ノーコードでクラウド上のデータとの連携を実現。
詳細はこちら →Amazon Redshift ODBC Driver の30日間無償トライアルをダウンロード
30日間の無償トライアルへ製品の詳細
Amazon Redshift ODBC Driver は、ODBC 接続をサポートするさまざまなアプリケーションからAmazon Redshift データへの接続を実現するパワフルなツールです。
標準ODBC Driver インターフェースを通じて、Amazon Redshift データを読み、書き、更新。
CData


こんにちは!リードエンジニアの杉本です。
本記事では、データサイエンティスト向けのツールとして有名なIBM SPSS Modeler でCData Driver を利用し、各種クラウドサービスのデータを取り込み、予測モデル作成につなげる方法を紹介したいと思います。
IBMが提供するビジュアル・データサイエンスと機械学習(ML)のソリューションです。
https://www.ibm.com/jp-ja/products/spss-modelerSPSS Modeler はローコードで予測モデルの作成およびモデルの作成に必要なデータ加工などのプレパレーションを実施できます。今回の記事では、このSPSS Modeler にRedshift のデータを取り込んでみたいと思います。データの取得ができれば、予測モデルの作成などに自在に活用できます。
さて、今回の記事ではSPSS からRedshift に接続していきますが、このときに必要となるのがCData ODBC ドライバです。
SPSS にはODBC を経由して他サービスに接続する機能が標準提供されています。この機能とCData が提供しているODBC Drivers ラインナップを組み合わせることで、各種クラウドサービスのAPI やデータベースにシームレスにアクセスすることができるようになります。
とは言っても、説明だけではイメージできない部分もあると思うので、実際に連携を試してみましょう。
最初にCData Redshift ODBC Driver を対象のマシンにインストールします。
以下のページから30日間のトライアルがダウンロードできます。
Redshift ドライバーページインストーラーを入手後、対象のマシンでセットアップを進めていきます。
セットアップが完了すると接続設定画面が表示されるので、Redshift への認証に必要な情報を入力します。
Redshift への接続には次を設定します:
Server およびPort の値はAWS の管理コンソールで取得可能です:
あとは「接続のテスト」ボタンをクリックし、接続が成功したら、「接続ウィザード」の「OK」ボタンをクリックして保存します。
接続完了後、メタデータタブから利用できるテーブル・ビューの情報を確認できます。
ここで予めRedshift のどのオブジェクト、項目を利用するか確認しておくと良いでしょう。
それではSPSS Modeler を使ってRedshift のデータを取り込んでみましょう。
Windows のスタートメニューから「IBM SPSS Modeler Subscription」を立ち上げて、新しいストリームを作成します。
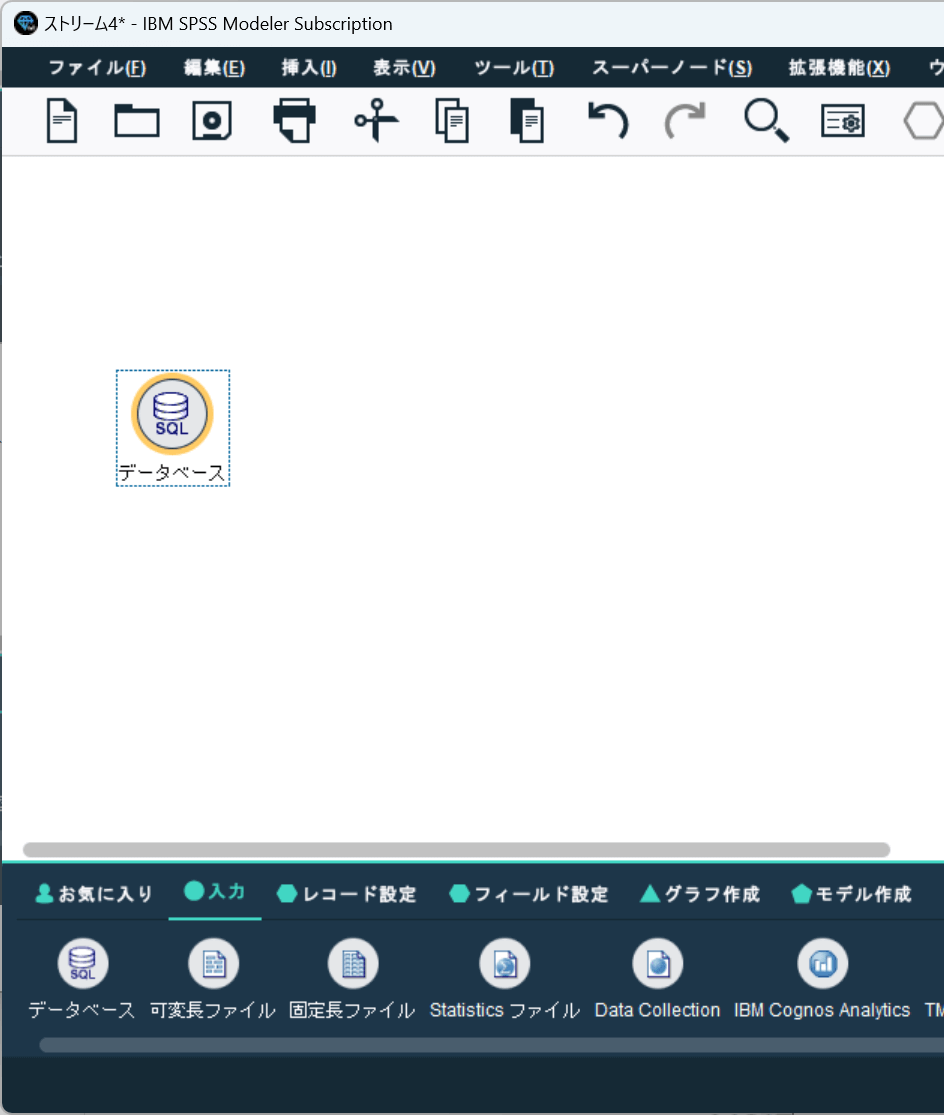
まず「入力」タブにある「データベース」をストリーム上に配置します。
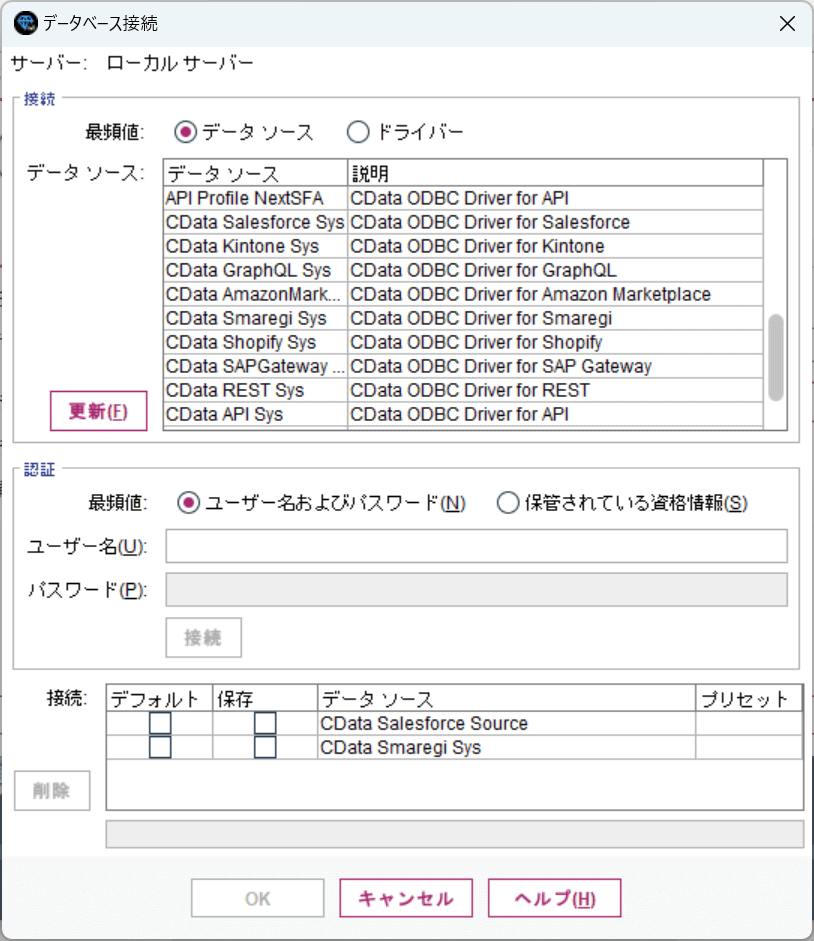
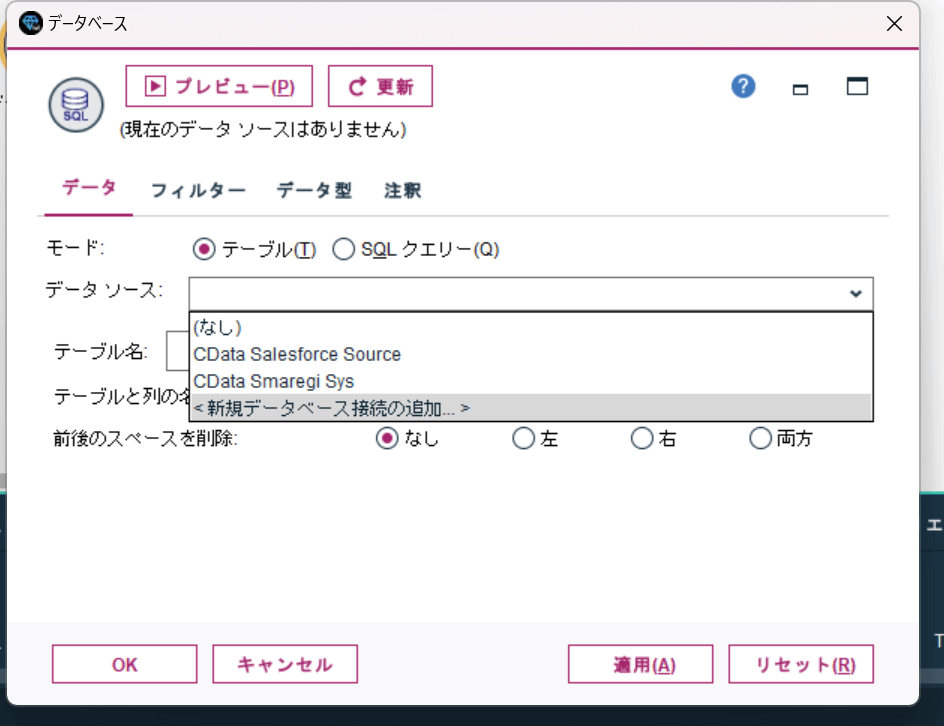
配置したアイコンをダブルクリックするとデータベースの接続設定画面が出てくるので、「データソース」から「新規データベース接続の追加」をクリックします。
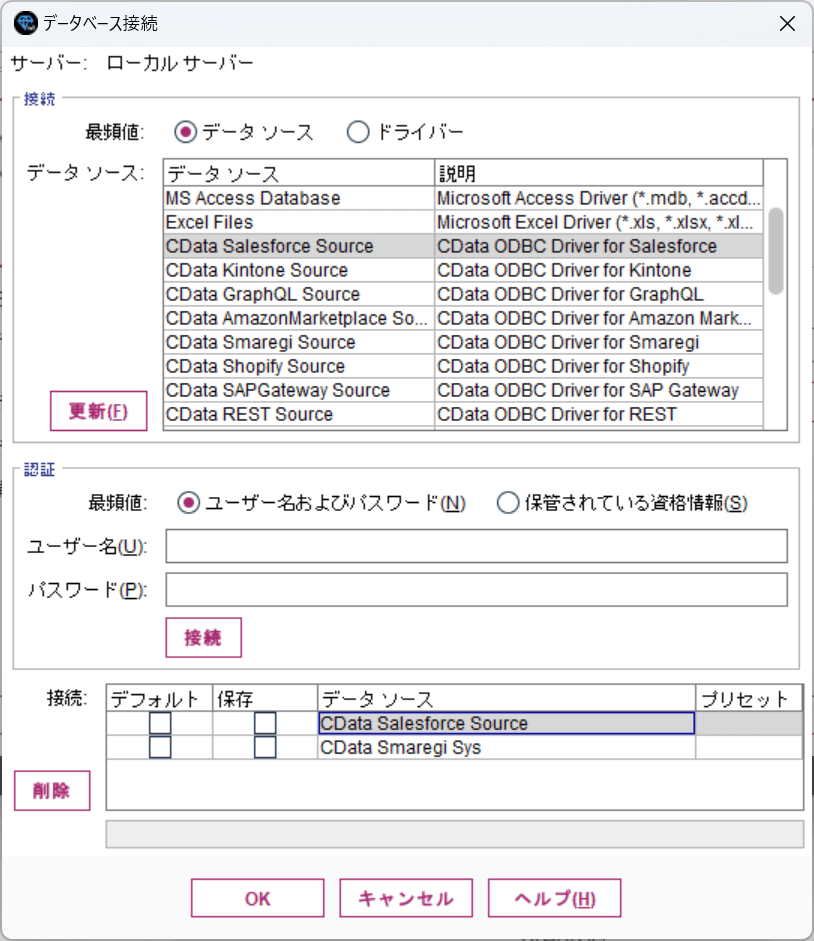
すると以下のようにODBC DSNの一覧が表示されるので、先程構成したRedshift のDSNを選択して、「接続」をクリックしましょう。
ユーザー名・パスワードなどの認証情報は事前に入力してあるので、空白のままで構いません。これでRedshift への接続を確立できます。
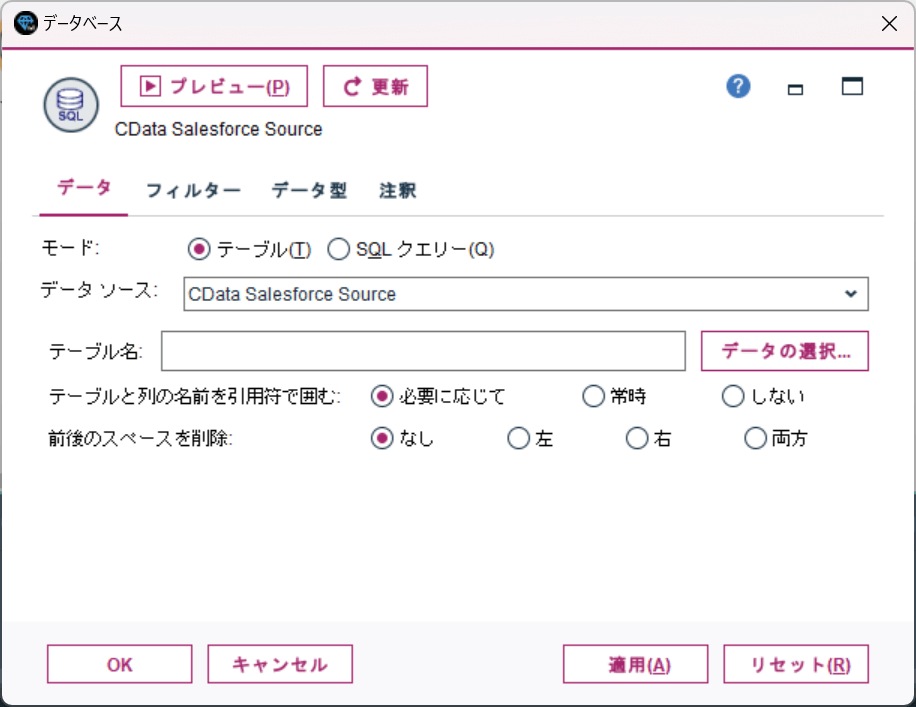
接続を追加したら、どんなデータを取り込むのか、テーブルまたはSQLクエリーで設定します。
とりあえず手軽に取り込めるテーブル名での指定を行ってみます。「データの選択」をクリックします。
表示されたテーブル・ビューの一覧から取り込みたい対象のテーブルを選択しましょう。
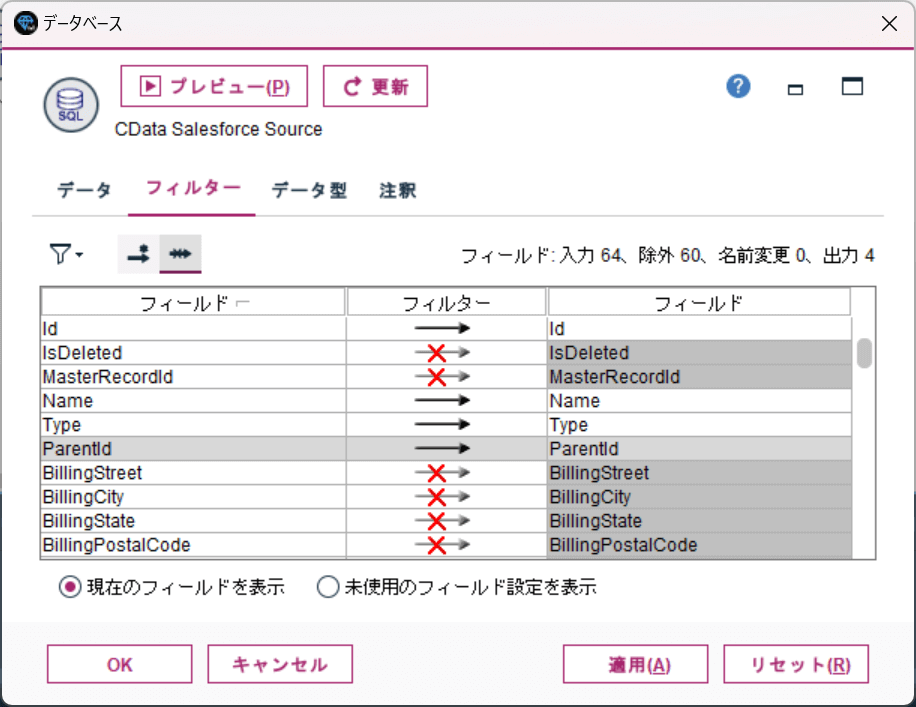
あとはフィルター条件として、どの項目を取り込むかどうかという設定や、
モデル作成の際に利用するデータ型やロールを設定すれば、データ取得の準備はOKです。
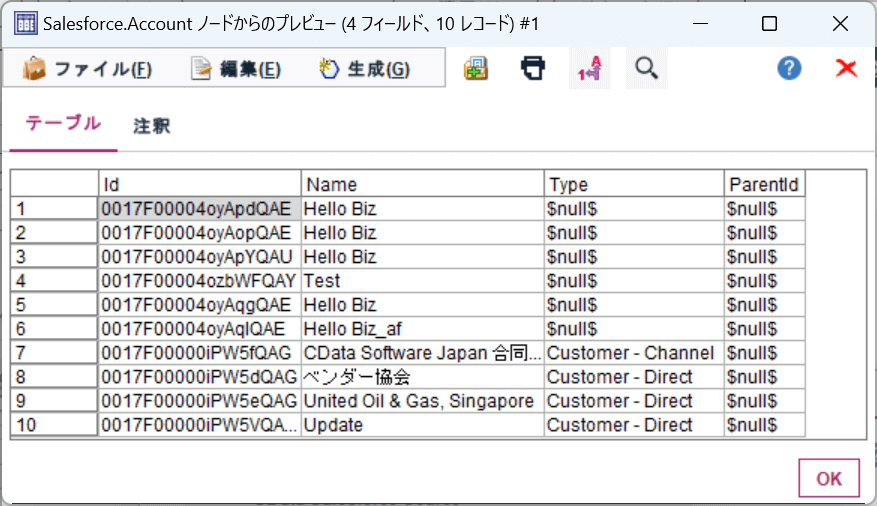
データのプレビューを確認すると、以下のようにRedshift のデータを確認できました。
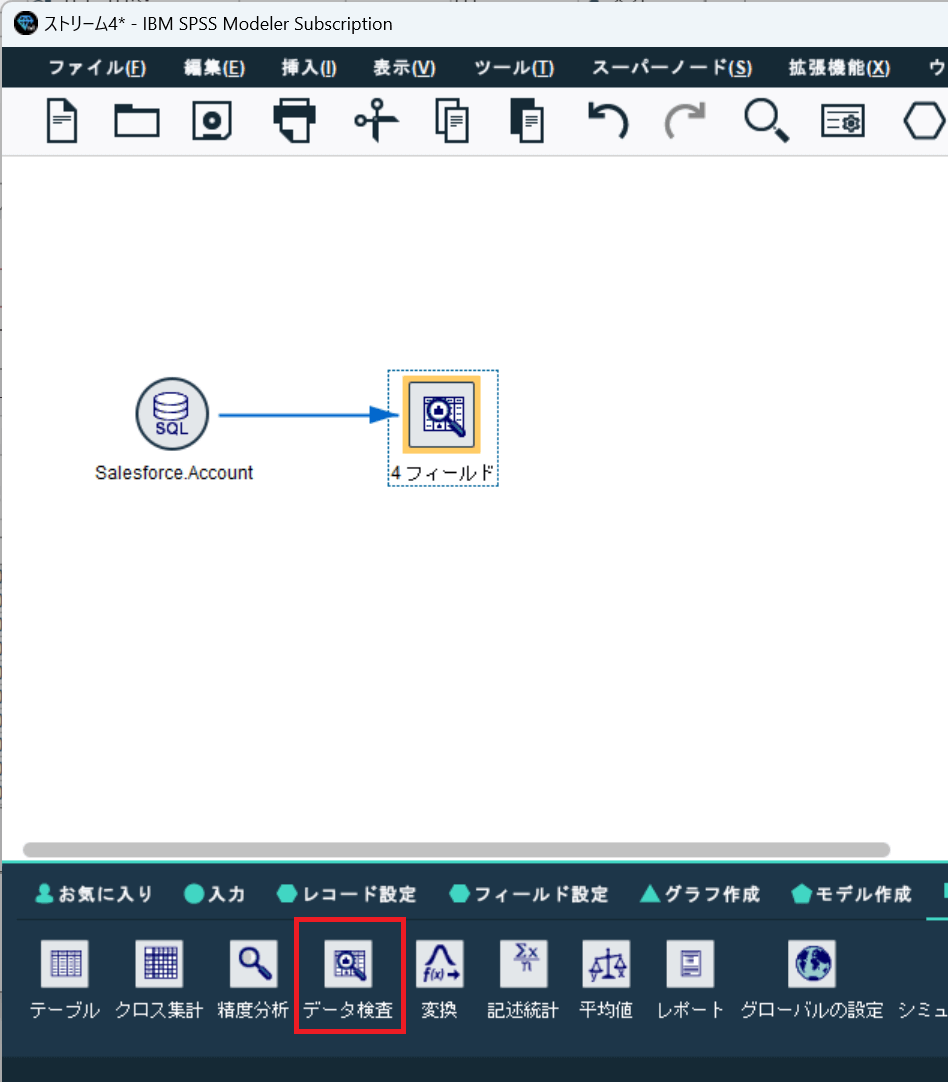
せっかくなので、「データ検査」を実行してデータの傾向も確認してみましょう。
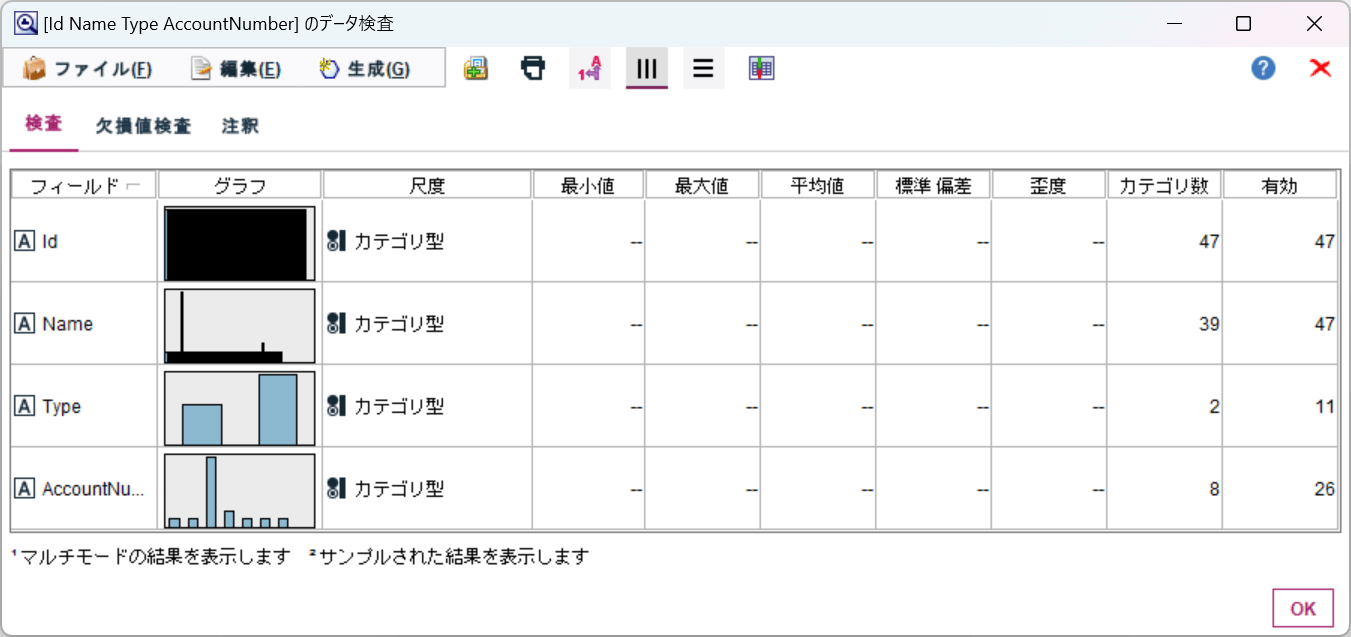
以下のように各項目のデータの最小・最大・平均、有効な値かどうかなどが確認できます。
このように、とてもシンプルな手順でRedshift のデータをSPSS Modeler に取り込むことができました。
これで、予測モデル作成などより複雑なタスクにRedshift データを簡単に活用できます。
このようにCData ODBC ドライバと併用することで、270を超えるSaaS、RDB、NoSQL データをSPSS Modeler からコーディングなしで扱うことができます。30日の無償評価版が利用できますので、ぜひ自社で使っているクラウドサービスやNoSQL と合わせて活用してみてください。
CData ODBC ドライバは日本のユーザー向けに、UI の日本語化、ドキュメントの日本語化、日本語でのテクニカルサポートを提供しています。