ノーコードでクラウド上のデータとの連携を実現。
詳細はこちら →Google Sheets Driver の30日間無償トライアルをダウンロード
30日間の無償トライアルへ製品の詳細
Java アプリケーションをGoogle ドキュメントに保存されているスプレッドシートのリアルタイムデータに簡単に接続できます。Google スプレッドシートを使用して、アプリケーションの要となるデータを管理できます。
CData


こんにちは!リードエンジニアの杉本です。
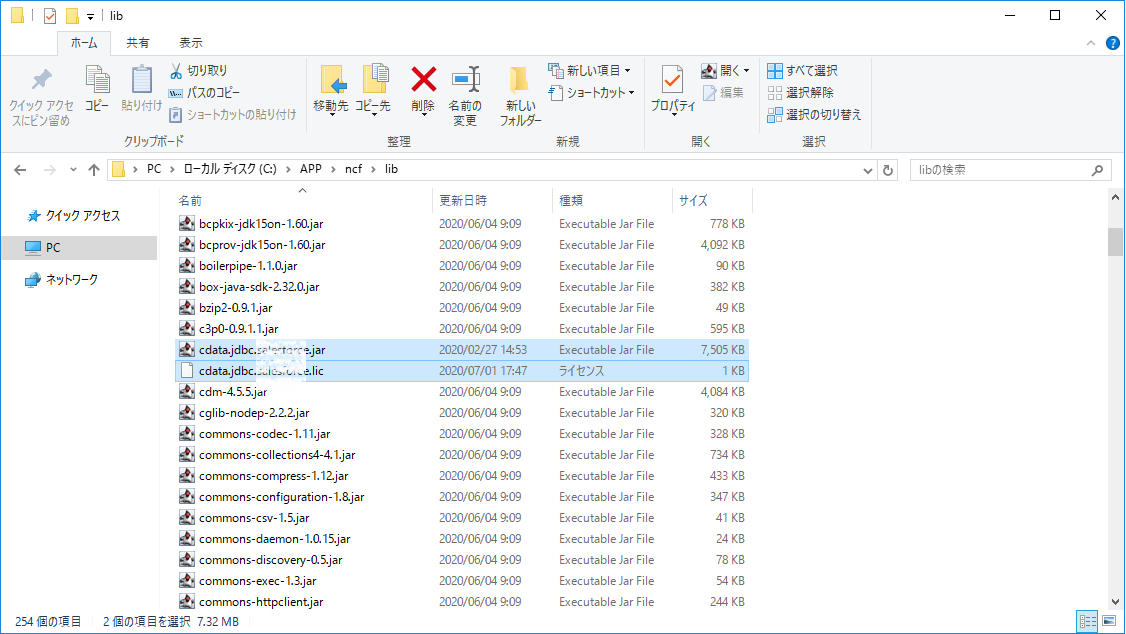
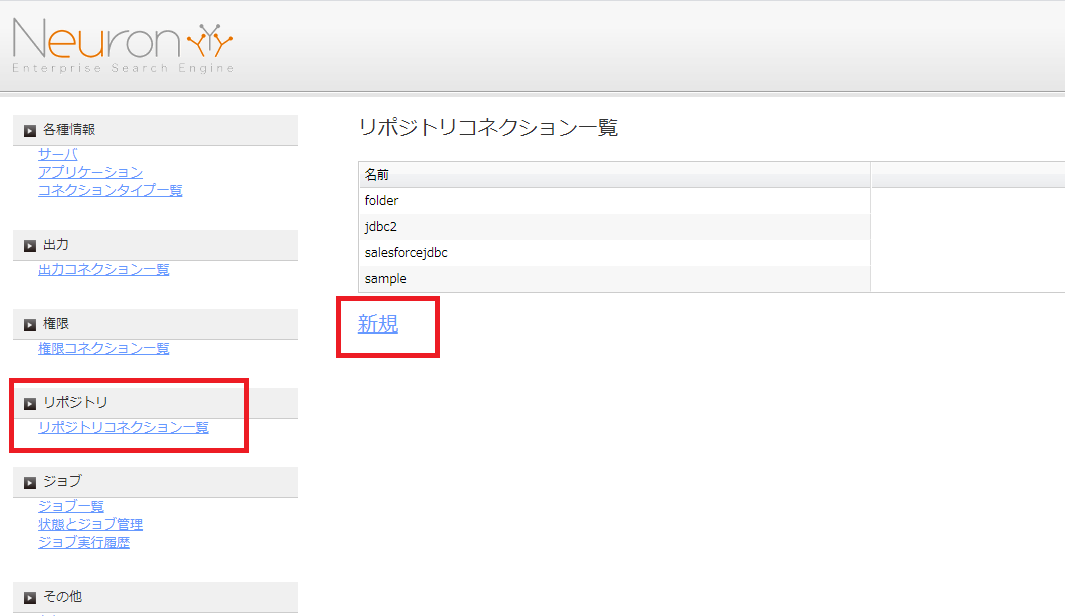
ブレインズテクノロジー社のNeuron は、先端OSS 技術(Apache Solr)を活用したエンタープライズサーチ(企業内検索エンジン)サービスです。Apache Solr は、エンタープライズサーチ機能をAPI として提供してくれますが、Neuron はApache Solr に企業ユーザーがデータを探索するためのシンプルかつ使いやすいユーザーインターフェースと管理画面・運用機能を提供してくれます。これによりエンドユーザーが簡単にエンタープライズサーチを利用することができます。管理画面では、ファイルやデータのクローリング設定がUI で行えるようになっています。この記事では、Neuron に備わっているJDBC インターフェース経由で、CData JDBC Driver for GoogleSheets を利用することでNeuron にGoogle Sheets データを取り込んで検索で利用できるようにします。
スプレッドシートに接続するには、Google への認証を行い、Spreadsheet 接続プロパティにスプレッドシートの名前またはフィードリンクを設定します。Google Drive のスプレッドシートの情報一覧を表示したい場合は、認証後にSpreadsheets ビューにクエリを実行します。
ClientLogin(ユーザー名 / パスワード認証)は、2012年4月20日より正式に非推奨となり、現在は利用できません。代わりに、OAuth 2.0 認証規格を使用してください。 個々のユーザーに代わってGoogle API にアクセスするには、埋め込みクレデンシャルを使用するか、独自のOAuth アプリを登録します。
OAuth は、Google Apps ドメインのユーザーに代わって、サービスアカウントを使って接続することもできます。サービスアカウントで認証するには、OAuth JWT 値を取得するためのアプリケーションを登録する必要があります。
Google アカウント、Google Apps アカウント、二段階認証を使用するアカウントなど、様々なアカウントタイプでGoogle スプレッドシートに接続する方法は、ヘルプドキュメントの「はじめに」を参照してください。
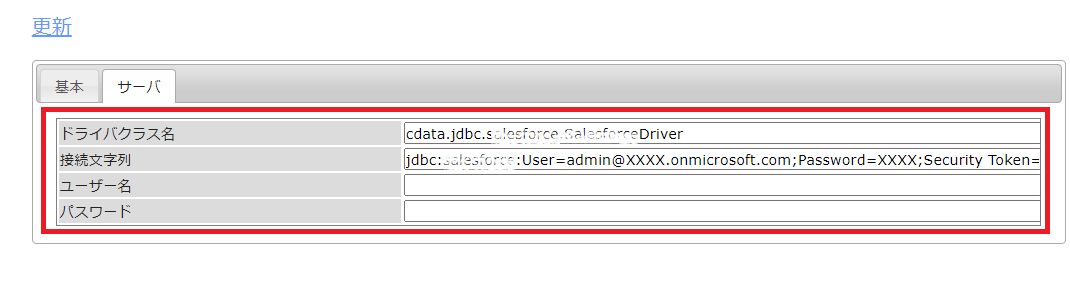
ドライバクラス名:cdata.jdbc.googlesheets.GoogleSheetsDriver
接続文字列:jdbc:googlesheets:Spreadsheet=MySheet;InitiateOAuth=REFRESH
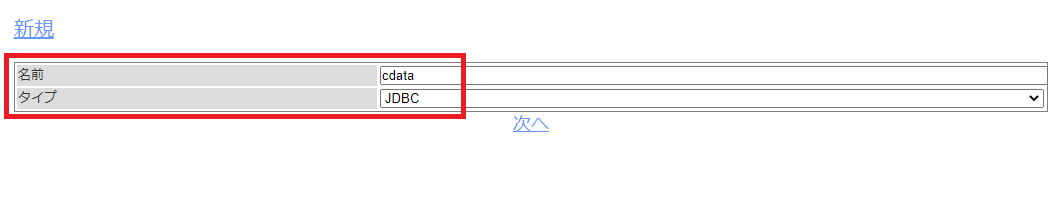
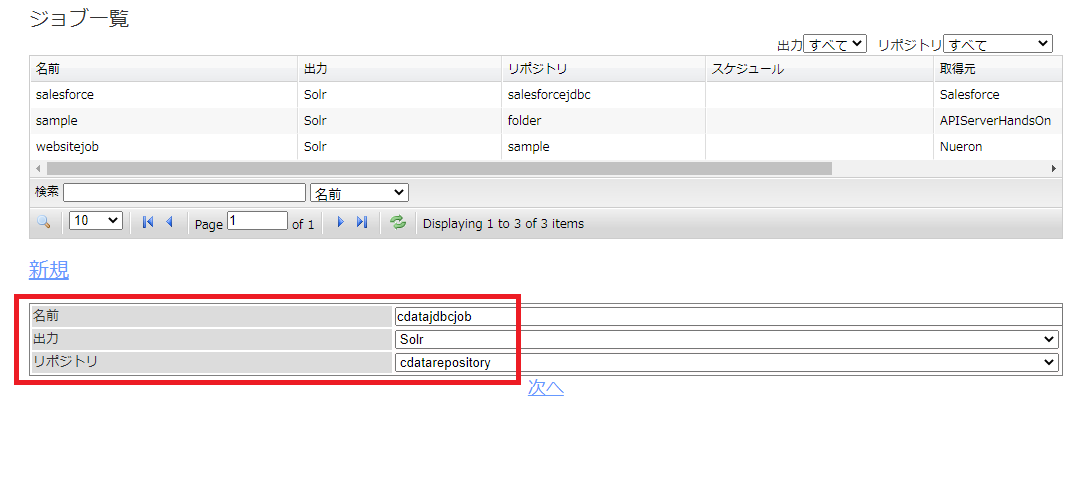
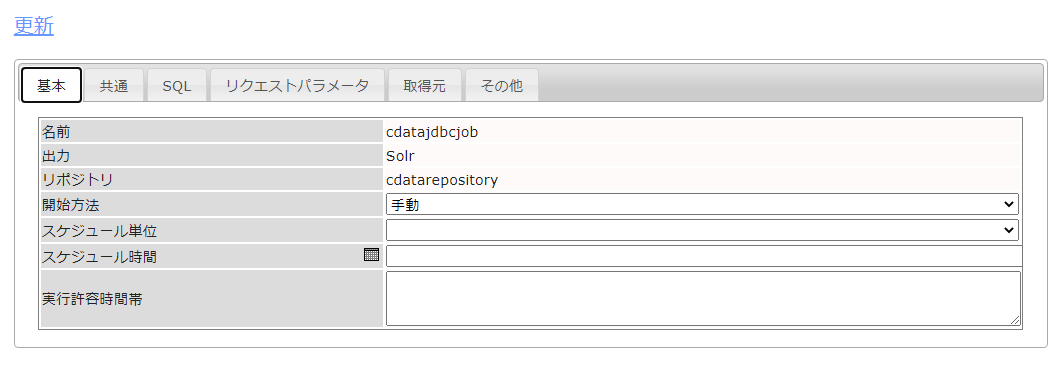
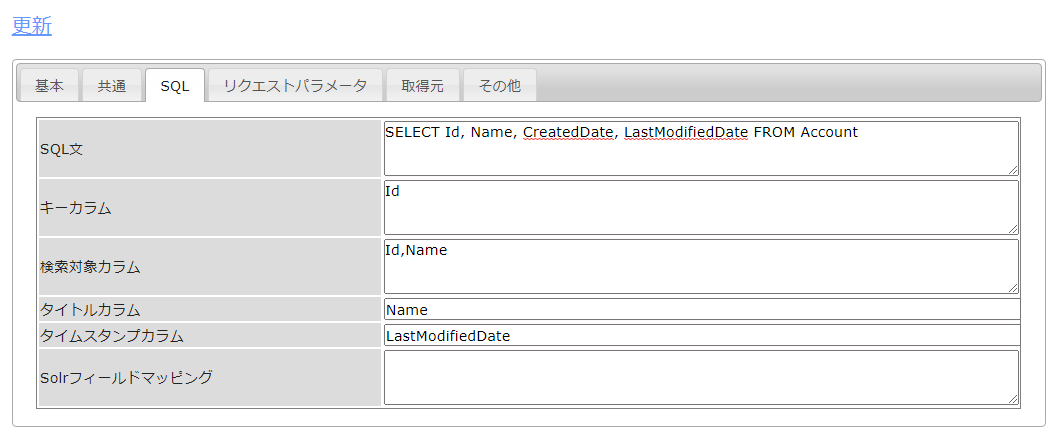
続いて、Google Sheets のどのデータをどのようにクローリングするのかをジョブで定義していきます。
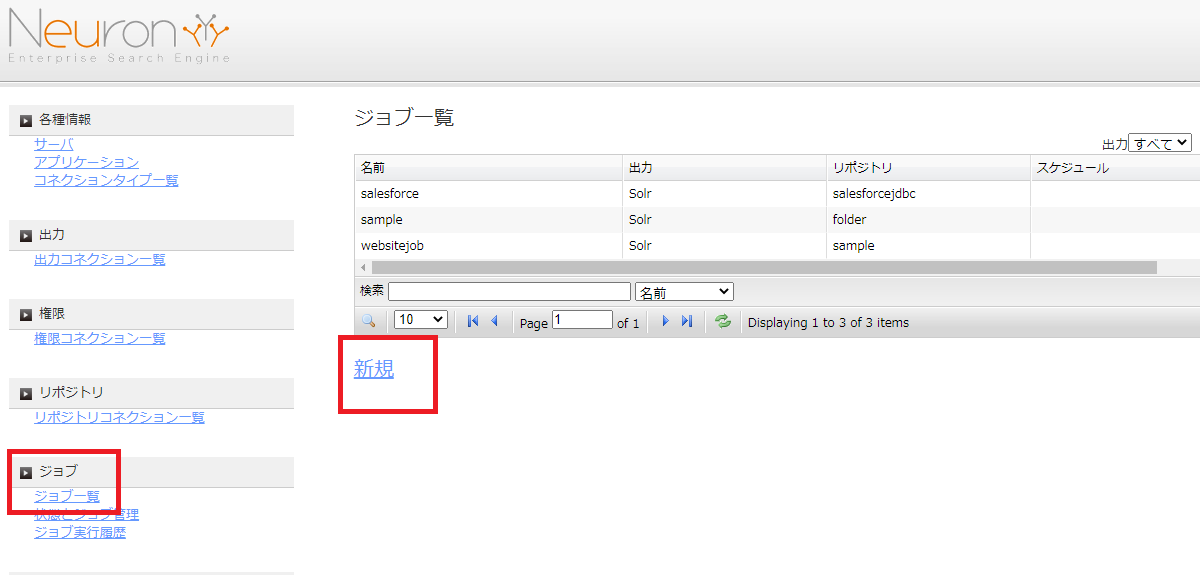
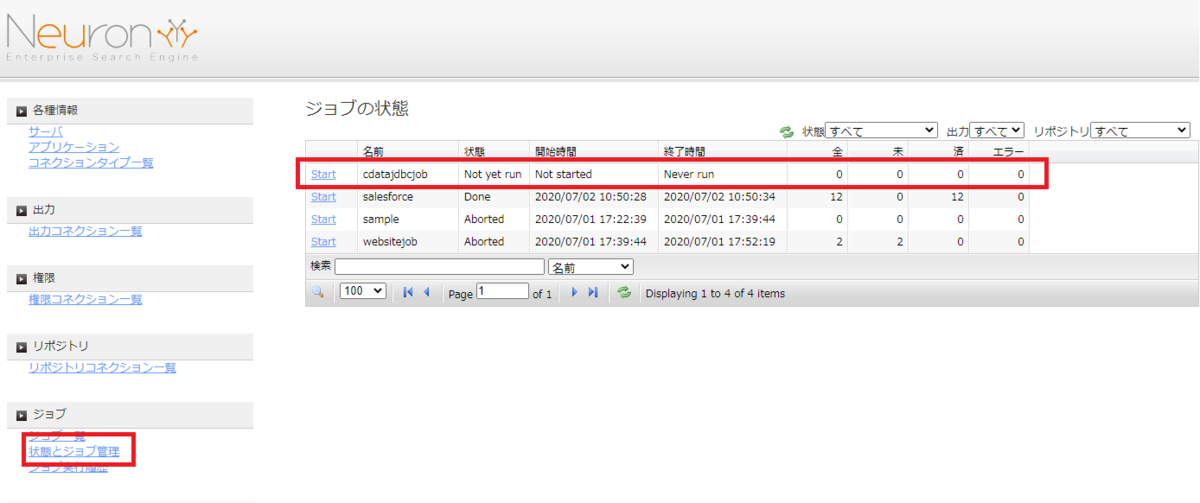
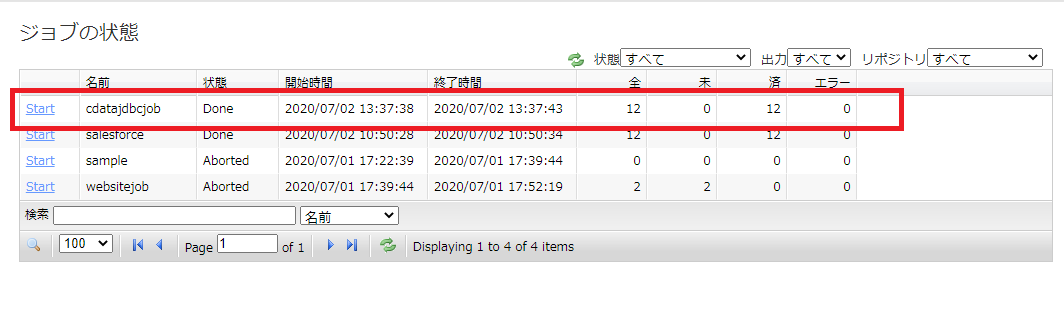
実際にNeuron で作成したジョブを実行します。[ジョブ]→[状態とジョブ管理]をクリックし、作成したジョブの[Start]をクリックします。
ジョブが正常完了すると、[Done]がステータスとして表示されます。
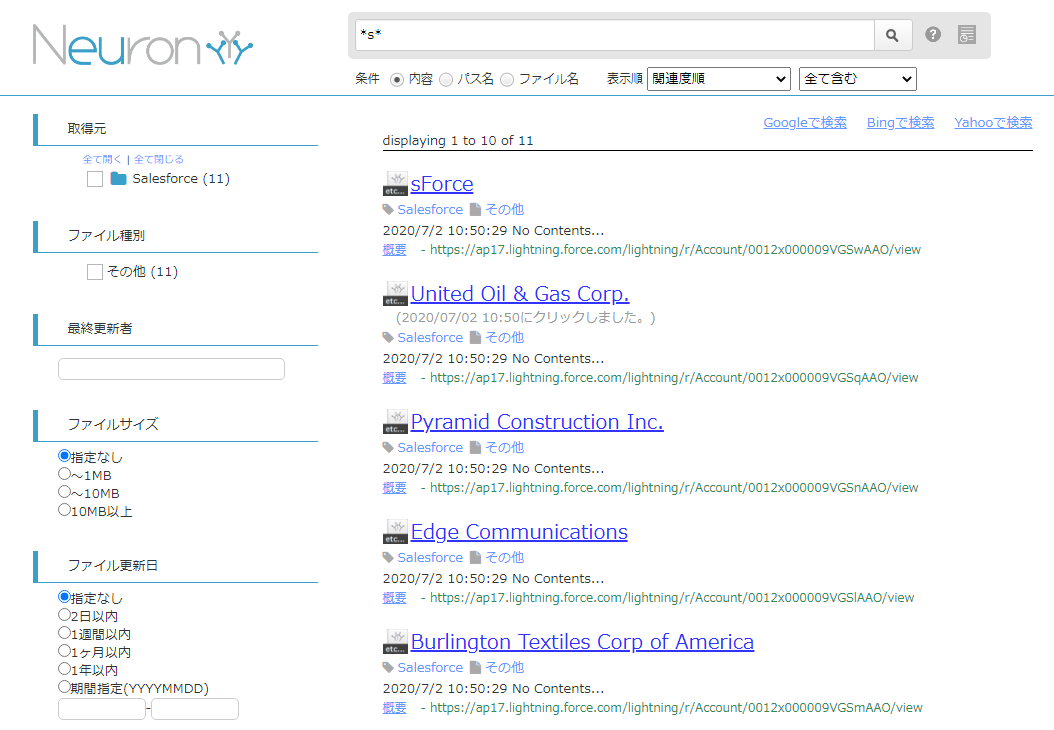
実際にNeuron 上で検索ができるか確認してみます。取得元を絞り込むこと、内容やファイル名での検索、ファイルサイズやファイル更新日の絞り込み、部分一致や全部一致で検索が可能です。 検索をかけてみると、以下のようにデータを取得できました。
CData JDBC Driver for GoogleSheets をNeuron で使うことで、Google Sheets コネクタとして機能し、簡単にデータを取得して同期することができました。ぜひ、30日の無償評価版をお試しください。