ノーコードでクラウド上のデータとの連携を実現。
詳細はこちら →CData


こんにちは!プロダクトスペシャリストの宮本です。
CData Sync は、400種類以上のSaaS / DB のデータを各種DB・データウェアハウスにノーコードで統合可能なデータパイプラインツールです。CData Sync では、DB / DWH だけでなくSalesforce をはじめとする一部SaaS をデータの転送先としてサポートしているため、いわゆるリバースETL 構成のデータパイプラインを構築できます。
本記事では、Redshift とSalesforce のデータをSnowflake に統合、リードスコアを計算・付加した後にSalesforce に書き戻す、というリバースETL 構成のパイプラインを作っていきます。
CData Sync は、レポーティング・ダッシュボード、機械学習・AI などで使えるよう、社内のデータを一か所に統合して管理できるデータ基盤をノーコードで構築できるETL ツールで、以下の特徴を持っています。
ETL の逆、いわゆるデータウェアハウスからSaaS へデータを転送することを指します。アプリ間連携のようなEAI とは異なり、ETL のようにバッチ処理での連携を行います。例えばSalesforce のデータを元にデータウェアハウス内で集計・予測してから書き戻したい場合、①Salesforce → データウェアハウスで連携、②データウェアハウスで変換されたデータをSalesforce に書き戻し、と2つのポイントがありますが、後者の構成がリバースETL に当たります。
それでは、Redshift とSalesforce のデータを統合して書き戻すための具体的な設定手順を説明していきます。
Redshift とSalesforce の情報を一度Snowflake に統合、統合したデータを使ってリードをスコアリングし、その結果をSalesforce に書き戻します。 リバースETL のデータソースとなるDB としてSnowflake を使い、全体のデータの流れは、
Salesforce (Lead)+Redshift → Snowflake(スコアリング)→ Salesforce(Lead)となります。なお、Salesforce のLead オブジェクトにはスコアリング結果を格納するカスタム項目を事前に作成しておきます。
はじめに、Salesforce とRedshift のデータをSnowflake に転送するための設定を行います。
CData Sync のブラウザ管理コンソールにログインします。CData Sync のインストールをまだ行っていない方は本記事の製品リンクからCData Sync をクリックして、30日の無償トライアルとしてCData Sync をインストールしてください。インストール後にCData Sync が起動して、ブラウザ設定画面が開きます。
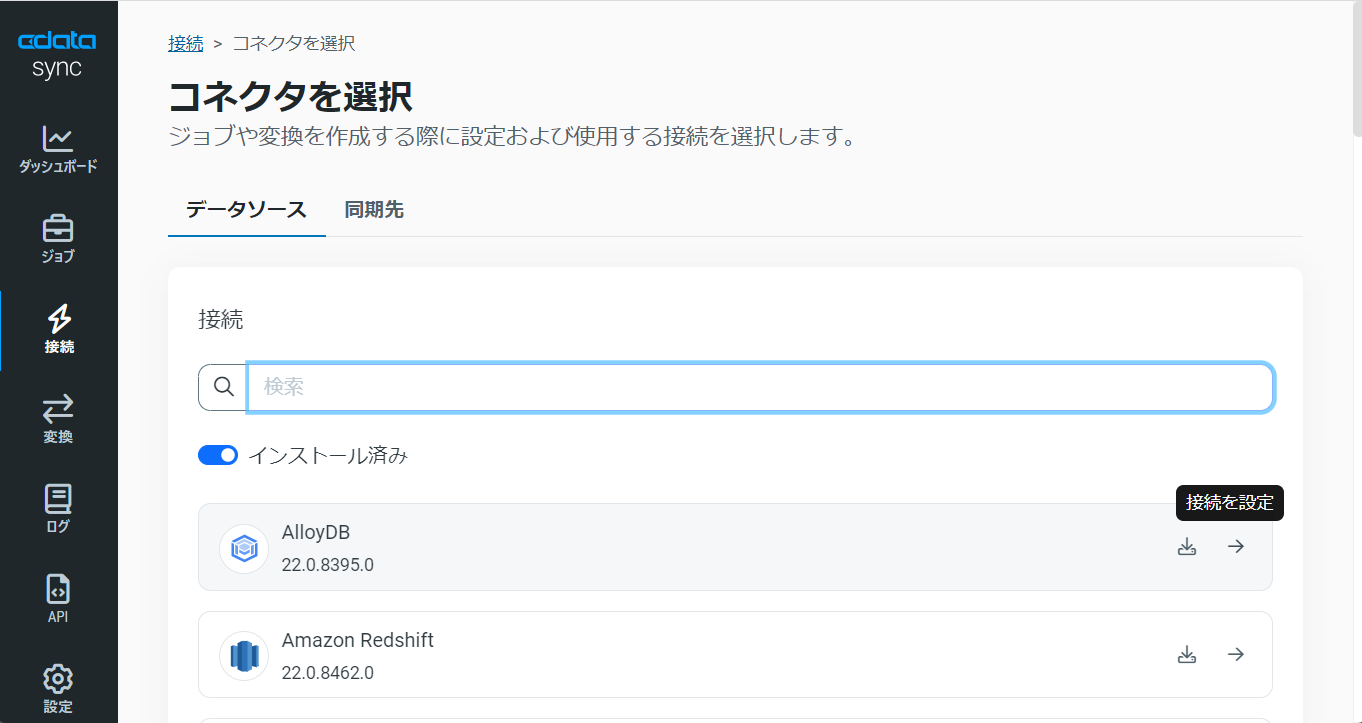
それでは、データソースとしてRedshift を設定していきましょう。左の[接続]タブをクリックします。
Redshift への接続には次を設定します:
Server およびPort の値はAWS の管理コンソールで取得可能です:
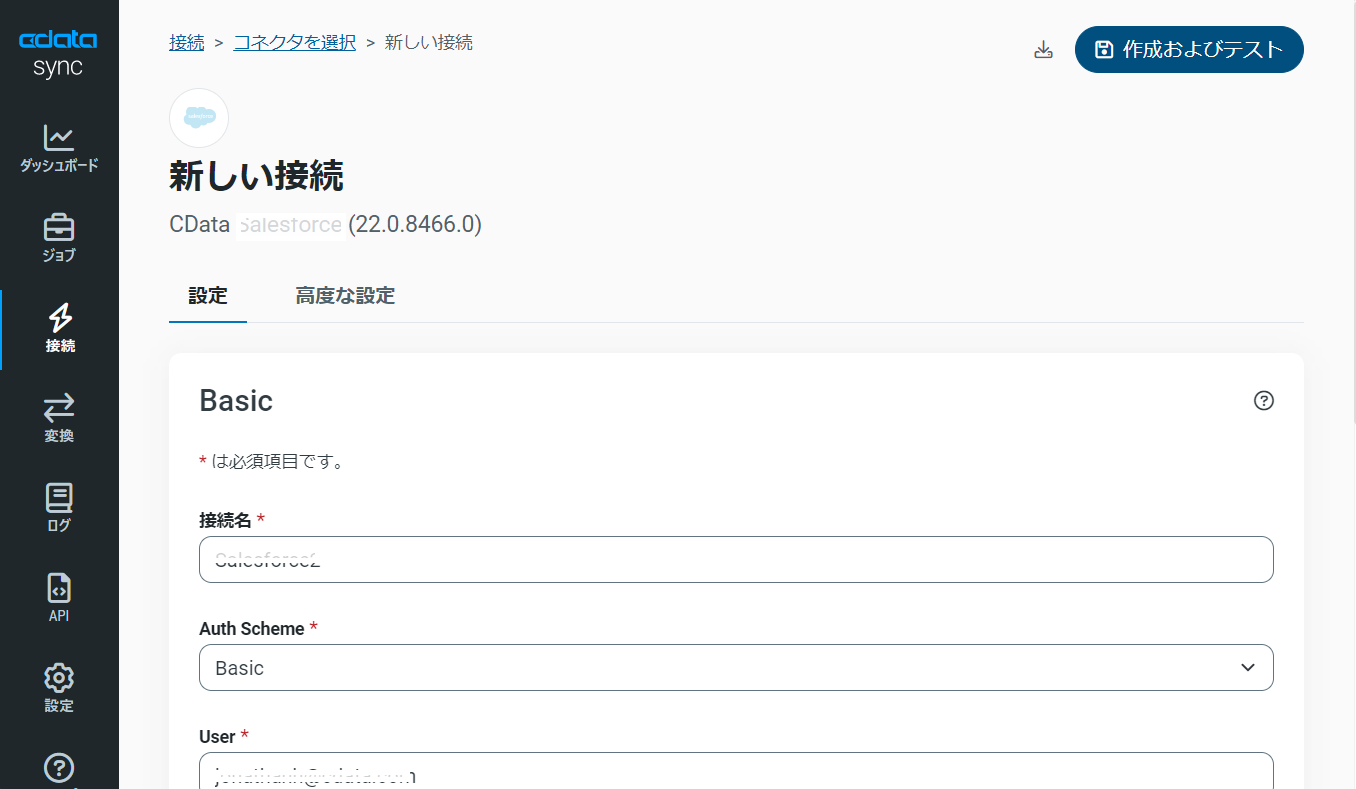
データソースとしてSalesforce を設定します。接続プロパティまでの設定方法は基本的にRedshift と同じです。
Salesforce への接続には通常のログインの他、OAuth やSSO を利用できます。ログイン方式では、ユーザー名、パスワード、セキュリティトークンを使って接続します。Salesforce セキュリティトークンの取得についてはこちらの記事をご確認ください。
ユーザー名、パスワードを使用しない、またはできない場合、OAuth 認証を利用できます。
SSO (シングルサインオン) は、SSOProperties、SSOLoginUrl、TokenUrl プロパティを設定することでID プロバイダー経由で利用できます。詳細はヘルプドキュメントの「はじめに」を参照してください。
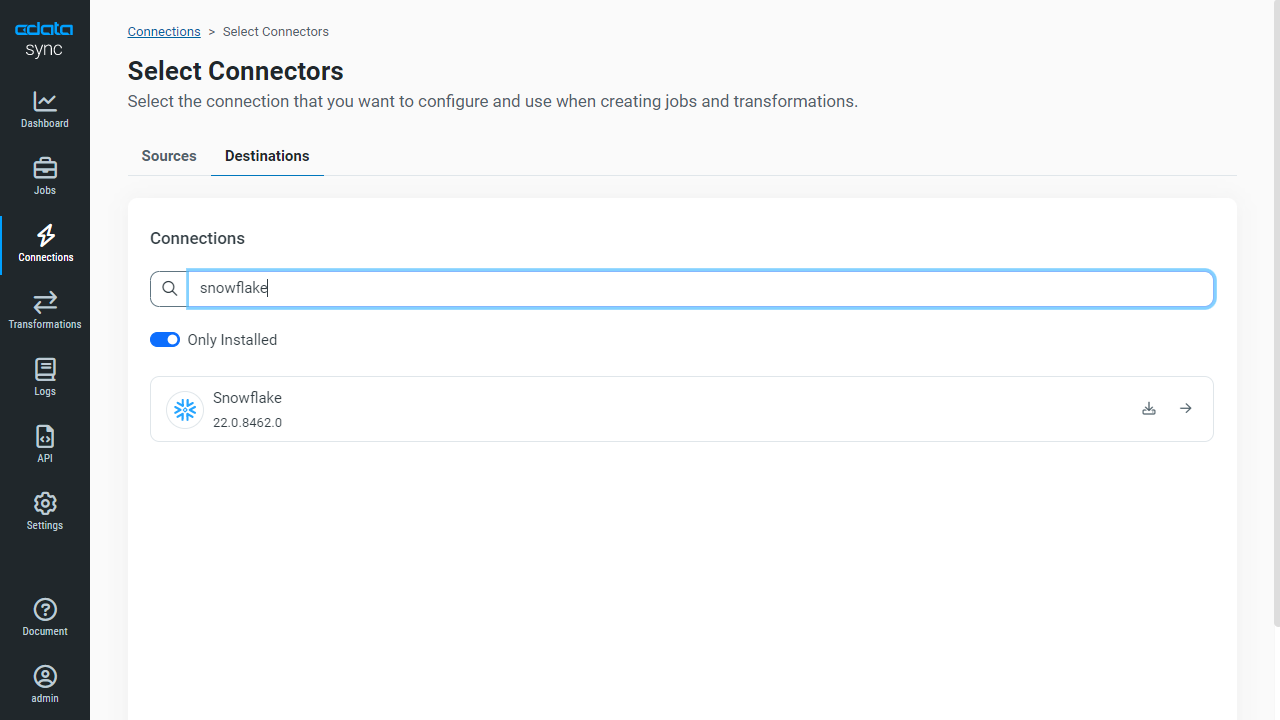
次に、Snowflake への接続を設定します。同じく[接続]タブを開きます。
CData Sync では、データ転送をジョブ単位で設定します。ジョブは、例えばSalesforce → Snowflake といった1データソース対1転送先の単位で設定し、データソースが持つ複数のテーブルを含むことができます。データ転送ジョブを設定するには、[ジョブ]タブに進み、[+ジョブを追加]ボタンをクリックします。
Salesforce のすべてのオブジェクト / テーブルをデータ転送するには、[種類]で[すべて同期]を選択して、[ジョブを追加]ボタンで確定します。
作成したジョブ画面で、右上の[▷実行]ボタンをクリックするだけで、全Salesforce テーブルのSnowflake への同期を行うことができます。
Salesforce から特定のオブジェクト / テーブルを選択してデータ転送を行うことが可能です。[種類]では[標準(個別設定)]を選んでください。
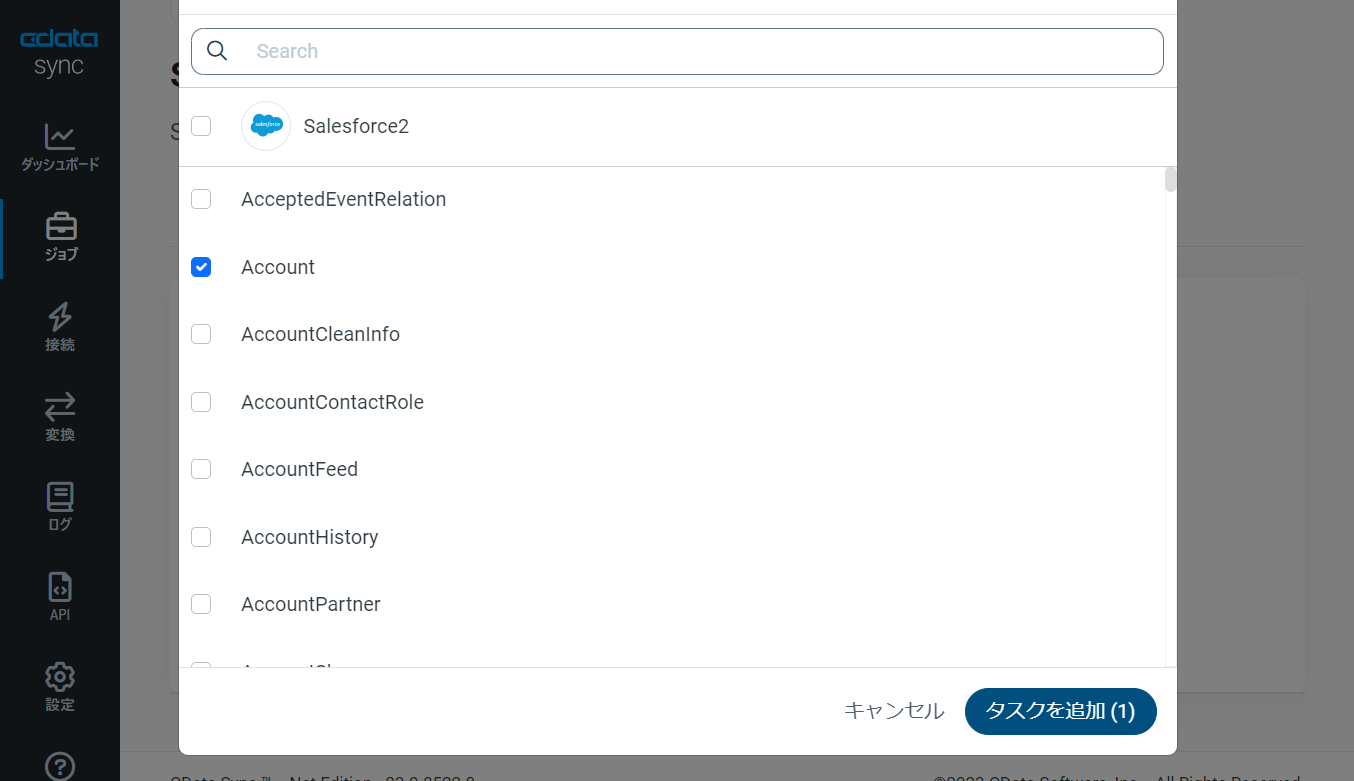
次に[ジョブ]画面で、[タスク]タブをクリックし、[タスクを追加]ボタンをクリックします。 
するとCData Sync で利用可能なオブジェクト / テーブルのリストが表示されるので、データ転送を行うオブジェクトにチェックを付けます(複数選択可)。[ジョブを追加]ボタンで確定します。
作成したジョブ画面で、[▷実行]ボタンをクリックして(もしくは各タスク毎の実行ボタンを押して)、データ転送ジョブを実行します。 
このようにとても簡単にSalesforce からSnowflake への同期を行うことができました。
Snowflake に転送されたテーブルを見てみると、無事にSalesforce のデータが転送されていることが確認できます。スコアリング結果を格納するLeadScore_c(カスタム項目)にはまだ何もデータが入っていませんので、ここにRedshift のデータを統合したリードスコアリングの計算結果を追加します。
同じ手順で、Redshift のお好みのデータをSnowflake に転送できます。今回はOrders を使用しました。
それでは、Salesforce のリードをスコアリングしてSnowflake に反映しましょう。このときにRedshift のOrders データを統合して使います。
CData Sync ではSalesforce とRedshift 以外にも400種類以上のデータソースをサポートしているので、スコアリングに必要なデータ(Webサイト上のアクティビティやメール開封率、ダウンロード履歴など)が他にあれば追加してみてください。
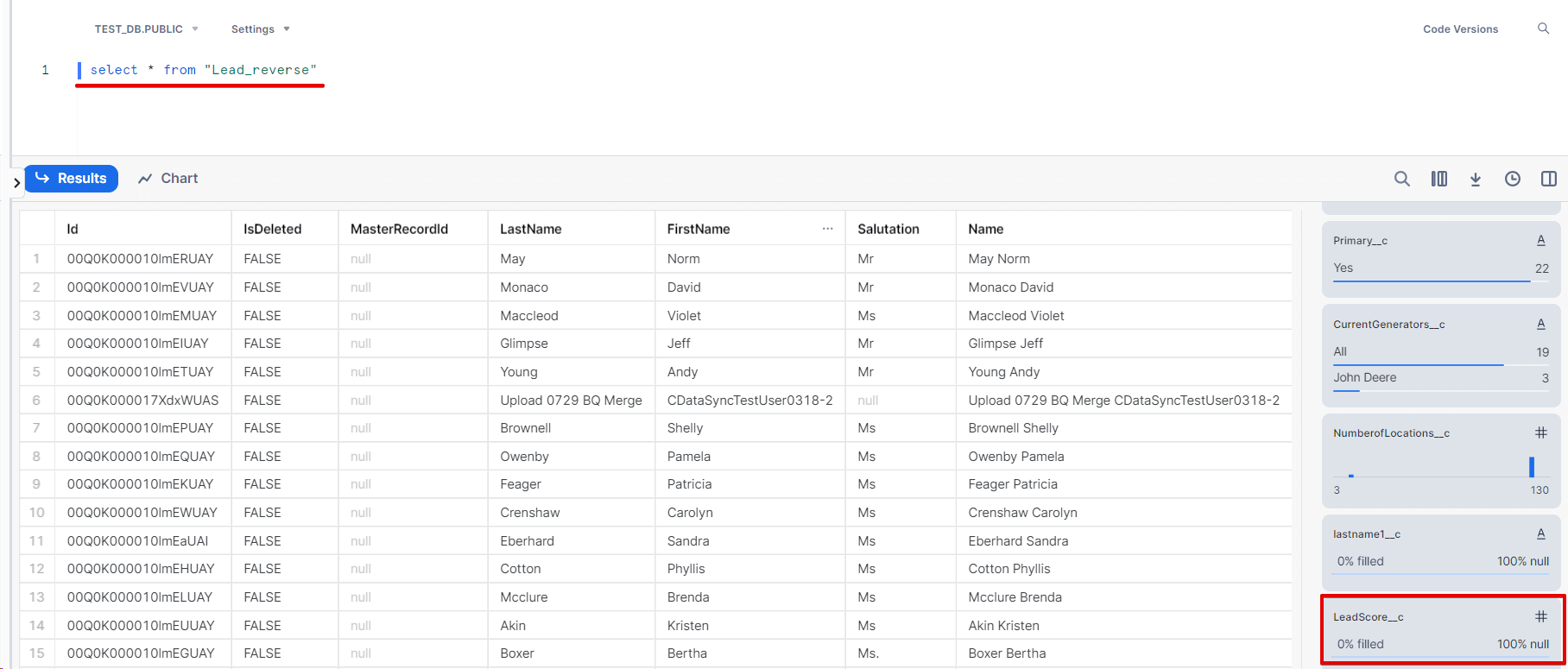
それでは、Snowflake のLead_reverse テーブルのLeadScore_c を参照してみましょう。
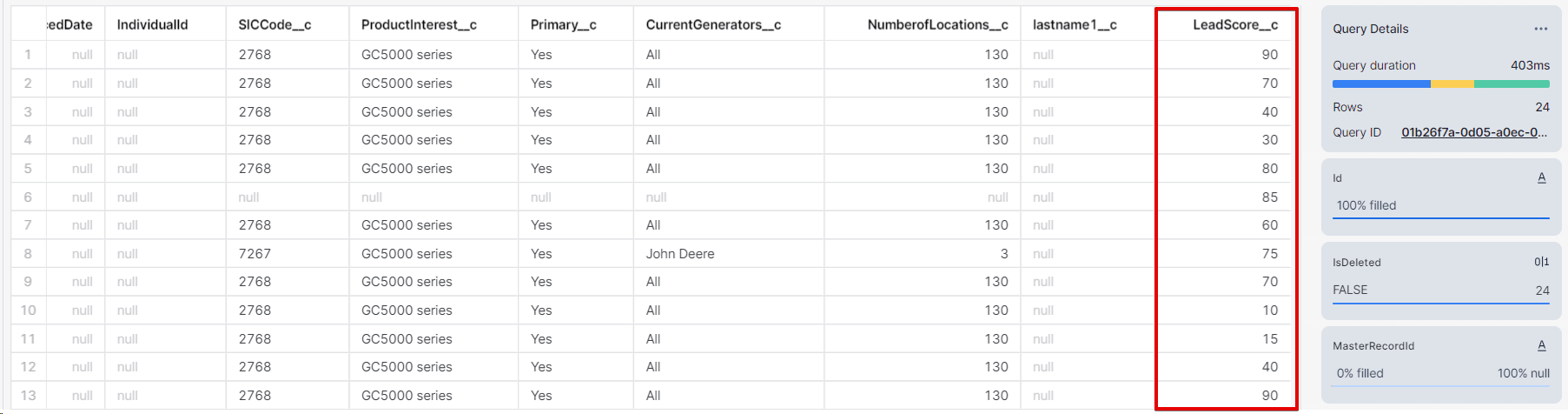
本記事ではリードスコアリングの方法は省きますが、Snowflake 上でSalesforce とRedshift のデータを使ってスコアリングした結果は以下のようにLeadScore_c カラムに追加しています。
この更新されたリードデータを、元のリードデータを持つSalesforce に書き戻します。
書き戻しを行うには、Snowflake からSalesforce へのジョブを作成する必要があります。ただし、作成方法はデータソースと同期先に注意するだけでほとんど同じです。
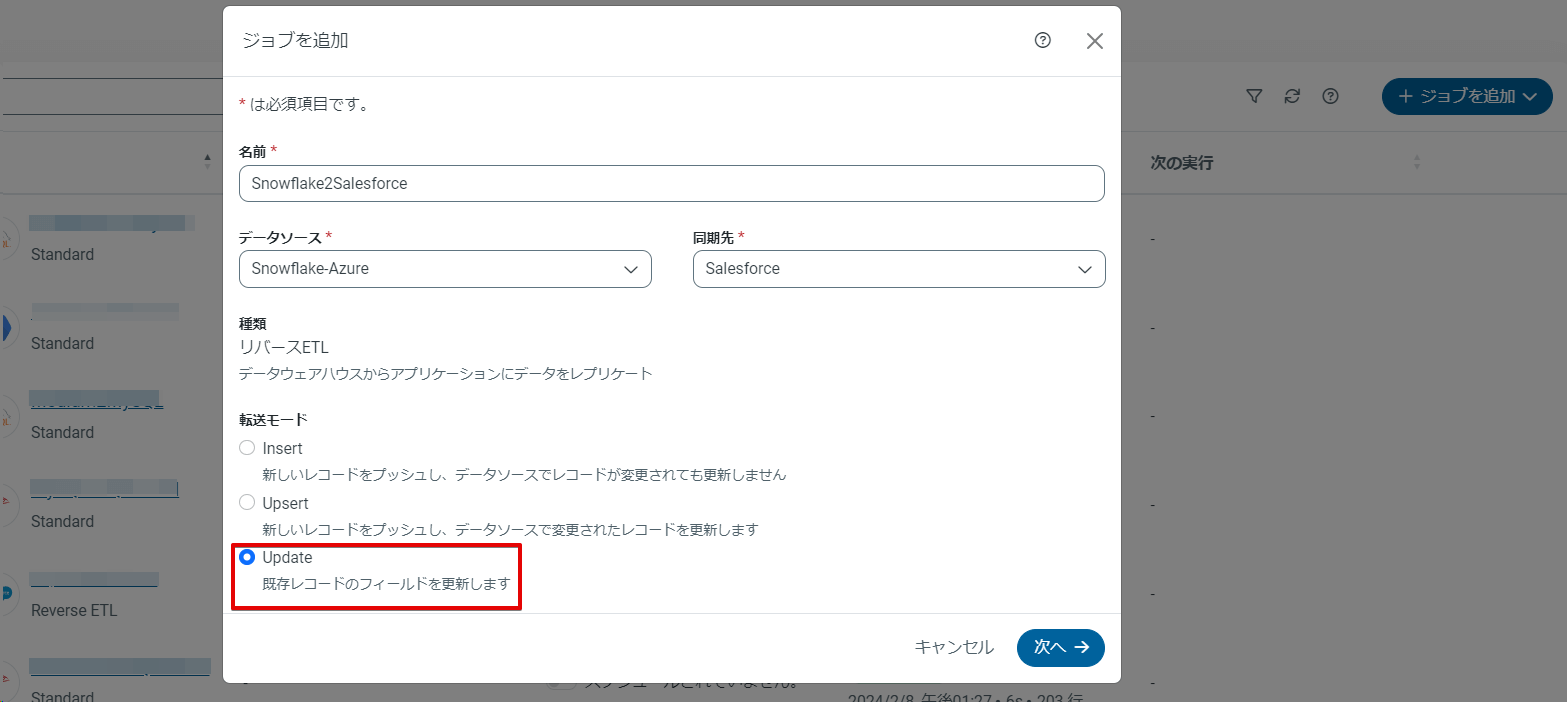
では、ジョブを追加ボタンをクリックしてジョブを作成していきます。
※連携方法は、 Insert、Upsert、Update の3パターンから選択可能です。Upsertの場合は、Salesforce で外部ID として登録している項目のみKey として使用可能
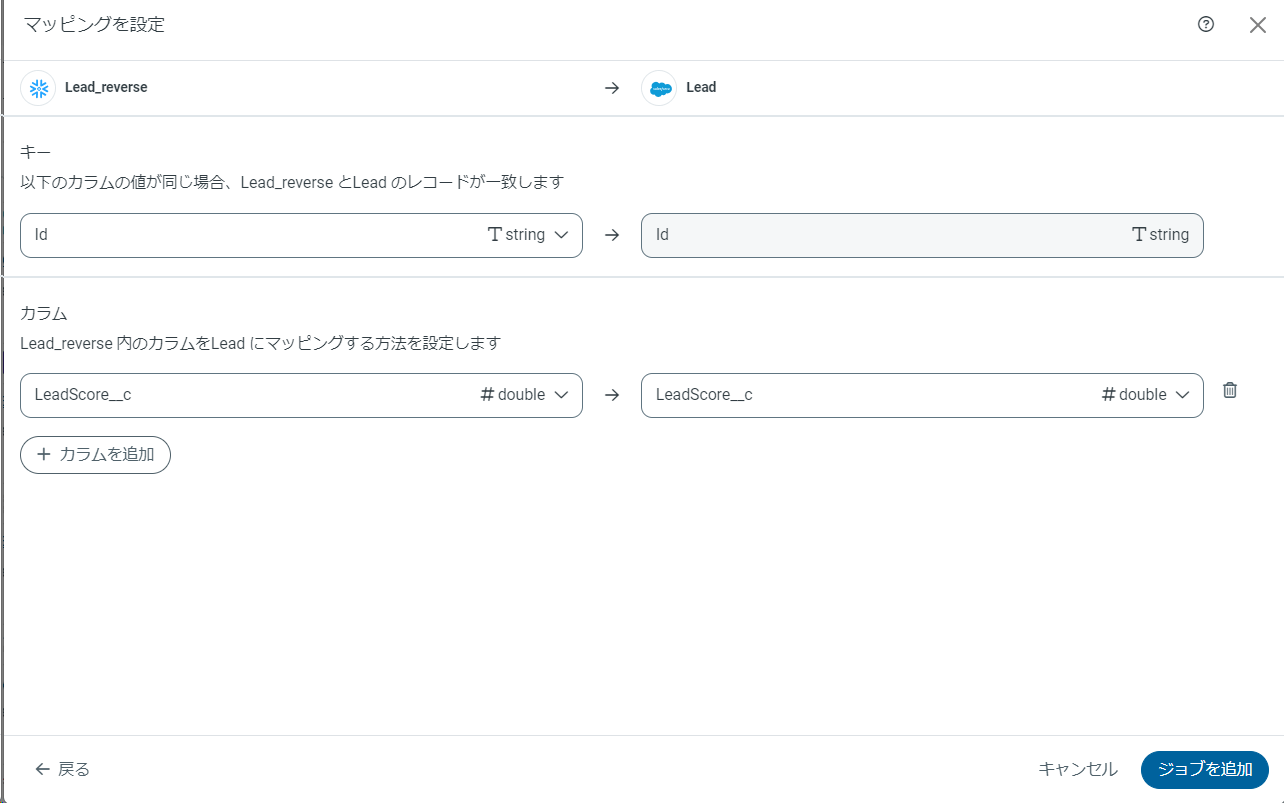
ここでテーブル同士を紐づけます。
次にどの項目をキーにするか、またどのカラム同士をマッピングするかを指定します。今回は LeadScore_c 同士でマッピングしました。
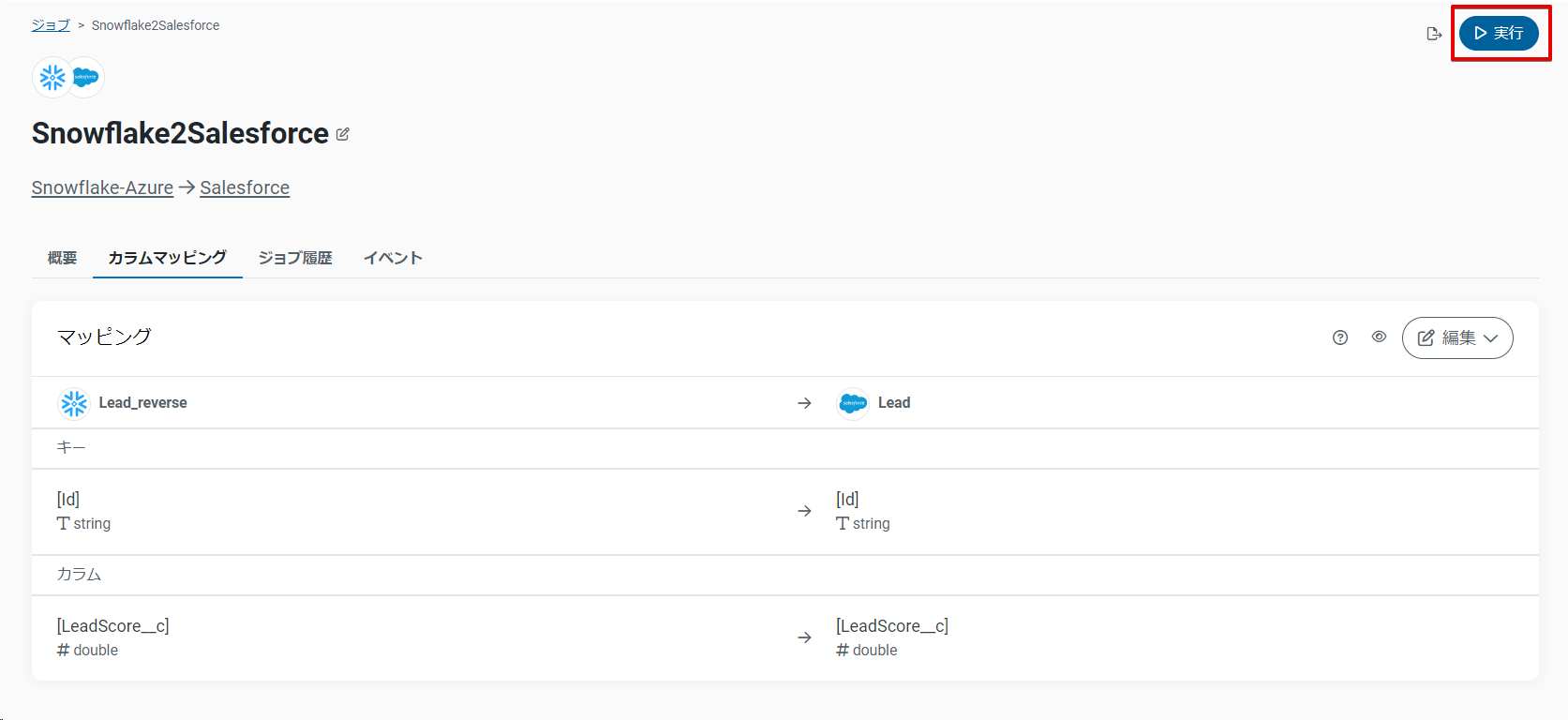
設定は以上で、あとは右上の実行ボタンをクリックするだけです。※運用時はスケジュール設定を行ってださい。
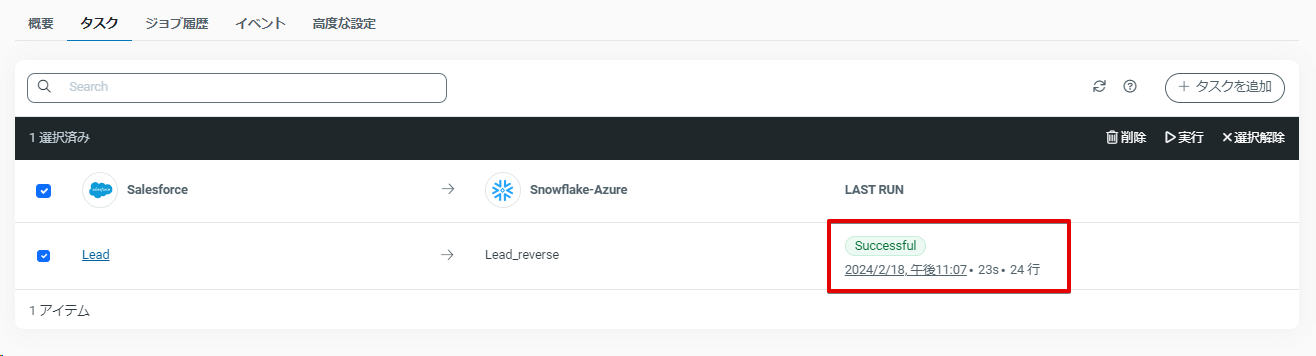
実行が完了すると、ステータスや更新した行数が表示されます。
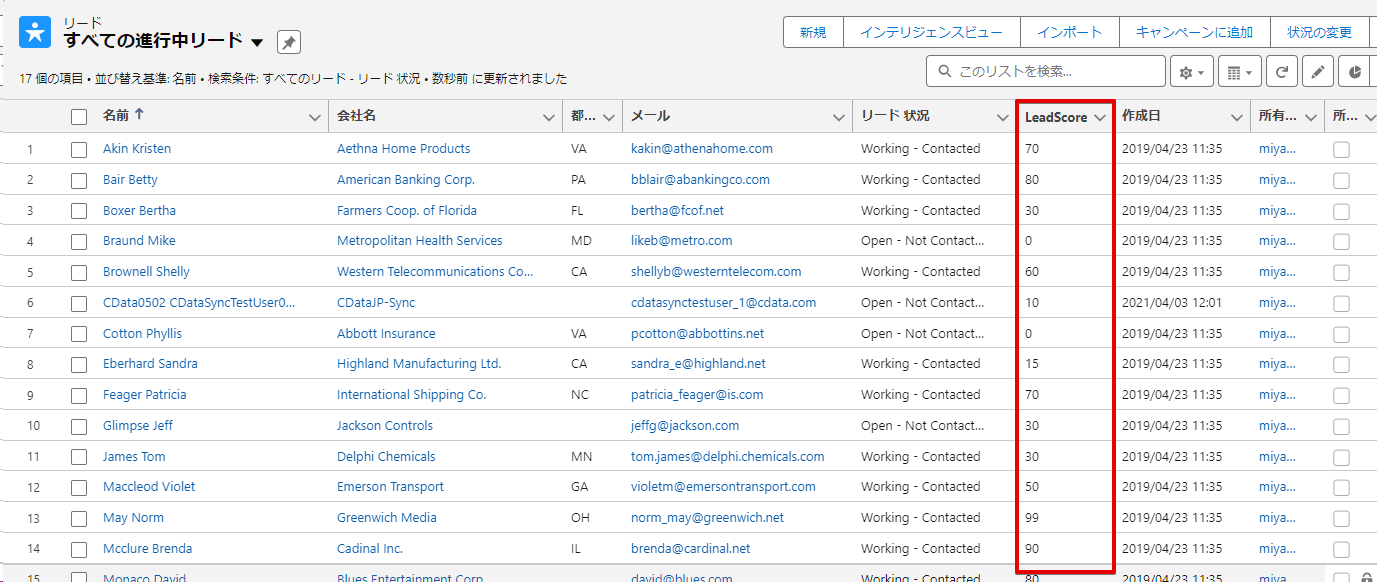
では、最後に Salesforce のLeadオブジェクトを見てみましょう。LeadScore 列にSnowflake でスコアリングした結果が取り込まれました!
このように、Salesforce とRedshift のデータを統合して書き戻すリバースETL のような複雑に思える構成でも、CData Sync ならノーコードで簡単に実現できます。
リバースETL にはリードスコアリングの他、マスタデータとの連携やWeb 解析ツールが持つユーザーアクティビティとの連携など、幅広いユースケースがあります。30日間の無償トライアルで、リバースETL パイプラインの構築を手軽にお試しください。
日本のユーザー向けにCData Sync は、UI の日本語化、ドキュメントの日本語化、日本語でのテクニカルサポートを提供しています。
もっとユースケースが知りたい!という方は、CData Sync の 導入事例を併せてご覧ください。