ノーコードでクラウド上のデータとの連携を実現。
詳細はこちら →Apache Spark Power BI Connector の30日間無償トライアルをダウンロード
30日間の無償トライアルへ製品の詳細
Power BI からApache Spark データにリアルタイムアクセスする認定コネクタ。ハイパフォーマンス、リアルタイム連携、高度なスキーマ自動検出、SQL -92 をサポート。
CData


こんにちは!ウェブ担当の加藤です。マーケ関連のデータ分析や整備もやっています。
Power Apps はMicrosoft のローコードアプリ開発ツールです。Power Apps には、Power Apps 上で使えるデータベースライクなDataverse(旧CDS)というサービスがあるのですが、このサービスに連携するためのデータフローというデータインテグレーション機能が存在します。
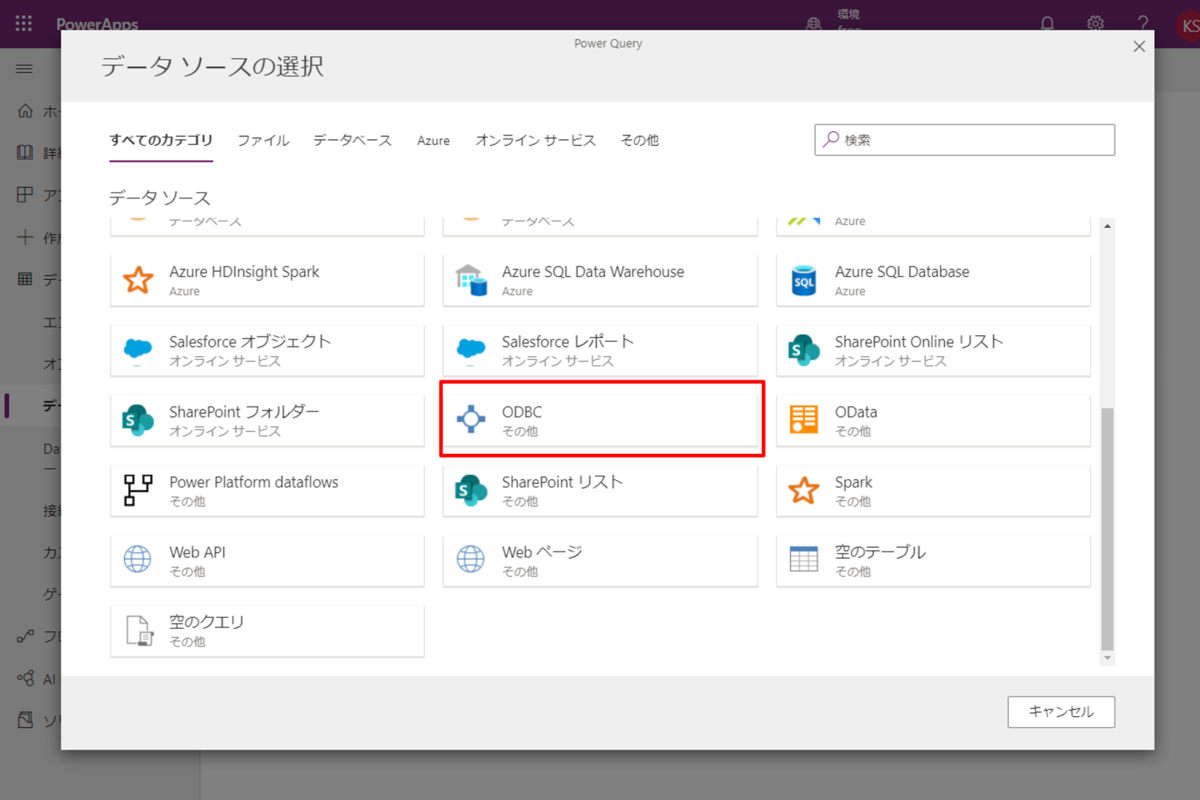
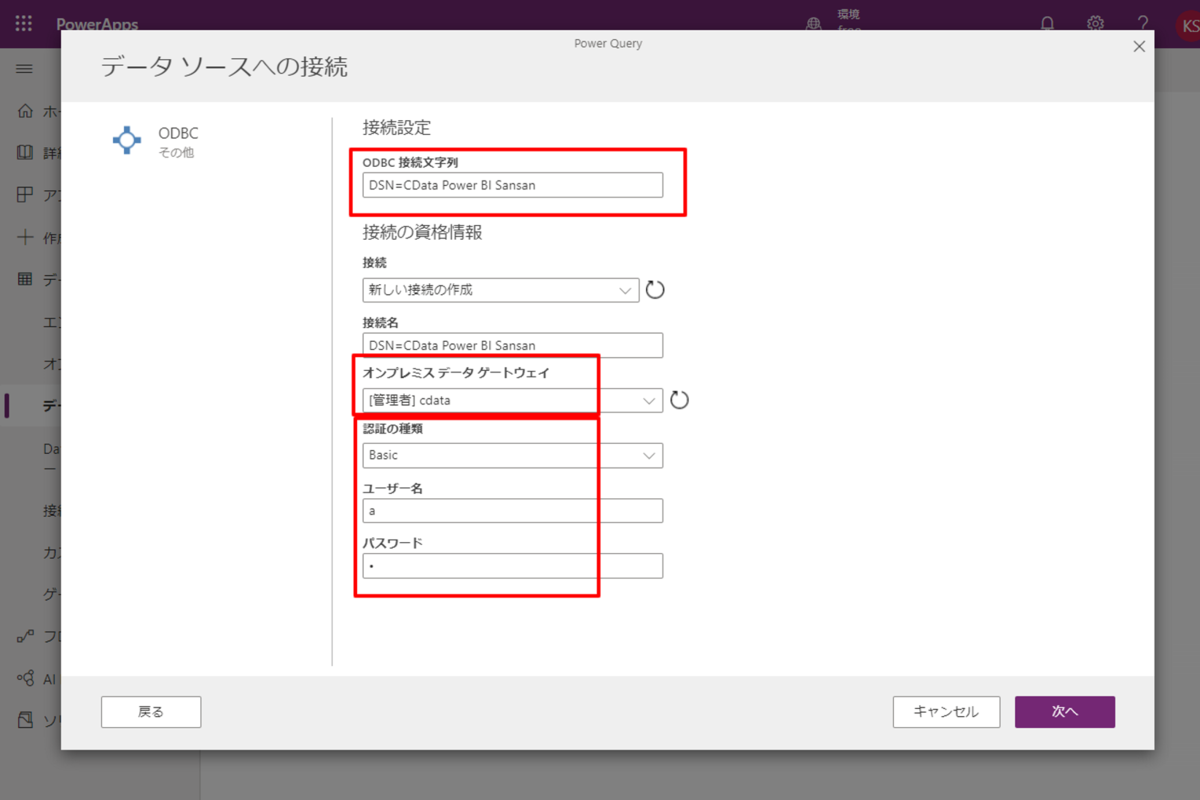
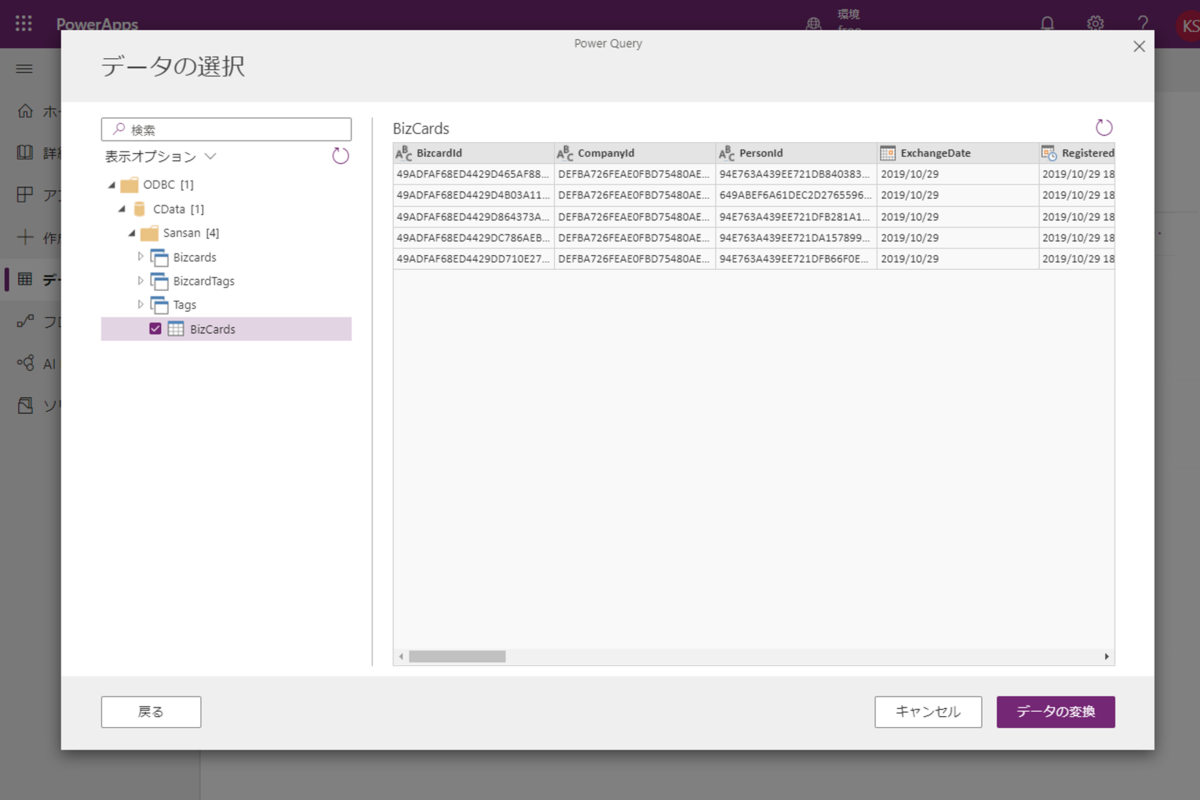
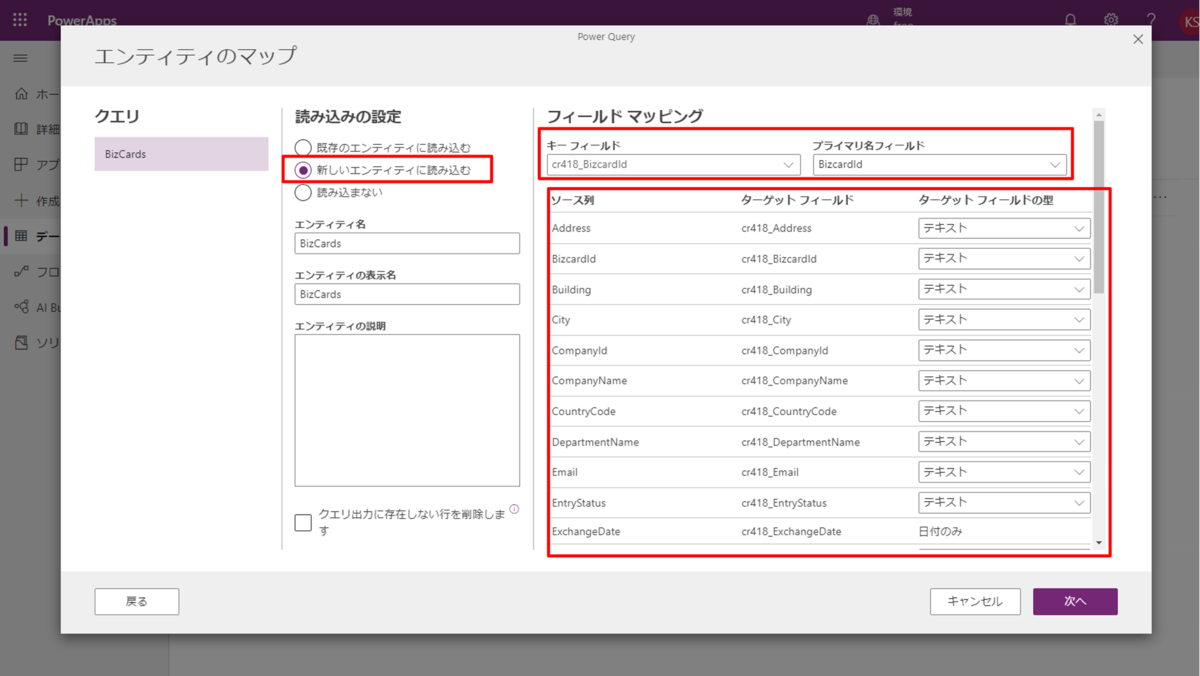
Access やSharePoint リストを元に、Dataverse のエンティティ(テーブルのようなもの)を自動生成し、定期的にデータを同期させてくれるという便利な機能です!デフォルトでも30種類くらいのサービスに接続できるようになっているのですが、CData のPower BI Connectors と組み合わせればSpark を含む270種類以上のデータソースに接続できます。 ここでは、汎用ODBC データプロバイダーとしてSpark に接続し、Power Apps オンプレミスデータゲートウェイからSpark データを連携利用する手順を説明します。
まずは、右側のサイドバーからPower BI Connector for SparkSQL をダウンロードします。30日間無料で全機能が利用できるので、お気軽にご利用ください。インストールが完了すると、以下のように接続設定画面が表示されるので、 DSN を設定します。 DSN 設定の詳細については、ドキュメントを参照してください。
SparkSQL への接続を確立するには以下を指定します。
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。Note:必要な値は、「クラスター」に移動して目的のクラスターを選択し、 「Advanced Options」の下にある「JDBC/ODBC」タブを選択することで、Databricks インスタンスで見つけることができます。
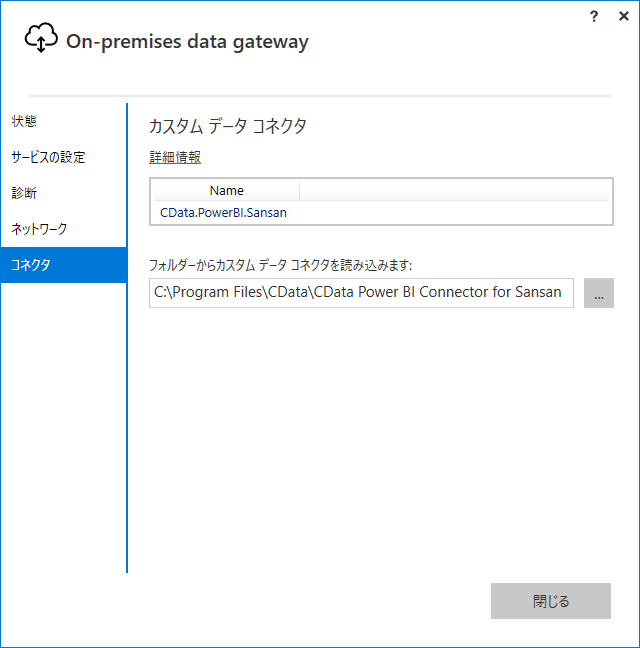
次にオンプレミスデータゲートウェイにインストールしたSpark コネクターを認識させます。もしデータゲートウェイのインストールがまだであれば、
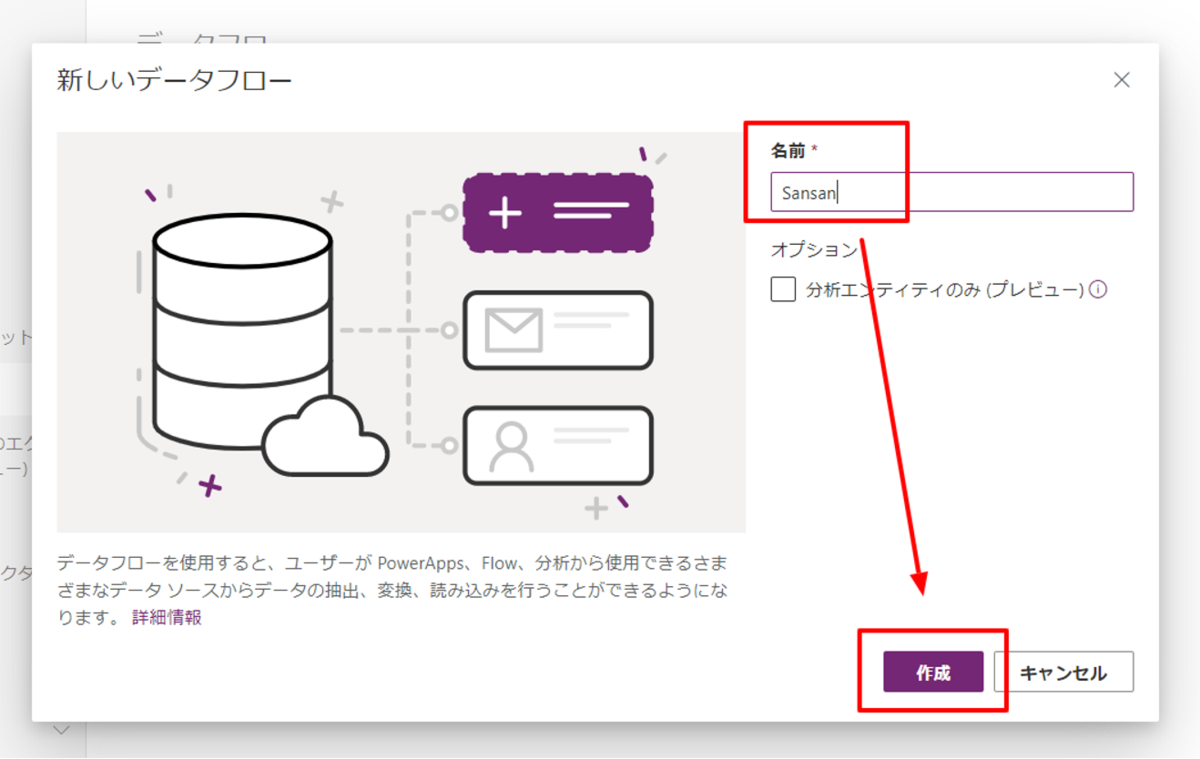
それでは Power Apps の画面に移動して、データフローを作成してみましょう。
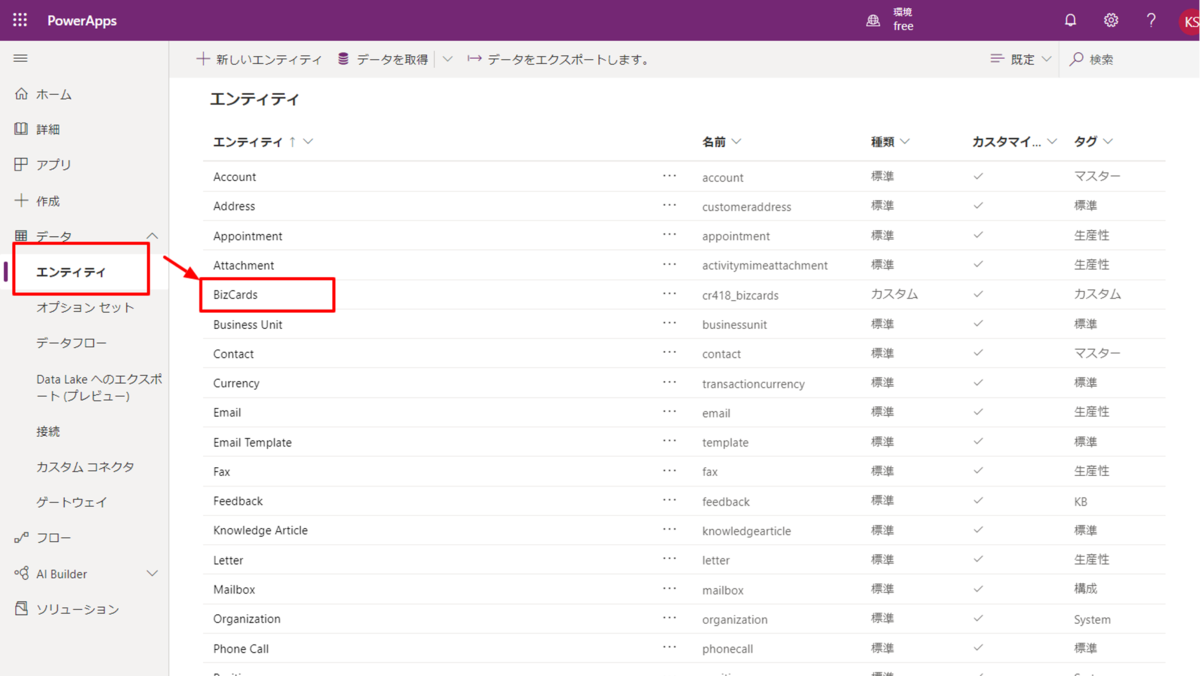
このように、Power Apps から簡単にSpark データに接続して利用することができました。CData のPower BI Connector は、Spark 以外にも270種類以上のデータソースに対応しています。30日間の無償トライアルがありますので、ぜひお試しください。