ノーコードでクラウド上のデータとの連携を実現。
詳細はこちら →CData


こんにちは!プロダクトスペシャリストの宮本です。
データ分析基盤へのExcel データの取り込みのニーズが高まっています。CData Sync は、数百のSaaS / DB のデータをDatabricks をはじめとする各種DB / データウェアハウスにノーコードで統合・転送(複製)が可能なデータパイプラインツールです。
本記事では、Excel データをCData Sync を使ってDatabricks に統合するデータパイプラインを作っていきます。
CData Sync は、レポーティング、アナリティクス、機械学習、AI などで使えるよう、社内のデータを一か所に統合して管理できるデータ基盤をノーコードで構築できるETL / ELT ツールで、以下の特徴を持っています。
CData Sync では、1.データソースとしてExcel の接続を設定、2.同期先としてDatabricks の接続を設定、3.Excel からDatabricks への転送ジョブの作成、という3つのステップだけで転送処理を作成可能です。以下に具体的な設定手順を説明します。
まずはじめに、CData Sync のブラウザ管理コンソールにログインします。CData Sync のインストールをまだ行っていない方は、本記事の製品リンクから「CData Sync」をクリックしてCData Sync をインストールしてください。30日間の無償トライアルをご利用いただけます。インストール後にCData Sync が起動して、ブラウザ設定画面が開きます。
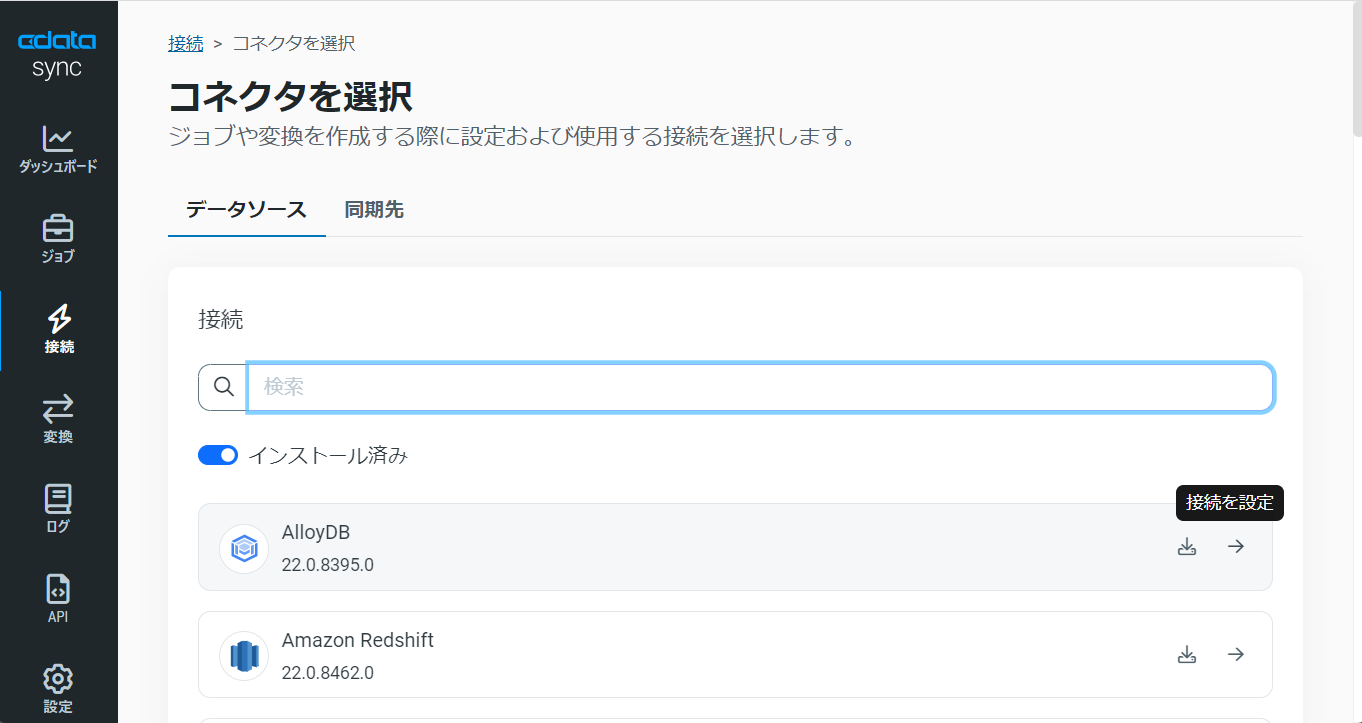
それでは、データソース側にExcel を設定していきましょう。左の「接続」タブをクリックします。
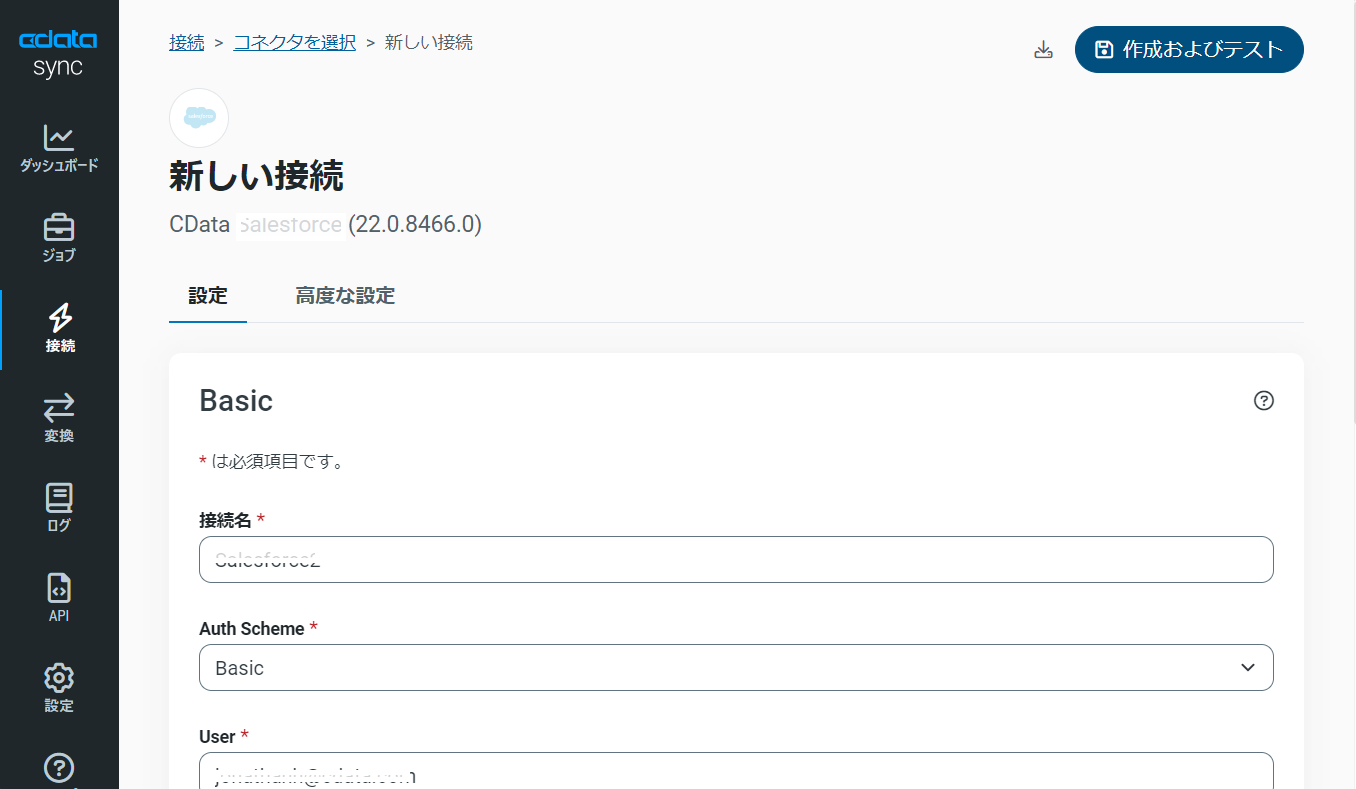
Authentication セクションのExcelFile には有効なExcel ファイルを設定する必要があります。
URI をバケット内のExcel ファイルに設定します。さらに、次のプロパティを設定して認証します。
URI をExcel ファイルへのパスに設定します。Box へ認証するには、OAuth 認証標準を使います。 認証方法については、Box への接続 を参照してください。
URI をExcel ファイルへのパスに設定します。Dropbox へ認証するには、OAuth 認証標準を使います。 認証方法については、Dropbox への接続 を参照してください。ユーザーアカウントまたはサービスアカウントで認証できます。ユーザーアカウントフローでは、以下の接続文字列で示すように、ユーザー資格情報の接続プロパティを設定する必要はありません。
URI をExcel ファイルを含むドキュメントライブラリに設定します。認証するには、User、Password、およびStorageBaseURL を設定します。
URI をExcel ファイルを含むドキュメントライブラリに設定します。StorageBaseURL は任意です。指定しない場合、ドライバーはルートドライブで動作します。 認証するには、OAuth 認証標準を使用します。
URI をExcel ファイルへのパスが付いたサーバーのアドレスに設定します。認証するには、User およびPassword を設定します。
デスクトップアプリケーションからのGoogle への認証には、InitiateOAuth をGETANDREFRESH に設定して、接続してください。詳細はドキュメントの「Google Drive への接続」を参照してください。
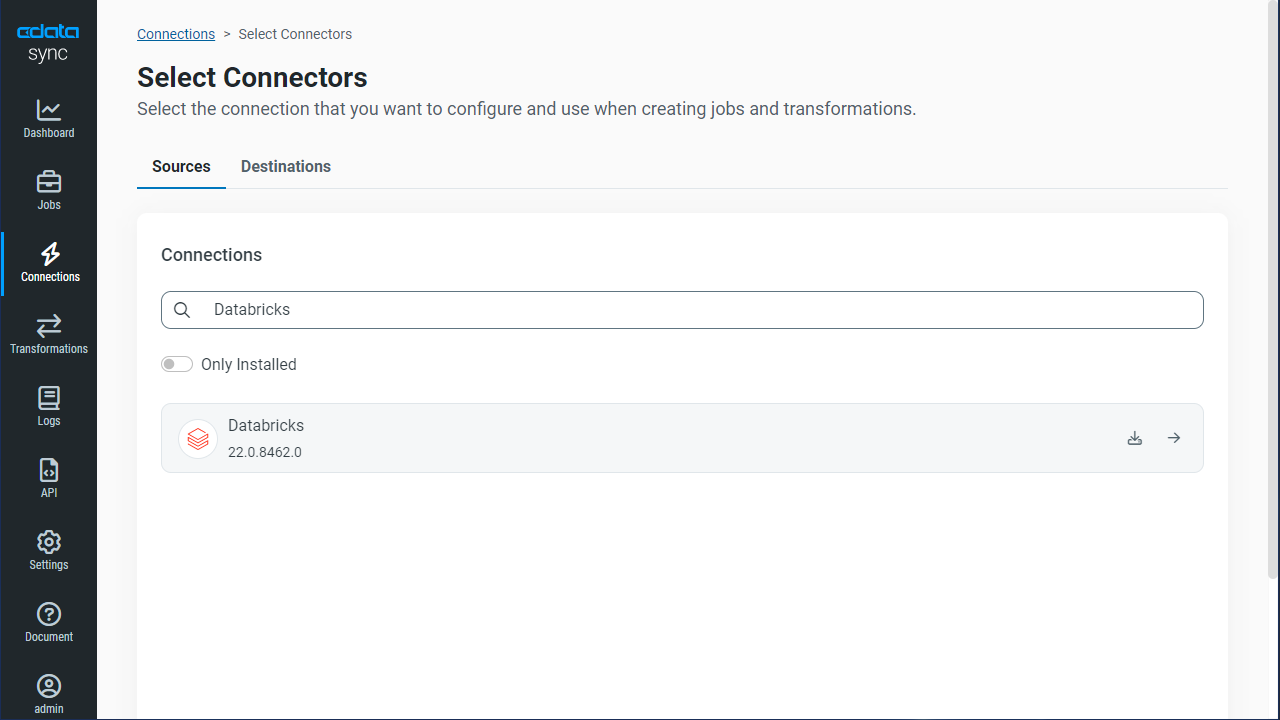
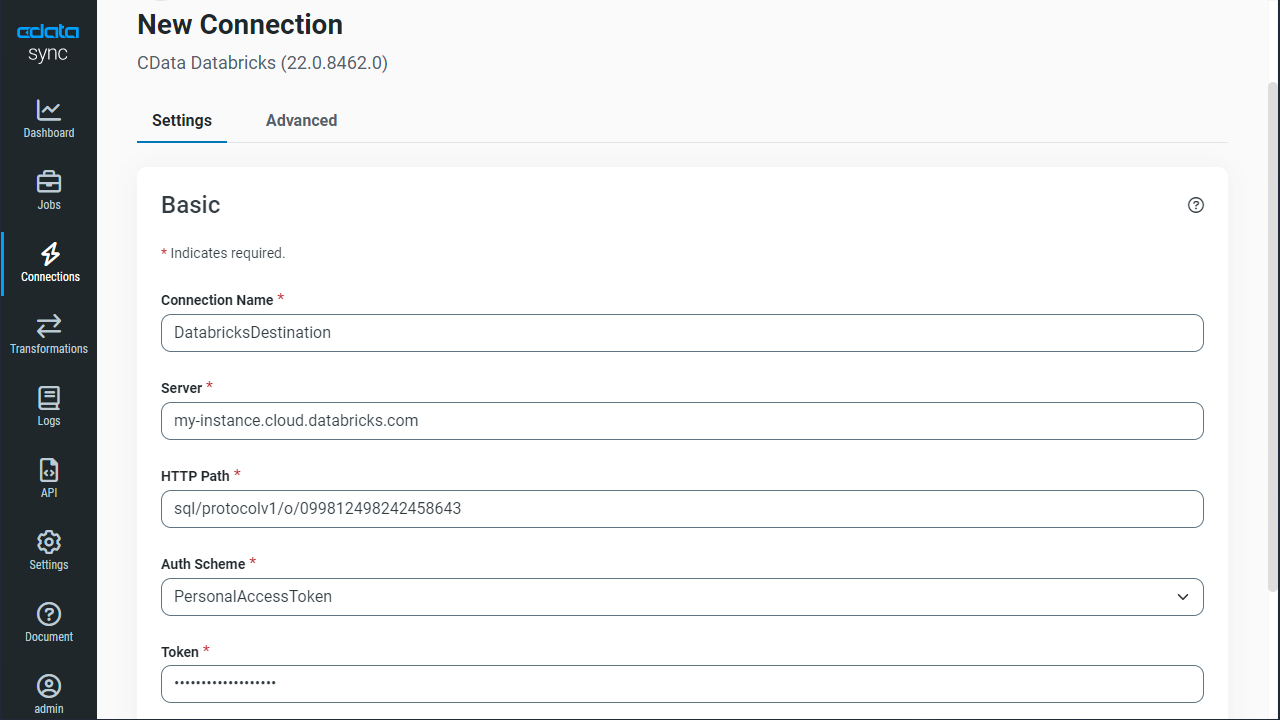
次に、Excel データを書き込む先(=同期先)として、Databricks を設定します。同じく「接続」タブを開きます。
NOTE:必要なプロパティの値は、Databricks インスタンスでクラスターに移動して目的のクラスターを選択し、Advanced Options の下にあるJDBC/ODBC タブを選択することで見つけることができます。
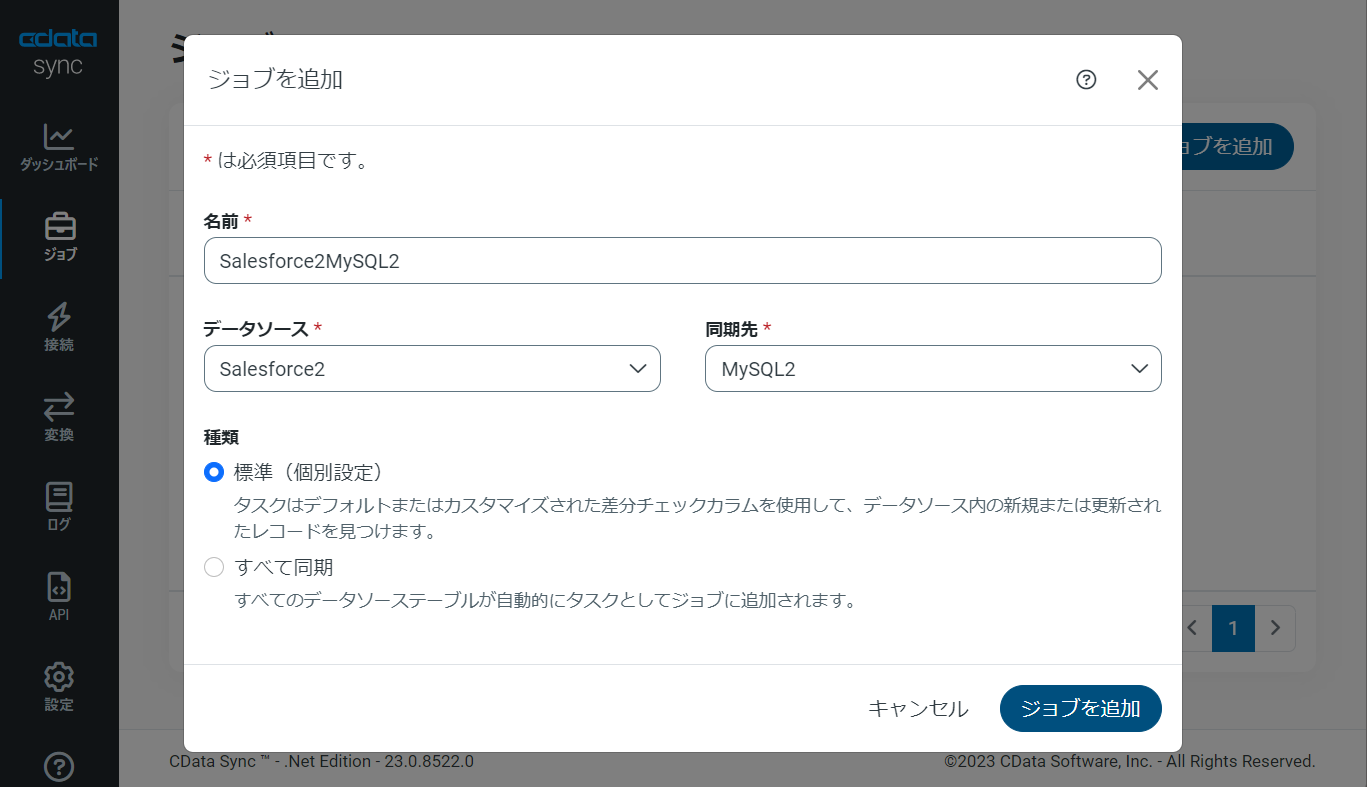
CData Sync では、転送をジョブ単位で設定します。ジョブは、Excel からDatabricks という単位で設定し、複数のテーブルを含むことができます。転送ジョブ設定には、「ジョブ」タブに進み、「+ジョブを追加」ボタンをクリックします。
「ジョブを追加」画面が開き、以下を入力します:
Excel のすべてのオブジェクト / テーブルを転送するには、「種類」セクションで「すべて同期」を選択して、「ジョブを追加」ボタンで確定します。
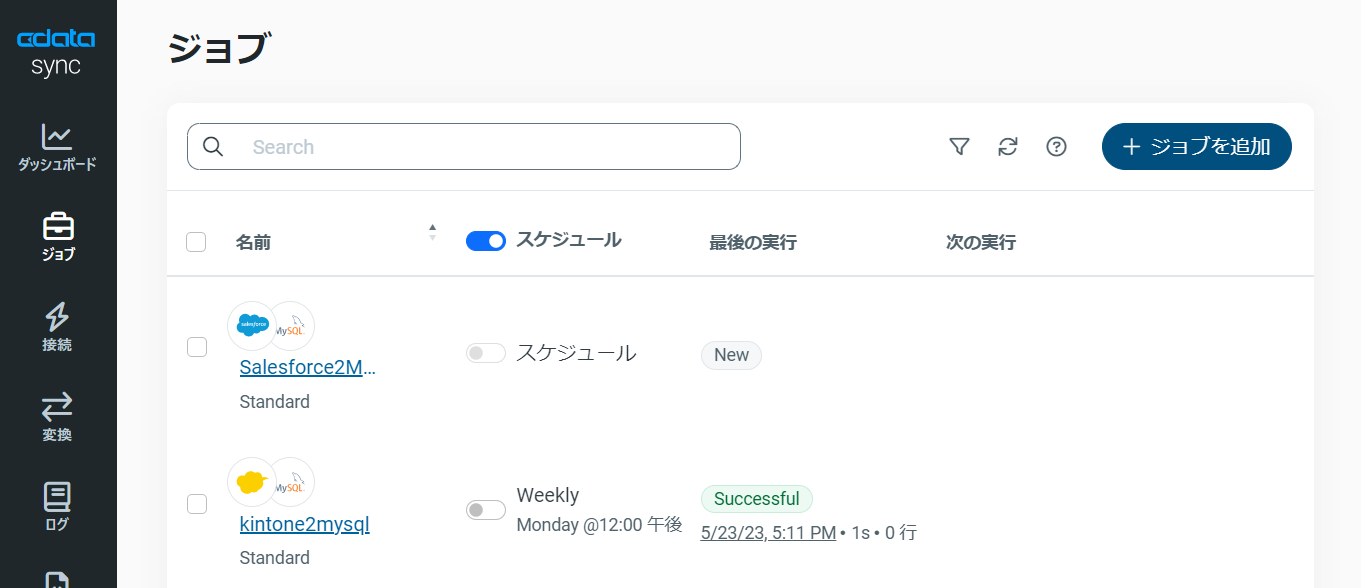
作成したジョブ画面で、右上の「▷実行」ボタンをクリックするだけで、全Excel テーブルのDatabricks への同期を行うことができます。
Excel から特定のオブジェクト / テーブルを選択して転送を行うことが可能です。「種類」セクションでは、「標準(個別設定)」を選んでください。
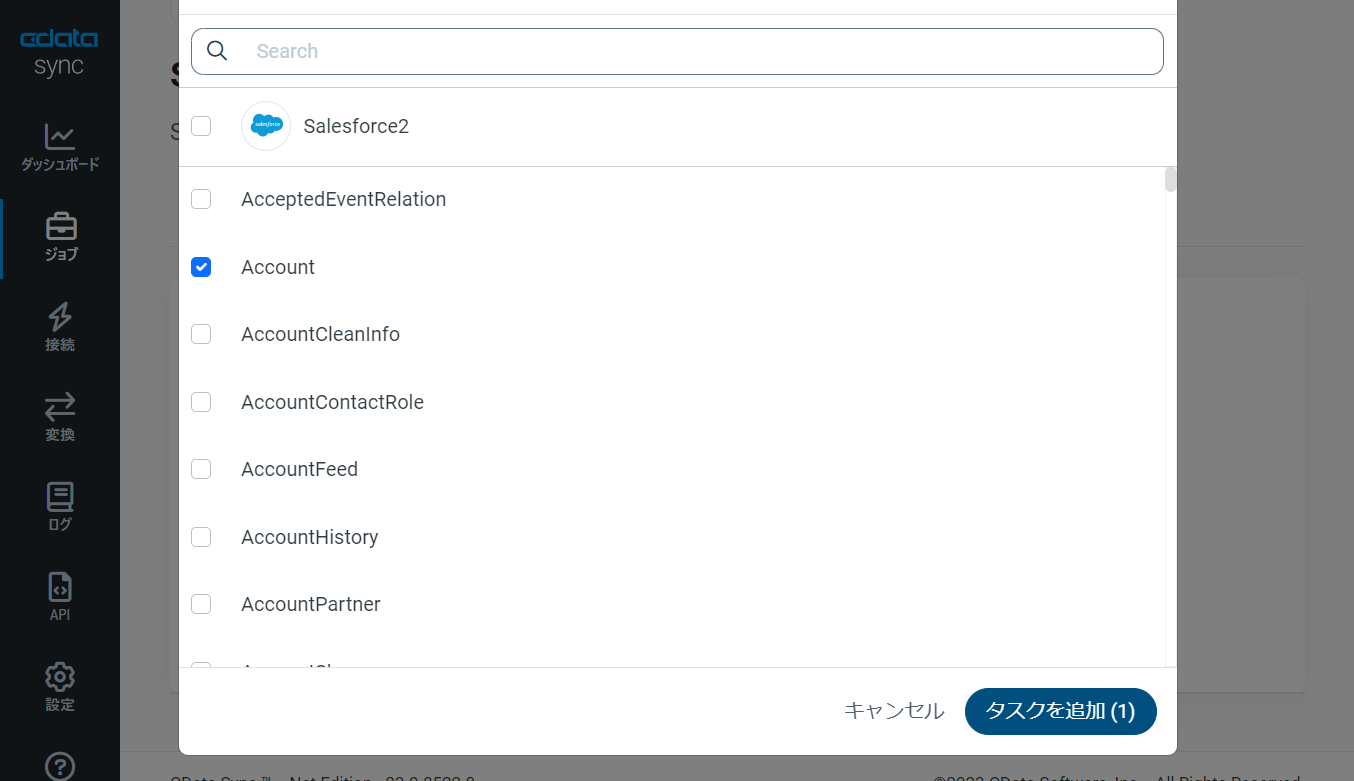
次に「ジョブ」画面で、「タスク」タブをクリックし、「タスクを追加」ボタンをクリックします。 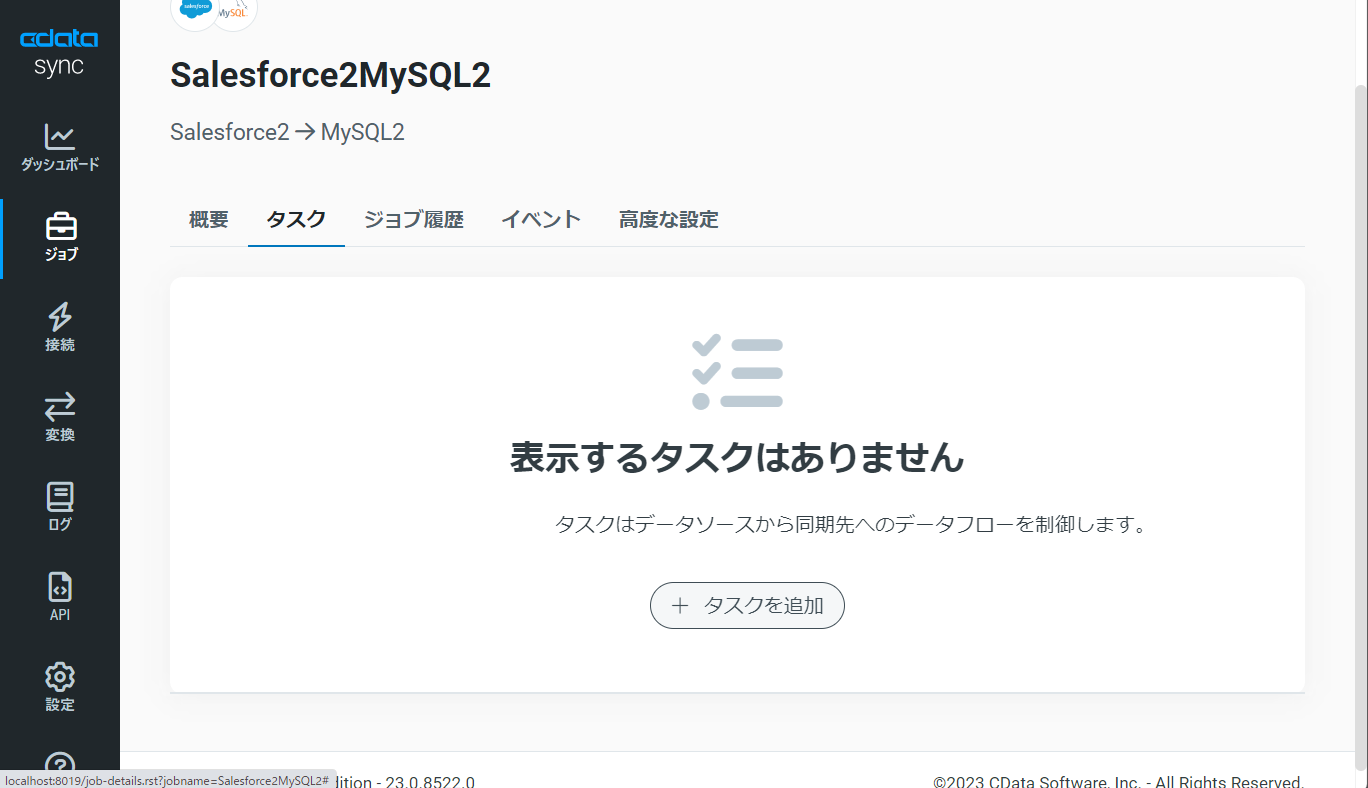
するとCData Sync で利用可能なオブジェクト / テーブルのリストが表示されるので、転送を行うオブジェクトにチェックを付けます(複数選択可)。「ジョブを追加」ボタンで確定します。
作成したジョブ画面で、「▷実行」ボタンをクリックして(もしくは各タスク毎の実行ボタンを押して)、転送ジョブを実行します。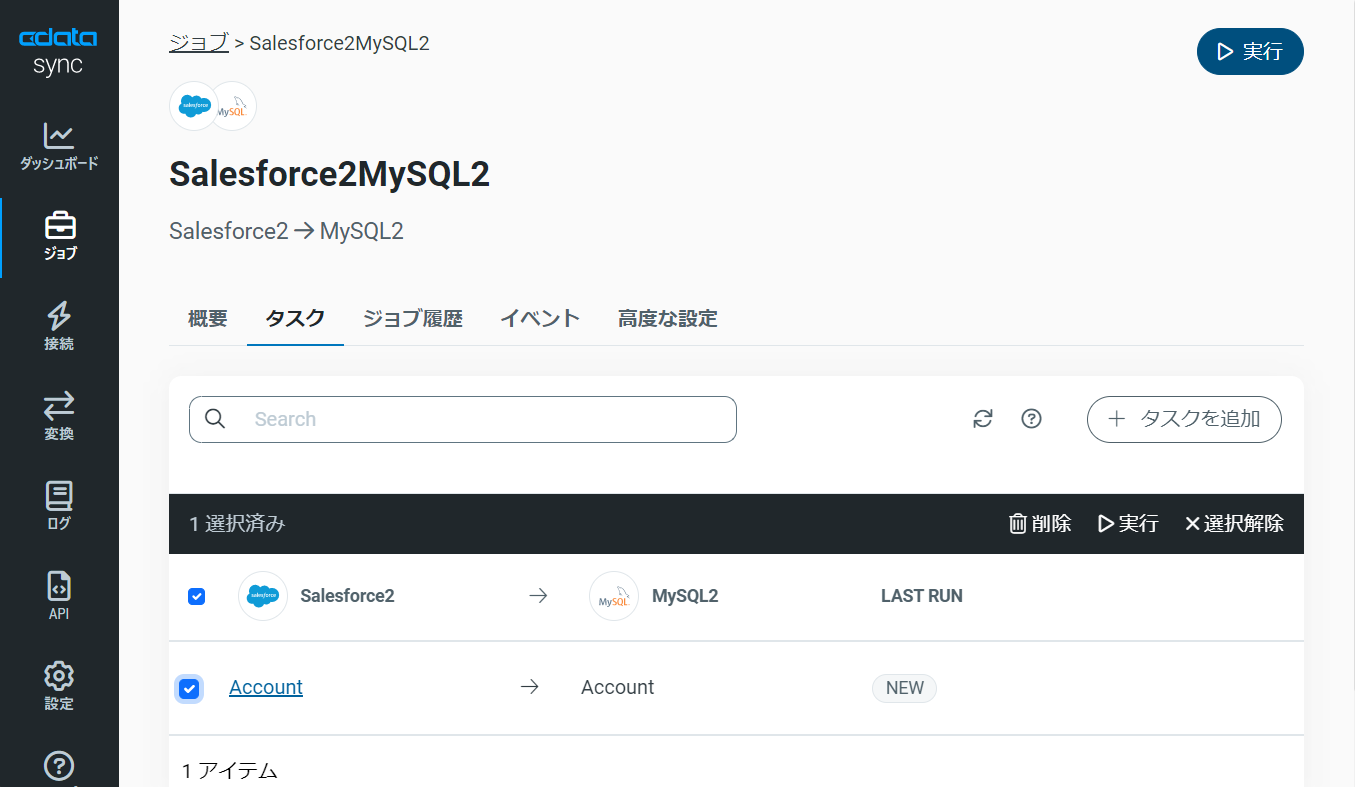
このようにとても簡単にExcel からDatabricks への同期を行うことができました。
CData Sync では、同期ジョブを1日に1回や15分に1回などのスケジュール起動をすることができます。ジョブ画面の「概要」タブから「スケジュール」パネルを選び、「⚙設定」ボタンをクリックします。「間隔」と同期時間の「毎時何分」を設定し、「保存」を押して設定を完了します。これでCData Sync が同期ジョブをスケジュール実行してくれます。ユーザーはダッシュボードで同期ジョブの状態をチェックするだけです。 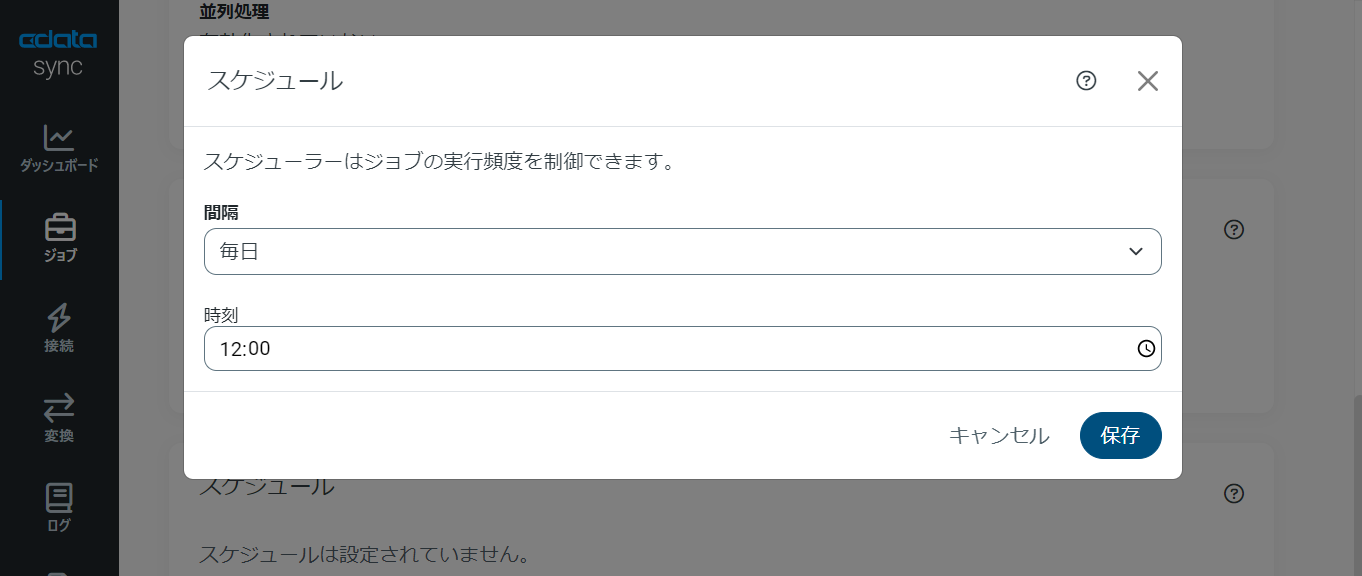
CData Sync では、主要なデータソースでは、差分更新が可能です。差分更新では、最後のジョブ実行時からデータソース側でデータの追加・変更があったデータだけを同期するので、転送のクエリ・通信のコストを圧倒的に抑えることが可能です。
差分更新を有効化するには、ジョブの「概要」タブから「差分更新」パネルを選び、「⚙設定」ボタンをクリックします。「開始日」と「転送間隔」を設定して、「保存」します。
CData Sync は、デフォルトではExcel のオブジェクト / テーブルをそのままDatabricks に複製しますが、ここにSQL、またはdbt 連携でのETL 処理を組み込むことができます。テーブルカラムが多すぎる場合や、データ管理の観点から一部のカラムだけを転送したり、さらにデータの絞り込み(フィルタリング)をしたデータだけを転送することが可能です。
ジョブの「概要」タブ、「タスク」タブへと進みます。選択されたタスク(テーブル)の「▶」の左側のメニューをクリックし、「編集」を選びます。タスクの編集画面が開きます。
UI からカラムを選択する場合には、「カラム」タブから「マッピング編集」をクリックします。転送で使用しないカラムからチェックを外します。
SQL を記述して、フィルタリングなどのカスタマイズを行うには、「クエリ」タブをクリックし、REPLICATE 「テーブル名」の後に標準SQL でフィルタリングを行います。
このようにノーコードで簡単にExcel データをDatabricks に転送できます。データ分析、AI やノーコードツールからのデータ利用などさまざまな用途でCData Sync をご利用いただけます。30日の無償トライアルで、シンプルでパワフルなデータパイプラインを体感してください。
日本のユーザー向けにCData Sync は、UI の日本語化、ドキュメントの日本語化、日本語でのテクニカルサポートを提供しています。
CData Sync の 導入事例を併せてご覧ください。