキュメントを参照してください。
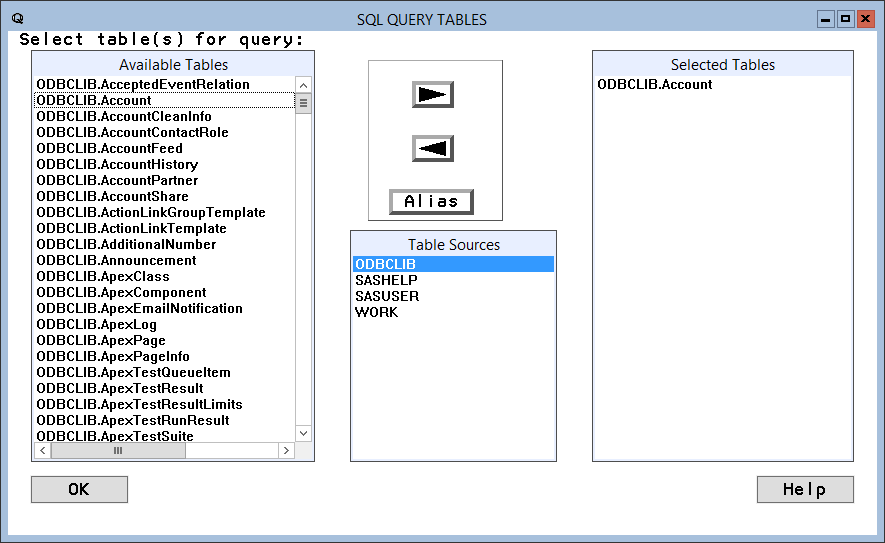
CData ODBC Driver for SparkSQL に基づくライブラリを追加することで、SAS でSpark に接続します。
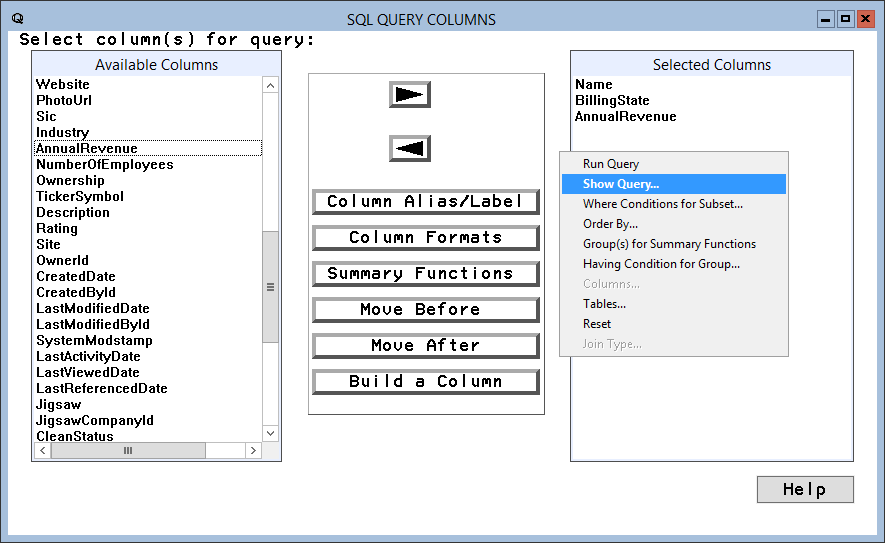
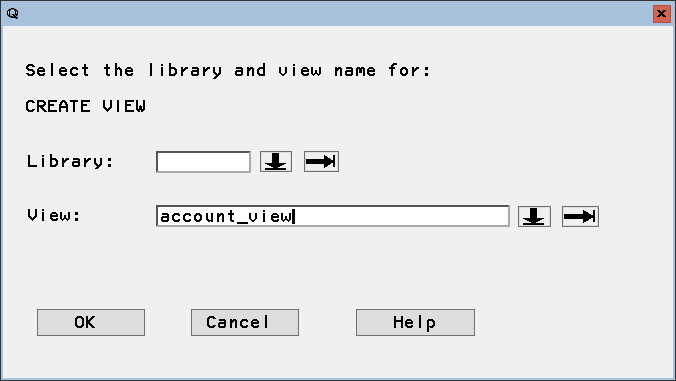
SAS は、ローコードのポイントアンドクリッククエリツールを使用するか、PROC SQL とカスタムSQL クエリのプログラムを使うことで、データのクエリをネイティブにサポートします。SAS でビューを作成すると、ビューがクエリされるたびに定義クエリが実行されます。これは、レポート、チャート、分析について常にリアルタイムSpark データにクエリを実行することを意味します。
proc sql;
create view customers_view as
select
city,
balance
from
odbclib.customers
where
Country = 'US';
quit;
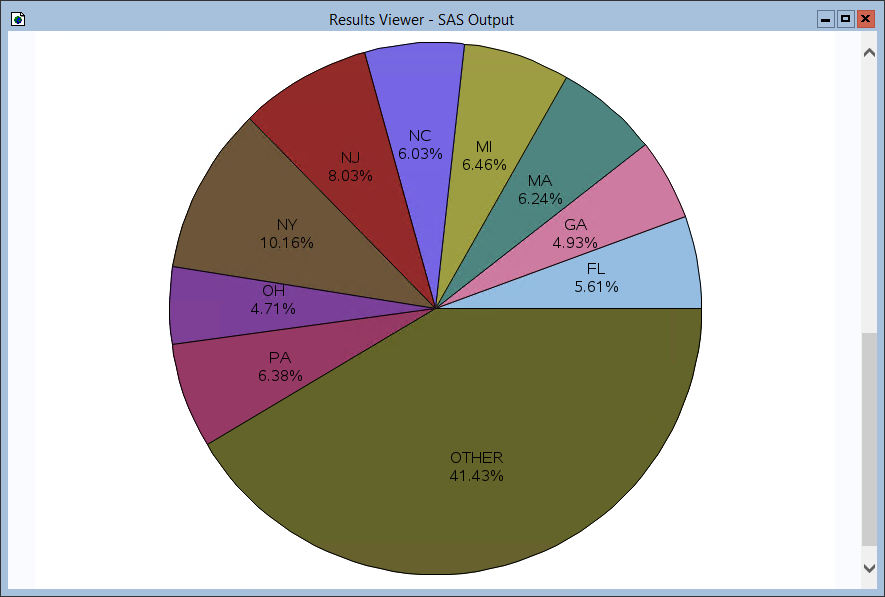
ローカルビューを作成すると、パワフルなSAS 機能を使用してSpark データをレポート、ビジュアライズ、またはその他の方法で分析できます。PROC PRINT を使用して簡単なレポートを印刷し、PROC GCHART を使用してデータに基づいた基本的なグラフを作成しましょう。
proc print data=customers; title "Spark Customers Data"; run;
proc gchart data=customers;
pie city / sumvar=balance
value=arrow
percent=arrow
noheading
percent=inside plabel=(height=12pt)
slice=inside value=none
name='CustomersChart';
run;
このようにCData ODBC ドライバと併用することで、270を超えるSaaS、NoSQL データをコーディングなしで扱うことができます。30日の無償評価版が利用できますので、ぜひ自社で使っているクラウドサービスやNoSQL と合わせて活用してみてください。
CData ODBC ドライバは日本のユーザー向けに、UI の日本語化、ドキュメントの日本語化、日本語でのテクニカルサポートを提供しています。