こんにちは!プロダクトスペシャリストの宮本です。
Google Cloud Data Fusion は、ノーコードでデータ連携の設定が可能な言わば GCP の ETL ツール(サービス)です。たくさんのコネクタや変換・分析機能がデフォルトで用意されているため、さまざまなデータソースを色々な組み合わせで扱うことが可能なようです。
また JDBC を扱うこともできるため、この記事では、CData JDBC Driver for IBM Cloud Object Storage データ を使って、IBM Cloud Object Storage データ データをCloud Data Fusion でGoogle BigQuery にノーコードでパイプラインします。
Cloud Data Fusion の準備
まずはCloud Data Fusion のインスタンスを作成します。
- Data Fusion のトップ画面にある「CREATE INSTANCE」からインスタンスを作成します。
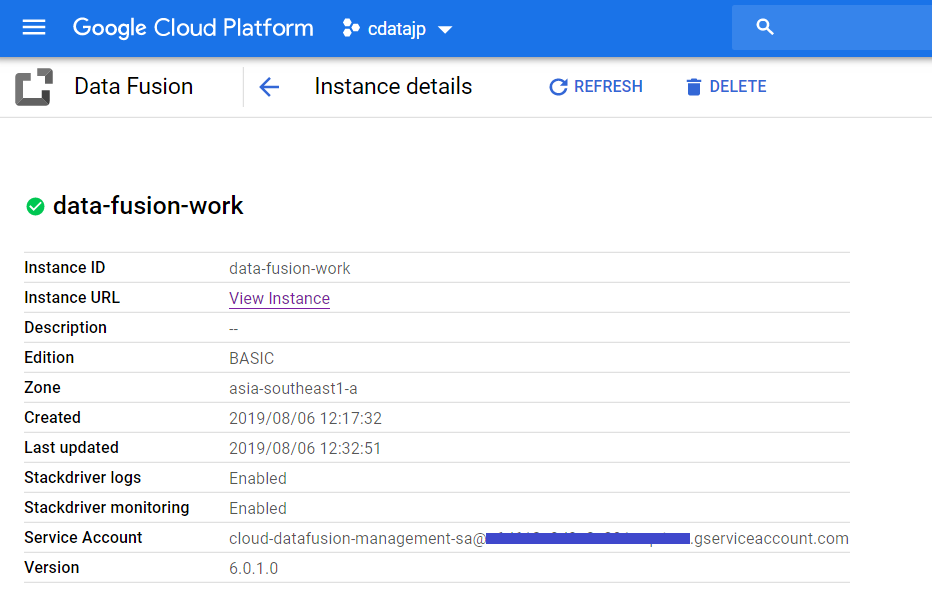
- 作成されたインスタンス名を先ほどの画面でクリックすると以下の画面に遷移しますので、画面下部にある Service Account をコピーします。
![Cloud Data Fusion のインスタンス作成]()
- 画面上部にある追加からメンバーを追加します。メンバー名は先ほどコピーした「Service Account」に合わせてください。
役割は BiqQuery へもアクセスしますので、「BigQuery 管理者」、「Cloud Data Fusion 管理者」、「Cloud Data Fusion API サービス エージェント」を付与します。
CData JDBC Driver for IBMCloudObjectStorage のアップロード
ここからは実際に、Data Fusion の設定をしていきます。
まずは JDBC Driver をアップロードを行います。
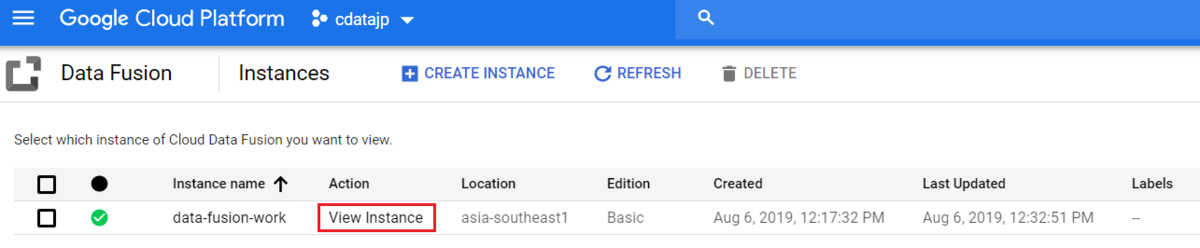
- 「View Instance」をクリックして、Data Fusion の Control Center を開きます。
![Cloud Data Fusion のControl Center を開く]()
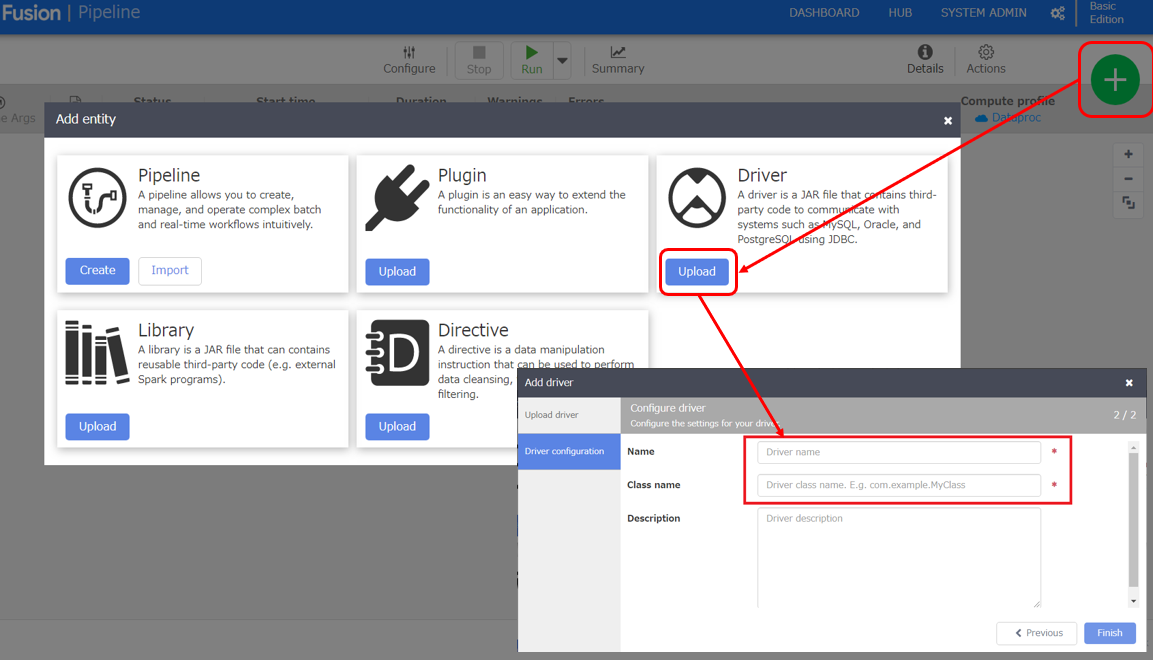
- Control Center が表示されたら、「+」ボタンをクリックして JDBC Driver をアップロードしていきます。
- Name:アップロードしたドライバーに設定する名前
- Class name:cdata.jdbc.ibmcloudobjectstorage.IBMCloudObjectStorageDriver
![JDBC Driver をCloud Data Fusion にアップロード]()
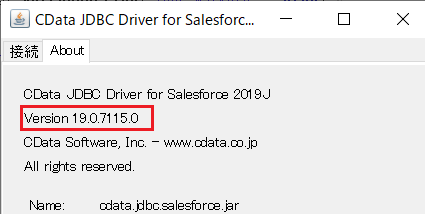
- アップロードする際の注意点として、Driver のファイル名を name-version の形式に変更してアップロードする必要があります。
なお、jarファイルをダブルクリックした際に表示されているバージョンをもとに「ibmcloudobjectstorage-connector-java-19.0.7115.0.jar」に変更しました。
![JDBC Driver をCloud Data Fusion にアップロード]()
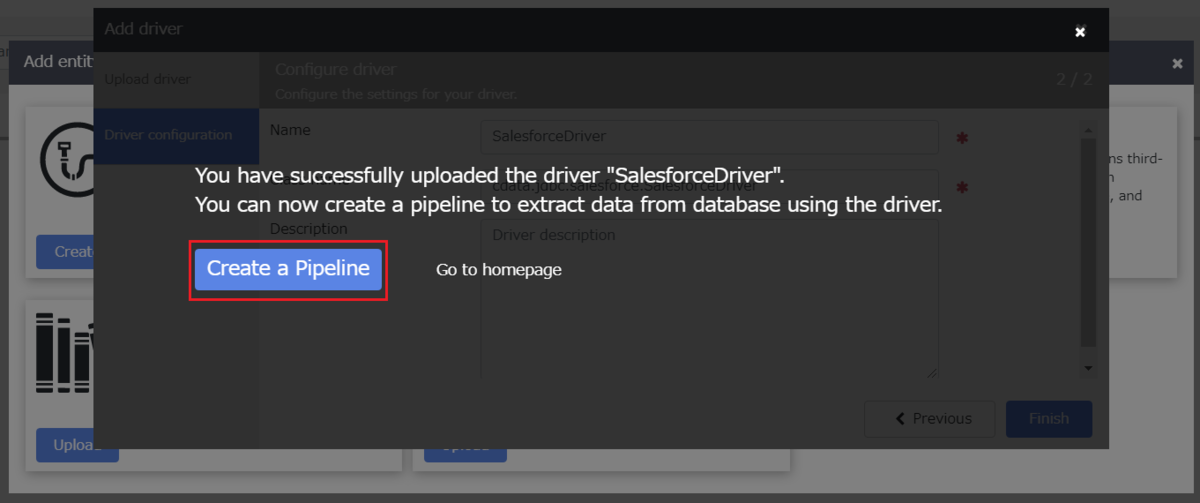
- アップロードが成功するとこのような画面が表示されるので、「Create a Pipeline」をクリックします。
![JDBC Driver のアップロード終了]()
IBM Cloud Object Storage からGoogle BigQuery へのパイプラインの作成
Data Fusion のパイプライン作成
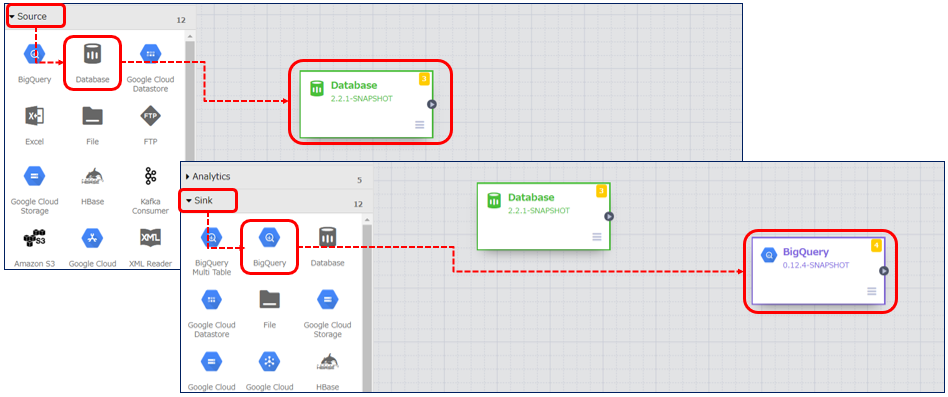
インプット元はサイドメニューの「Source」から選択します。今回は先ほどアップロードした IBM Cloud Object Storage データ の JDBC Driver を使用するため、「DataBase」を選択します。
アウトプット先は同じくサイドメニューより「Sink」→「BigQuery」を選択します。
![Source およびSink 先の選択]()
「DataBase」の設定
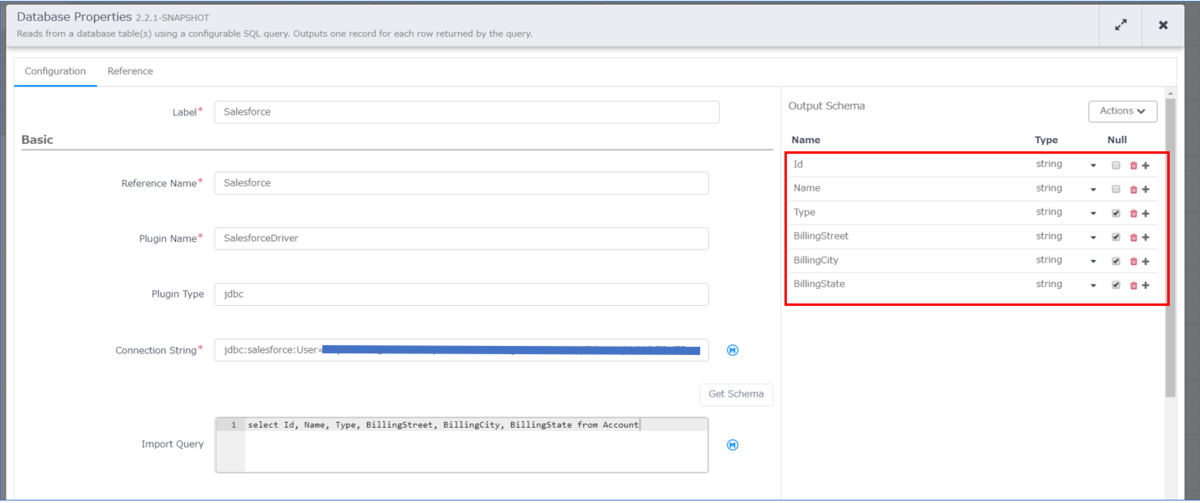
「DataBase」のアイコンにカーソルを持ってくるとプロパティというボタンが表示されるのでクリックし、下記内容を設定します。
- Label:IBMCloudObjectStorage
- Reference Name:IBMCloudObjectStorage
- Plugin Name:IBMCloudObjectStorage Driver(Driver をアップロードした際の名前)
- Plugin Type:jdbc
- Connection String:IBMCloudObjectStorage へ接続する際の JDBC URL
- Import Query:インプットしたいデータを抽出するクエリ
Cloud Object Storage 接続プロパティの取得・設定方法
Cloud Object Storage に接続する前に、Cloud Object Storage インスタンスを登録してCloud Object Storage API キーとCRN を取得していきます。
Cloud Object Storage の新規インスタンスの登録
IBM Cloud アカウントにCloud Object Storage がまだない場合は、以下の手順に従ってアカウントにSQL Query のインスタンスをインストールできます。
- IBM Cloud アカウントにログインします。
- Cloud Object Storage
ページに移動して、インスタンス名を指定して「作成」をクリックします。Cloud Object Storage の新規インスタンスにリダイレクトされます。
API キー
API キーは以下の手順で取得できます。
- まずは、IBM Cloud アカウントにログインします。
- API キーページに移動します。
- 中央右隅のIBM Cloud APIキーの作成 をクリックして、新しいAPI キーを作成します。
- ポップアップウィンドウが表示されたら、API キーの名前を指定して作成をクリックします。ダッシュボードからはアクセスできなくなるため、API Key を控えておきましょう。
Cloud Object Storage CRN
デフォルトでは、CData 製品はCloud Object Storage CRN を自動で取得します。ただし、複数のアカウントがある場合は、CloudObjectStorageCRN
を明示的に指定する必要があります。この値は、次の2つの方法で取得できます。
- Services ビューをクエリする。これにより、IBM Cloud Object Storage インスタンスとそれぞれのCRN がリストされます。
- IBM Cloud で直接CRN を見つける。これを行うには、IBM Cloud
のダッシュボードに移動します。リソースリストで、ストレージからCloud Object Storage リソースを選択してCRN
を取得します。
IBM Cloud Object Storage への接続
これで準備は完了です。以下の接続プロパティを設定してください。
- InitiateOAuth:GETANDREFRESH に設定。InitiateOAuth を使うと、OAuth
認証を繰り返す必要がなく、さらに自動でアクセストークンを設定できます。
- ApiKey:セットアップ中に控えたAPI キーを指定。
- CloudObjectStorageCRN(オプション):控えておいたCloud Object Storage のCRN に設定。Cloud Object
Storage アカウントが複数ある場合のみ設定する必要があります。
プロパティを設定したら、これで接続設定は完了です。
Connection String は以下の形式です。
jdbc:ibmcloudobjectstorage:ApiKey=myApiKey;CloudObjectStorageCRN=MyInstanceCRN;Region=myRegion;OAuthClientId=MyOAuthClientId;OAuthClientSecret=myOAuthClientSecret;
![Database プロパティ設定]()
上のキャプチャの赤枠は、Salesforce から BigQuery へアウトプットするデータの定義となります。
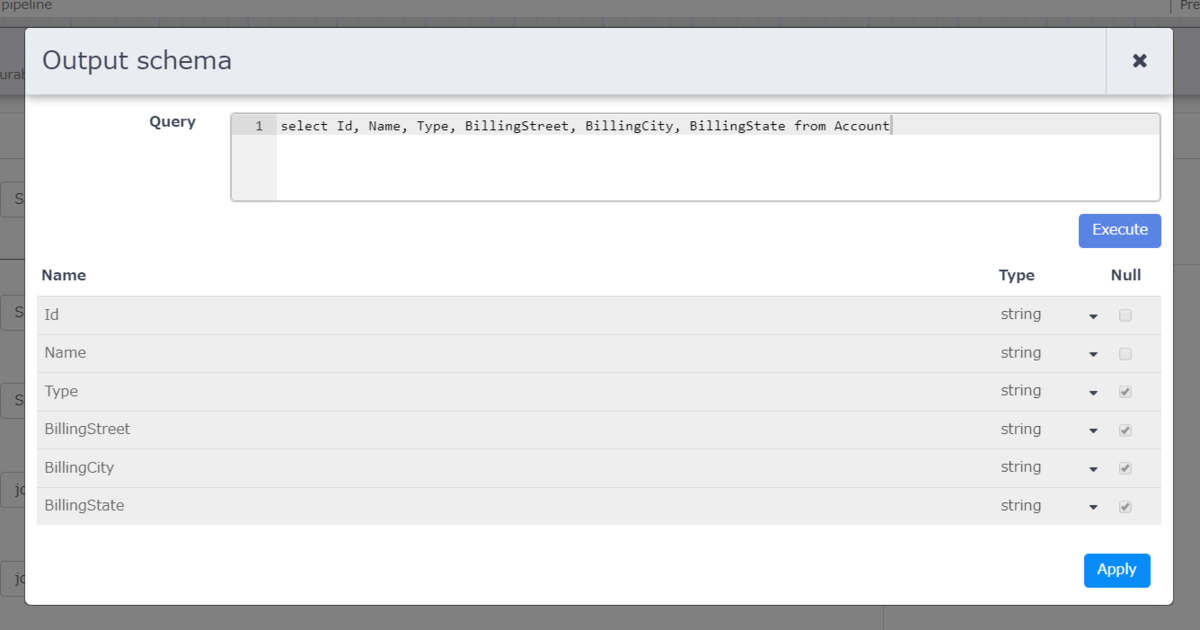
こちらは「Import Query」のすぐ右上にある「Get Schema」をクリックすると下の画面が表示されますので、「Import Query」で入力したクエリを実行し、カラムを定義します。
![Output schema 設定]()
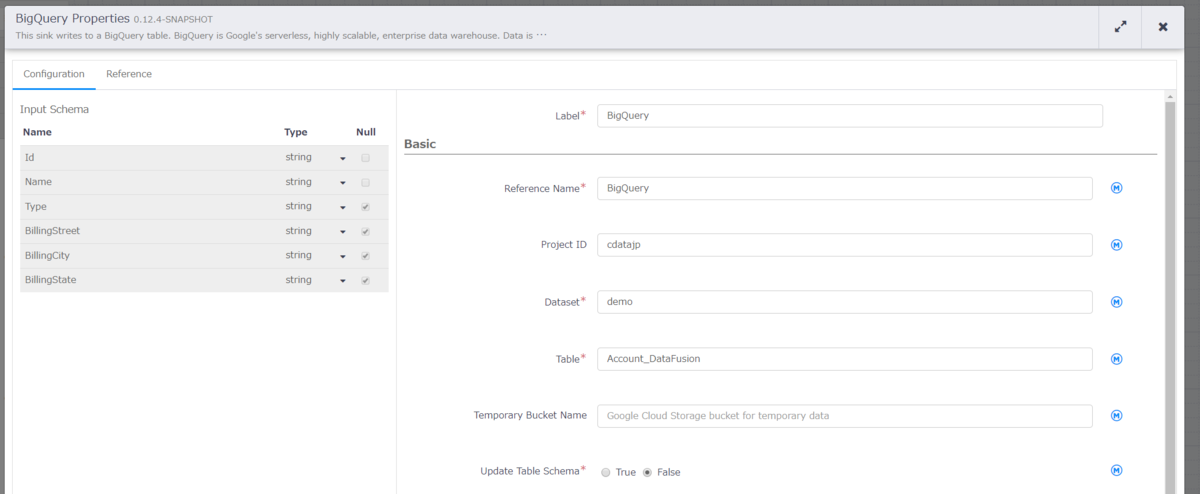
「BigQuery」の設定
こちらも同様に BigQuery のプロパティから下記内容を設定します。
- Label:BigQuery
- Reference Name:BigQuery
- Project ID:使用するProject ID
- DataSet:使用するDataSet
- Table:使用するテーブル名、例:Account_DataFusion
![BigQuery のプロパティ設定]()
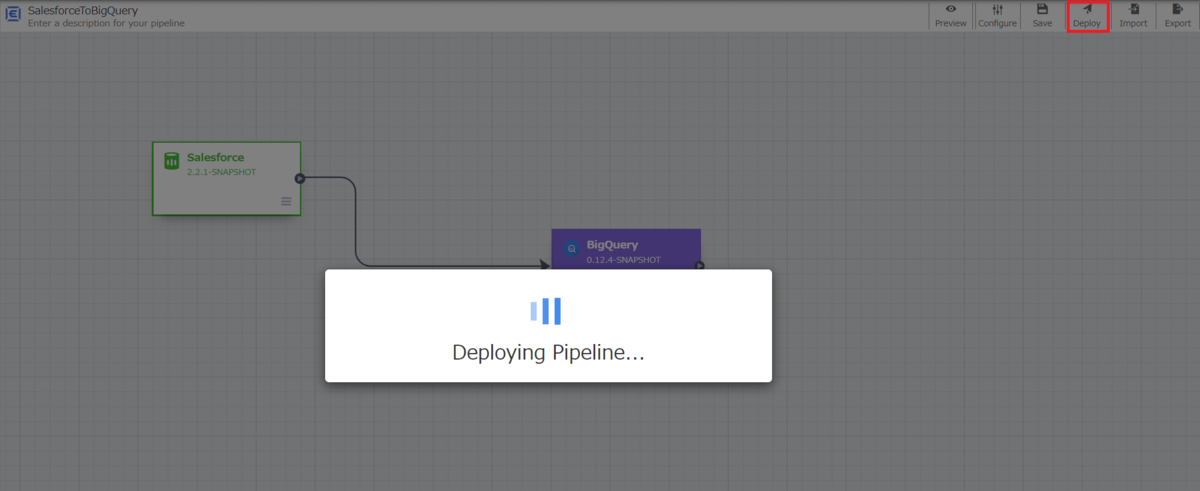
作成したIBM Cloud Object Storage データ からBigQuery のパイプラインの実行
まずは作成したパイプラインをデプロイします。赤枠の「Deploy」ボタンをクリックしてデプロイを行います。
![Deploy Cloud Data Fusion Pipeline]()
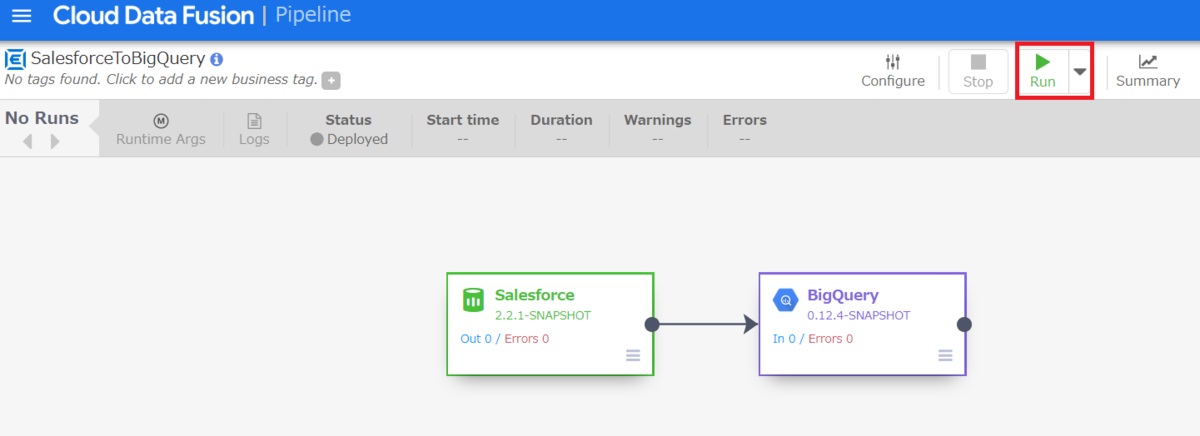
デプロイ完了後、Runボタンが表示されますので、クリックします。
![デプロイしたパイプラインを実行]()
このようにCData JDBC ドライバをアップロードすることで、簡単にGoogle Cloud Data Fusion でIBM Cloud Object Storage データ データをノーコードで連携し、BigQuery などへのパイプラインを作成することができます。
是非、CData JDBC Driver for IBMCloudObjectStorage 30日の無償評価版 をダウンロードして、お試しください。