ノーコードでクラウド上のデータとの連携を実現。
詳細はこちら →


arXivから最新フィードを取得してCSVに同期し、チームでの文献管理や分析に役立てる:CData Sync

皆さんこんにちは。CData インサイドセールスの加藤です。
今回はR&D や研究室向けの記事になります。研究を行う上で基本となる事柄の一つは、最新の研究成果のキャッチアップをすること、つまり論文を読むことですね。しかし日々公開される論文の数は増え続けており、今回使用する科学系論文のホスティングサイト、arXiv への投稿数だけでも、今年の10月で合計14827本(下図)、単純計算で一日494本もの論文が公開されています。自分の関連分野だけに限ったとしても、キャッチアップや管理をしっかりするのは大変そうですね。また、通常論文管理は個々人に任されていることが多く、チームでどのように論文情報を共有し、管理するかという知見はあまり蓄積されていないのではないでしょうか。

そこで本記事では、arXiv の最新論文のデータをRSS で取得して、CData Sync からCSV ファイルに自動でデータを同期する方法をご紹介します。こうして最新の論文情報をデータベース化しておけば、以下のような場面で有益です。
- 研究室での論文管理に役立てる
- タイトルやアブストラクトの内容を可視化・分析して分野のトレンドの把握やテキストデータとして使う
arXiv とは?
arXiv とは世界最大の(主にプレプリントの)論文ホスティングサイトで、主に物理学、数学、コンピュータ科学など数理・自然科学系の最新の論文が無料で閲覧できます。API やRSS が公開されていますが、今回はRSSを使って論文情報にアクセスしていきます。
本記事で使うもの
- CData Sync
- Excel
CData Sync のインストール
このページ から、お使いの環境にあったCData Sync のエディションをダウンロードしてください。ダウンロードされたCDataSync.exe ファイルをクリックすると以下のウィザードが表示されるので、案内に沿ってインストールを完了します。
インストールが終わると自動的にブラウザ上でCData Sync のログイン画面が表示されますので、ウィザードで設定したパスワードを入力してログインして下さい。ライセンスのアクティベーションは、ログイン後「情報」タブから行えます。
CData Sync はMongoDB、MySQL、BigQuery などのデータベース、Teams やGithub、Slack やTwitterなど100以上のデータソースを扱うことができ、研究室でのデータ管理を統一的に行う上で役立ちます。今回はデータソースとしてarXivのRSSフィードを、同期先としてはシンプルにCSV ファイルを使用します。CSVファイルの利点としては、事前設定などがいらずすぐに使えるということと、共有フォルダに入れるなどしておけばExcel などで開いて、研究室で多人数でアクセスするのも容易です。より多くのデータソースを扱いたい、すでに環境がある、という場合はBigQuery やMySQL などのデータベースを同期先として用いるのもいいですね。

CSVについてはこれで完了です。
arXiv をデータソースとして設定
CData Sync ではデフォルトでarXivからのデータ取得に対応していませんが、arXivがRSSフィードをXMLで配信しているので、そのデータソースからCData XML Connector を使用してデータを取得することができます。
まずは、CData Sync にXML Connector をインストールしましょう。「Add More」ボタンからデータソースを追加します(私の画面ではすでに色々インストールされています)。
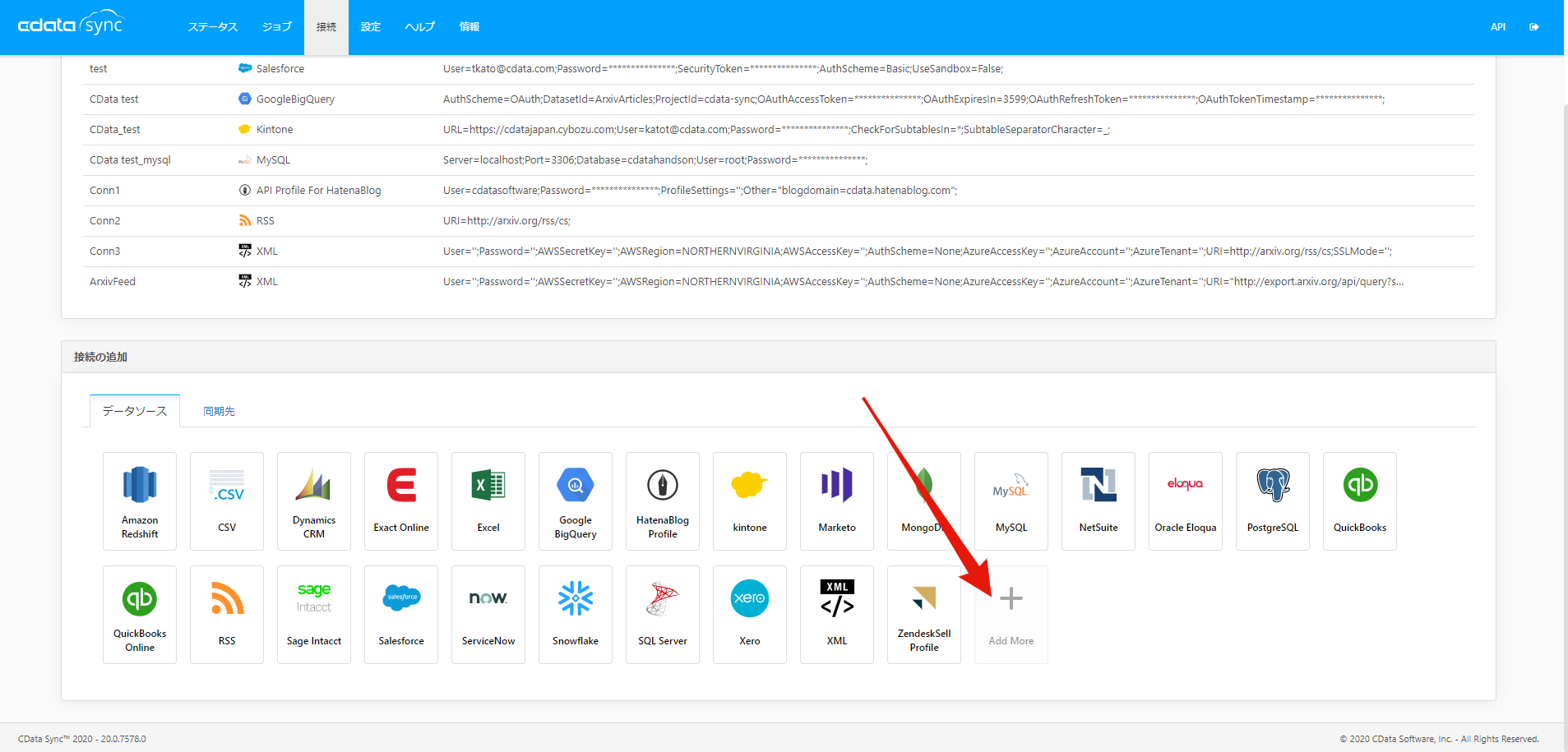
Search に「xml」などと入力するとXML が出てくるので、これをクリックして「ダウンロード&インストール」しましょう。インストールするとCData Sync が再起動するので、再度ログインするとXML Connector がインストールされているはずです!
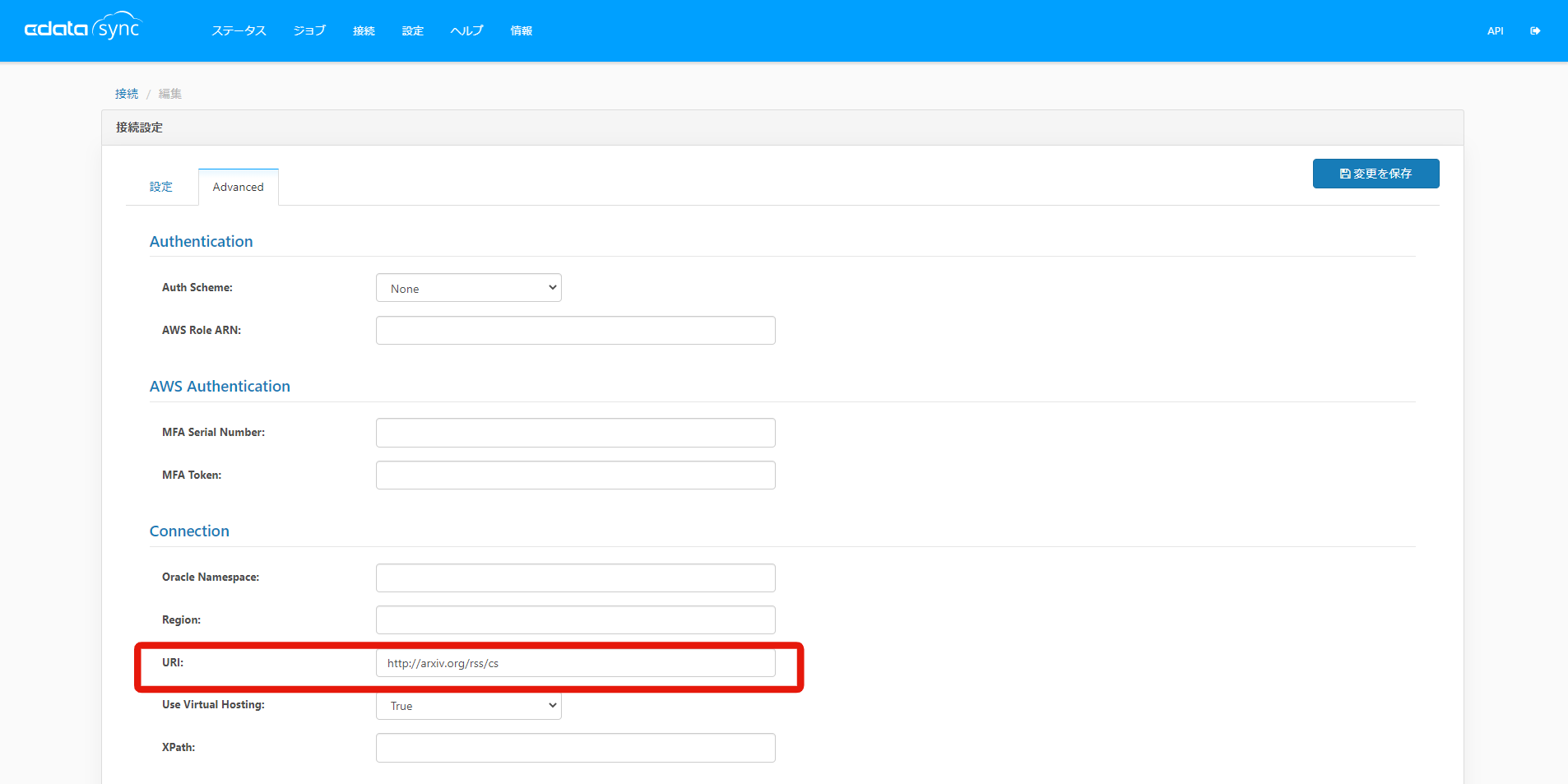
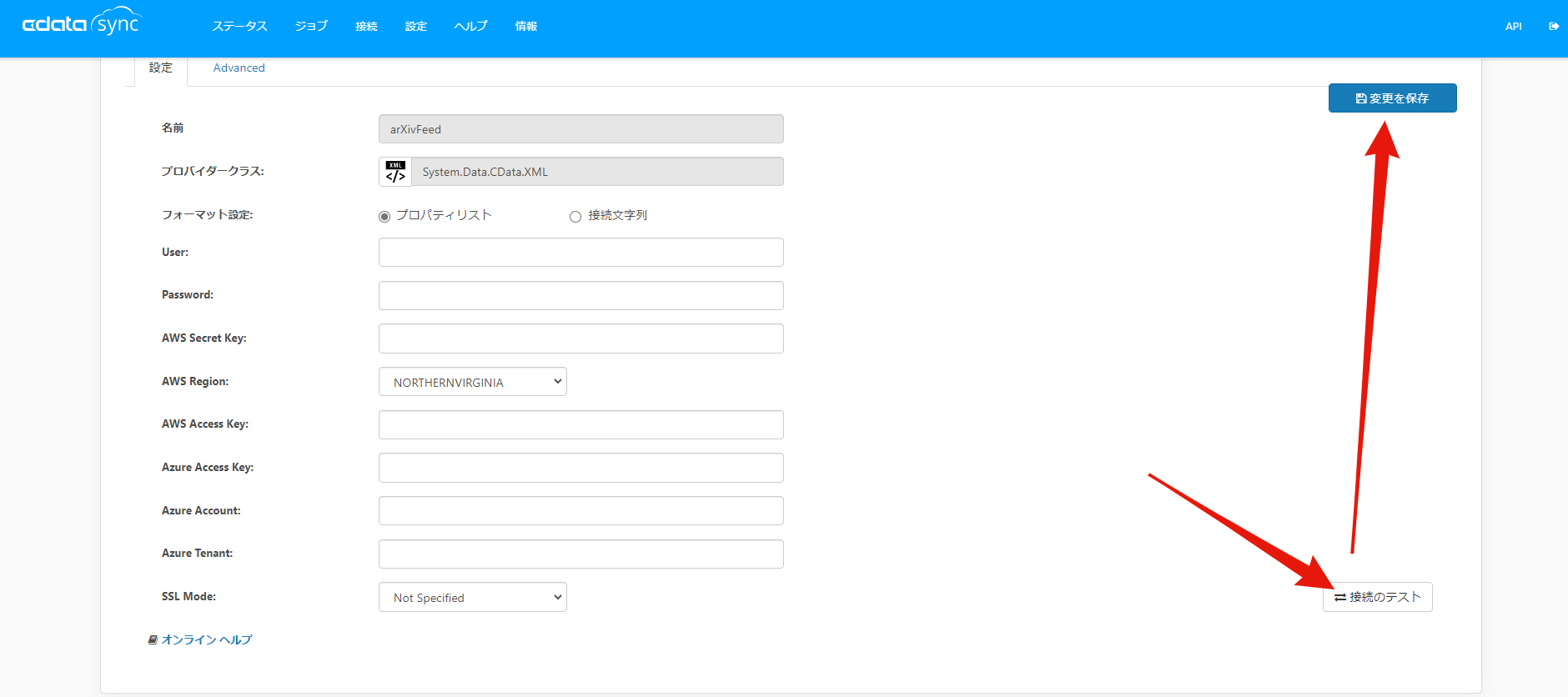
それではインストールしたXML Connector をクリックして、arXiv のRSS に接続しましょう。クリックすると以下のような画面が出てくるので、「Advanced」をクリックして、「Connection」以下にある「URI」にarXiv のRSS フィードのURL を設定します。今回は"http://arxiv.org/rss/cs" を使用します。末尾の"cs"部分でフィードが取得するカテゴリを指定します。"cs.AI"などとしてより下位のカテゴリを選択することも可能です。
「接続のテスト」をクリックして、ページ上部に「接続に成功しました。」と表示されたら成功です!「変更を保存」を押して作成した接続を保存しちゃいましょう。
CSV ファイルを同期先として設定してarXiv とCSV を連携
次にCSVファイルを同期先に加えましょう。「接続」画面の「同期先」タブを選択して「CSV Destionation」をクリックします。以下のような画面が出てくるので、「名前」と「Destination Folder」を設定しましょう。「Destination Folder」以下にデータソースのテーブル名に対応する名前のCSVが自動的に作成されるので、ファイル作成先のフォルダ(任意)のローカルパスを指定します。

次に「ジョブ」タブから、作成した接続をつないで実際にデータの同期を行うジョブを作成します。「ジョブを追加」をクリックすると、「新しいジョブを作成」画面が出てきますので、「ジョブ名」を設定して、「ソース」に先ほど作成したarXiv接続を、「同期先」に作成済みのCSV 接続を設定します。完了したら、「作成」ボタンからジョブを作成します。


CSV から同期したデータを見てみる
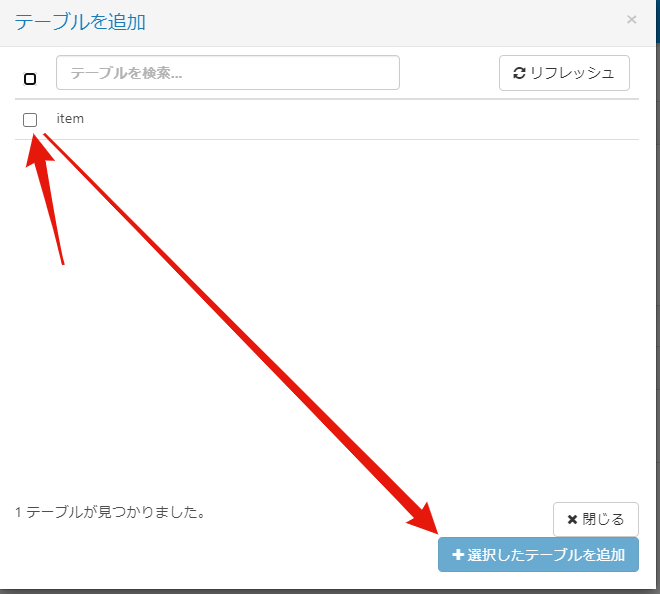
それでは、実際にデータを同期していきましょう。まずは作成したジョブを開いて、「テーブルを追加」ボタンをクリックします(もしくは、「カスタムクエリを追加」ボタンで自前のSQLコマンドを渡すこともできます)。以下のような画面が出てくるので、追加したいテーブル、ここでは"items"を選択して、「選択したテーブルを追加」ボタンをクリックします。
これで同期先のテーブルが設定されたので、今度はテーブルの中身の設定をします。作成したジョブをクリックすると、設定画面が出てきます。「一般」タブからは同期先のスキーマ名やテーブル名を設定できます。好みのテーブル名(今回はこれがcsvファイルの名前になります)を設定します。また、「カスタムクエリ」に"LIMIT 100"を加えて取得するフィード数を絞っています。
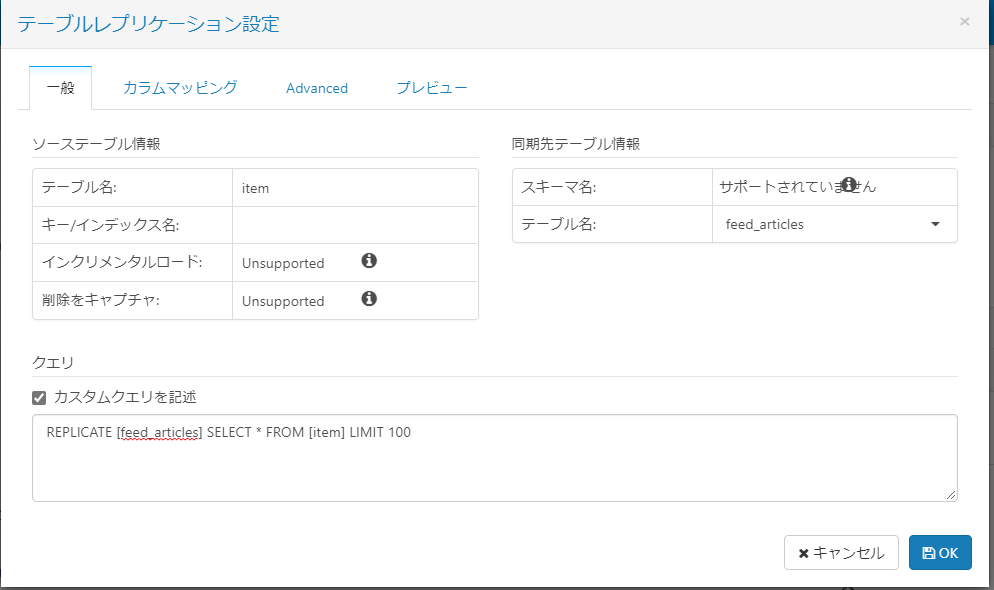
「カラムマッピング」タブでは、テーブル中のどのカラムを同期するか選択できます。同期する必要のないカラムがある場合には、この画面で削除できます。
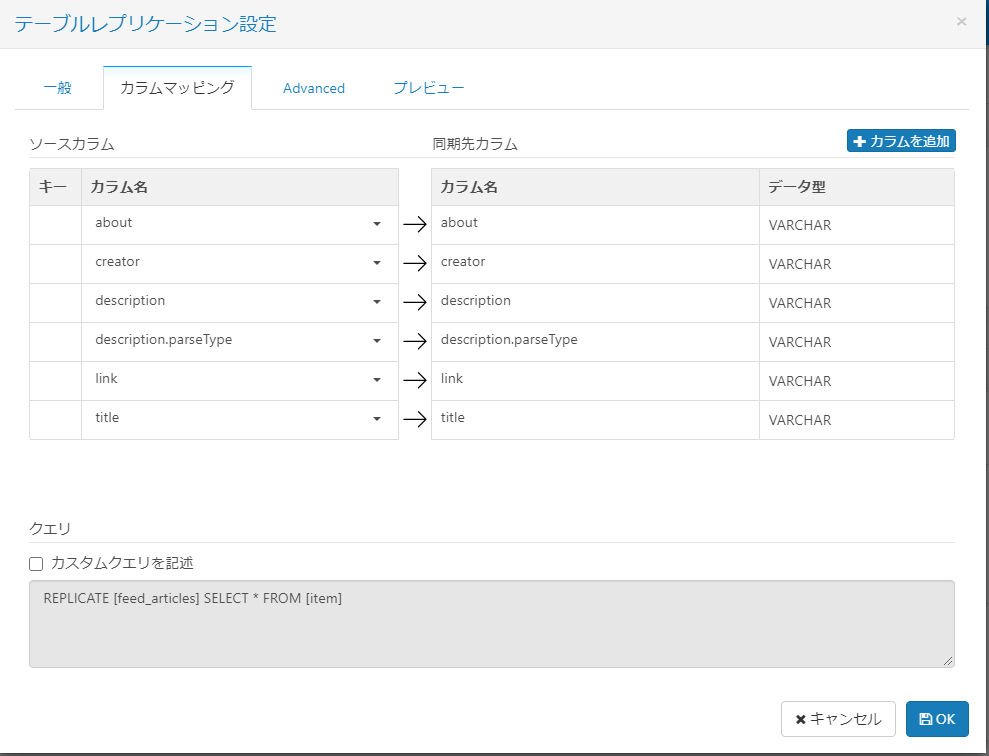
「プレビュー」タブから取得するデータの一覧を閲覧できます。
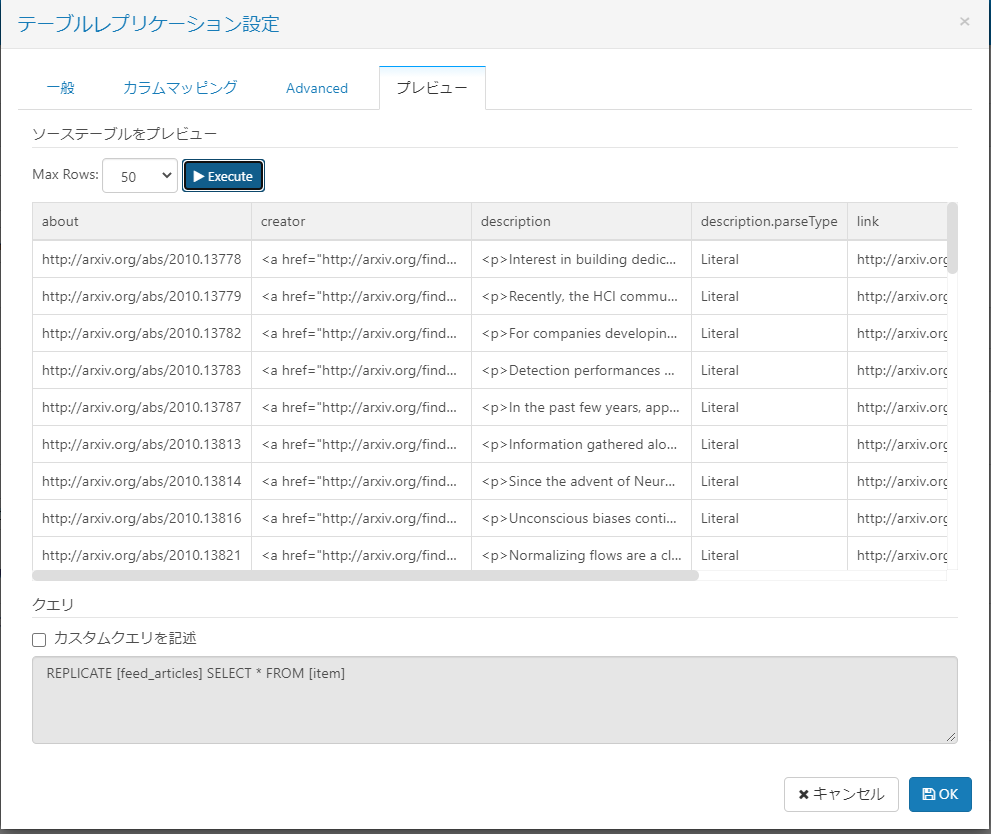
準備ができたら、「OK」ボタンを押してテーブルを設定しましょう。 ジョブ設定では同期のスケジュールも設定できるので、例えば「Run Job」を「Daily」に設定して「時」を設定すれば、このジョブが指定した間隔で定期的に実行されます。
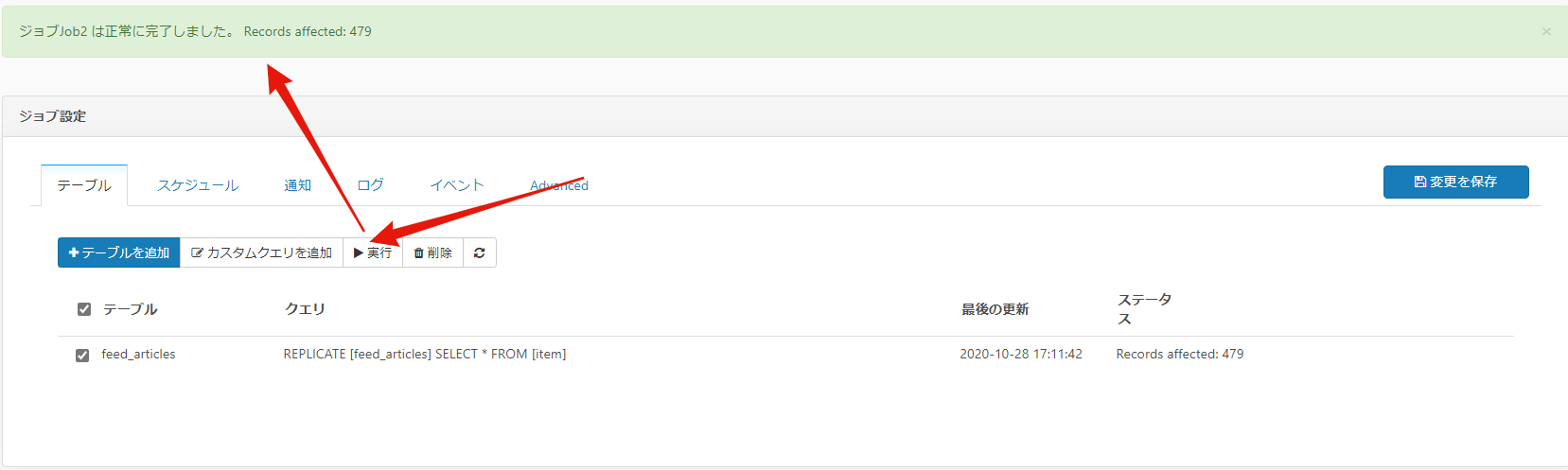
後は、実行したいクエリを選択して「実行」ボタンを押すだけです!以下のような文が表示されたら同期完了です!
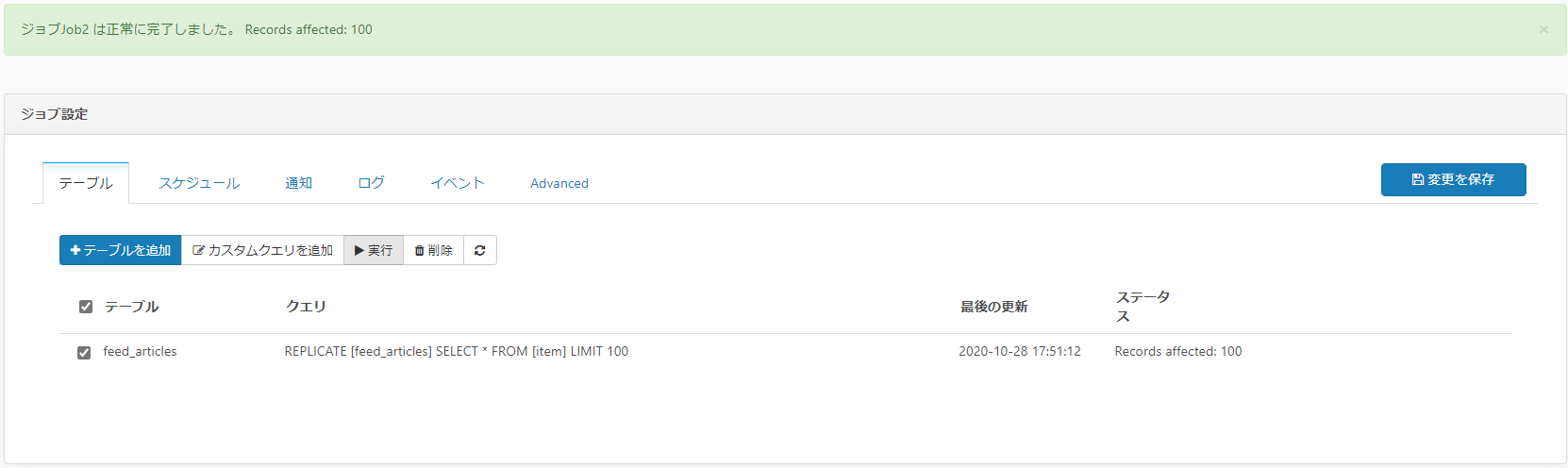
それでは実際に取得したデータを見てみましょう。CSV の接続設定で指定したパス以下に、ファイルが作成されていると思います。クリックして、Excel で開いてみましょう。

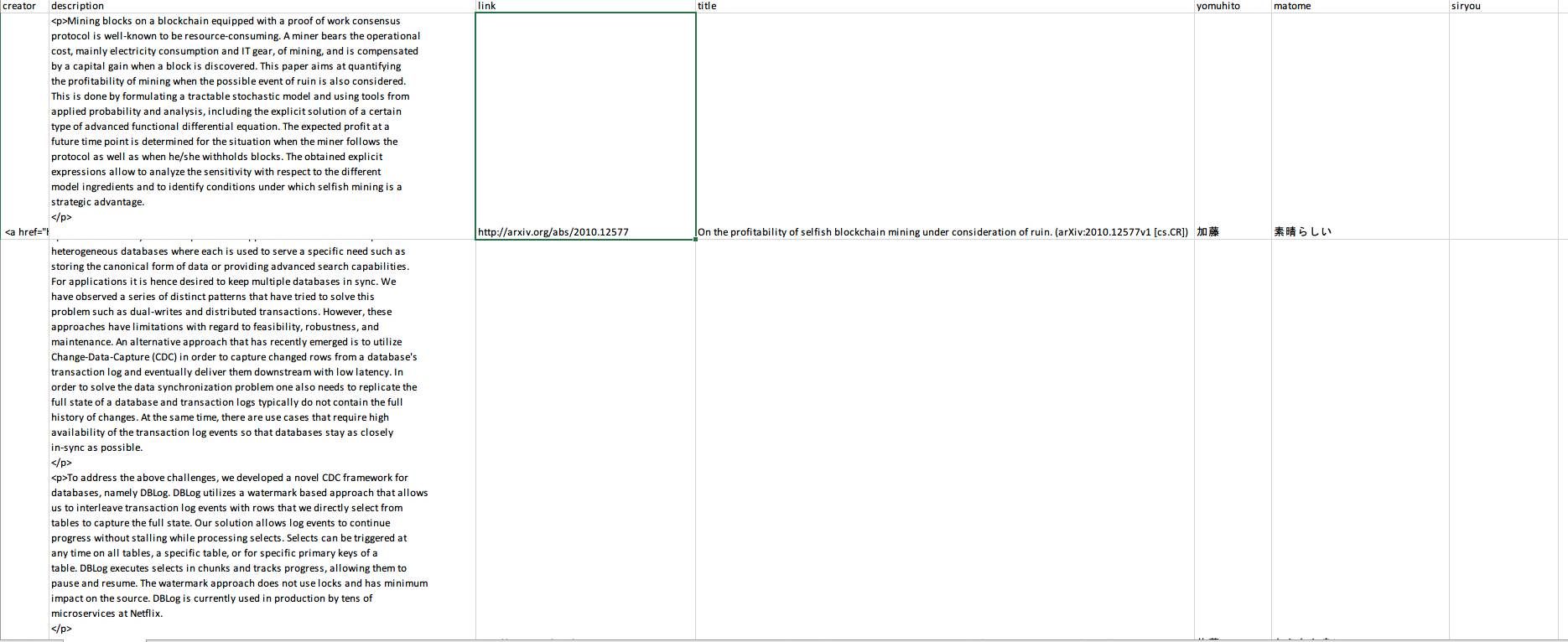
"title"、"description"、"link"など、ちゃんとデータが取得されていますね。こうしてテーブル化しておけば、概要とタイトルをスキムして論文を読むかどうか決めたり、この論文を誰が読むか、読んだ後の簡単なまとめ、論文紹介などの資料を添付する列を作成して、ファイルをチームで共有することで最新文献の管理がしやすくなりますね。CData Sync のスケジュール機能で好みの間隔で自動的にフィードを取得してアップデートされるので、最新の情報を常に取得することができます。
また、論文のトレンドなどに関する分析の材料としても使えます。例えば、以下ではCSVファイルをPythonで読み込んで、取得した論文100件のタイトルが含む単語から、ワードクラウドを作成しました。

今回はコンピュータ科学カテゴリのフィードを取得しましたが、"Neural Network"や"Learning"、"Graph"、"Training"、"Attension"など機械学習、ディープラーニング系の論文がまだまだトレンドになっている様子がわかります。
おわりに
本記事では、arXivのフィードをCData SyncでCSVファイルに同期して、チームでの文献管理やトレンド分析に役立てる方法をご紹介しました。 皆さんも良き論文ライフを!